




-
🍀Yolov5网络结构
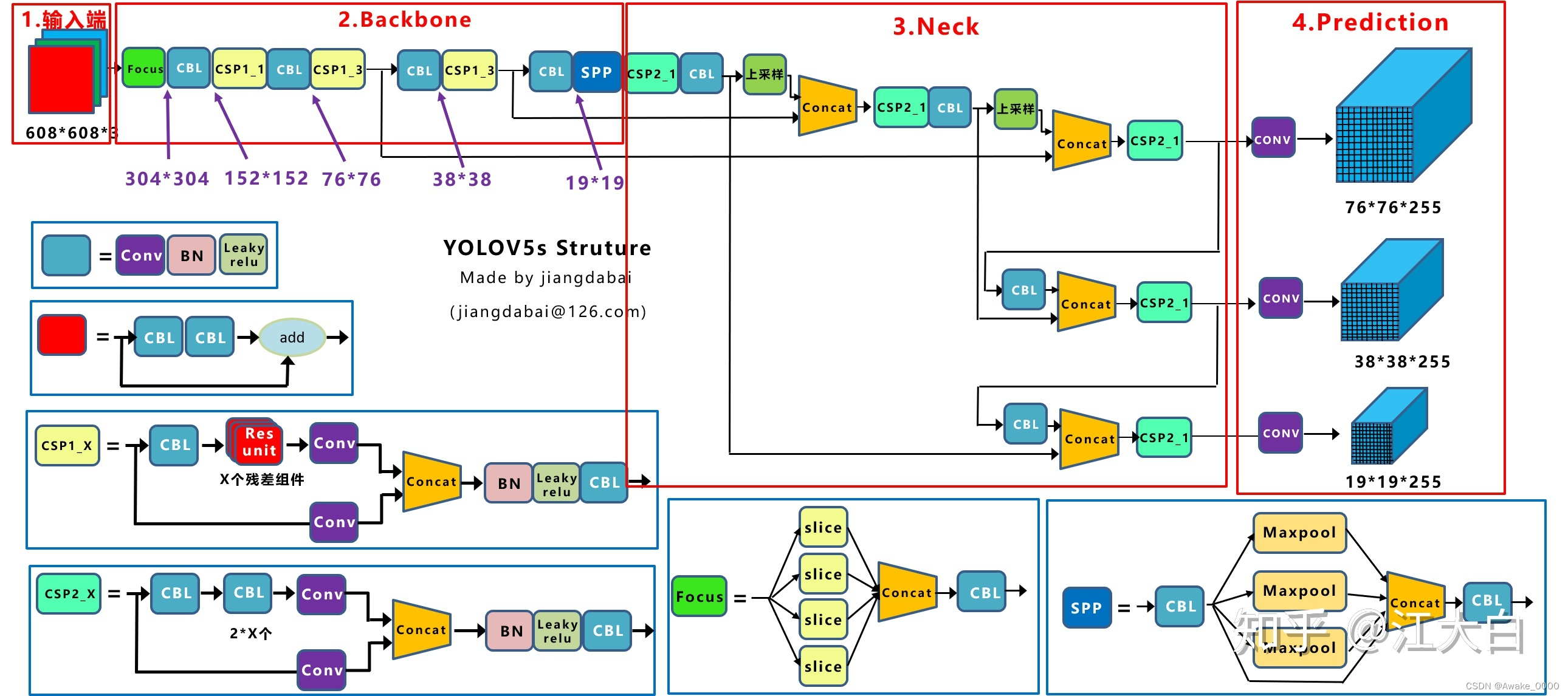
-
🦄各结构原理概念:
1.输入端:mosaic数据增强,自适应锚框计算,自适应图片缩放
Mosaic数据增强:将多张图片按一定比例组合成一张图片,在更小范围识别目标

