




 博客基于元数据中心血缘信息,对大数据平台任务和分析查询统计。指出未识别分层表复用难,已识别分层中大量任务基于原始数据加工,中间模型复用性差,DWD、DWS、ADS层数据建设缺失严重。还发现大量ODS层表被物理深加工,认为理想数仓模型应数据可复用、完善且规范。
博客基于元数据中心血缘信息,对大数据平台任务和分析查询统计。指出未识别分层表复用难,已识别分层中大量任务基于原始数据加工,中间模型复用性差,DWD、DWS、ADS层数据建设缺失严重。还发现大量ODS层表被物理深加工,认为理想数仓模型应数据可复用、完善且规范。
来看一组数据,这两个表格是基于元数据中心提供的血缘信息,分别对大数据平台上运行的任务和分析查询(Ad-hoc)进行的统计。
离线调度任务/表统计
一周内Ad-hoc 查询统计