自适应锚框计算:
yolov5针对不同的数据集,都会有预设定长宽的锚框,在训练时,以真实的边框位置相对于预设边框的偏移来构建(也就是我们打下的标签)训练样本。 这就相当于,预设边框先大致在可能的位置“框“出来目标,然后再在这些预设边框的基础上进行调整。
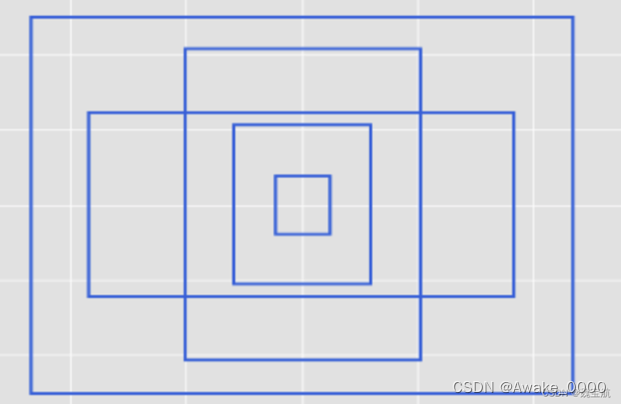
自适应图片缩放:
允许模型处理不同尺寸的输入图像,同时保持图像的比例和尽可能少的失真(该功能在模型推理阶段执行)

2.Backbone:focus结构,CSP结构,SPPF结构
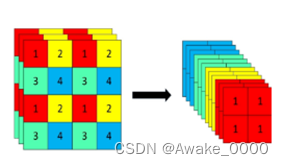
Focus结构:
对输入图片进行切片操作, 即每隔一个像素取一个值, W和H信息集中到通道空间,输入通道扩充了4倍,再进行卷积得到二倍下采样特征图(在YOLOv5-7.0版本中,Focus层可能已经被6×6卷积层所替代)
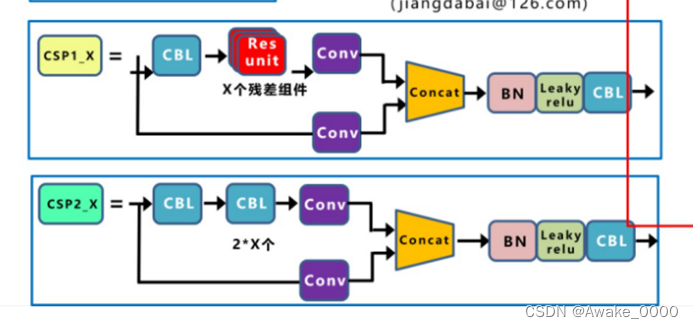
CSP结构:
将输入特征分为两个分支,并进行特定的操作来防止梯度消失, 旨在提高模型的特征表示能力,进而提升模型的准确性和泛化能力
SPPF结构:
串行堆叠多个最大池化层来实现局部特征和全局特征的融合, 能将任意大小的特征图转换为固定大小的特征向量,使模型适应不同尺寸的输入

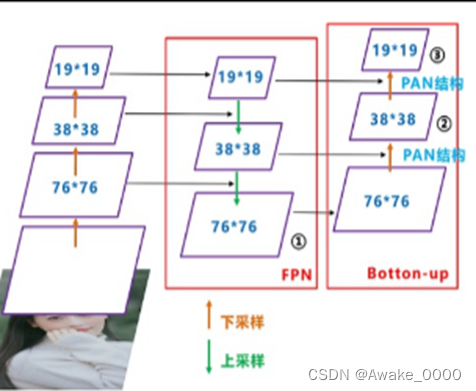
3.Neck: FPN+PAN结构
FPN结构:
自上向下的一个特征金字塔,通过自顶向下的上采样操作使得底层特征图包含更强的语义信息。
PAN结构:
自下向上的金字塔,通过自底向上的下采样操作将低层定位特征传递到高层,确保高层特征兼具语义信息和定位能力。
4.Head: Bounding box损失函数,NMS非极大值抑制
Bounding box损失函数:
IOU是目标检测中常用的损失函数之一,它衡量的是预测框(bounding box)与真实框(ground truth box)之间的重叠程度。IOU值越大,表示预测框与真实框的重叠程度越高,损失越小。但是,当预测框与真实框没有交集时,IOU值为0,此时损失函数无法提供有效的梯度信息,导致模型无法继续学习。
IOU_Loss,GIOU_Loss,DIOU_Loss,CIOU_Loss详细区别请参考另外一位博主的博客,戳这👆
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 858
858

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









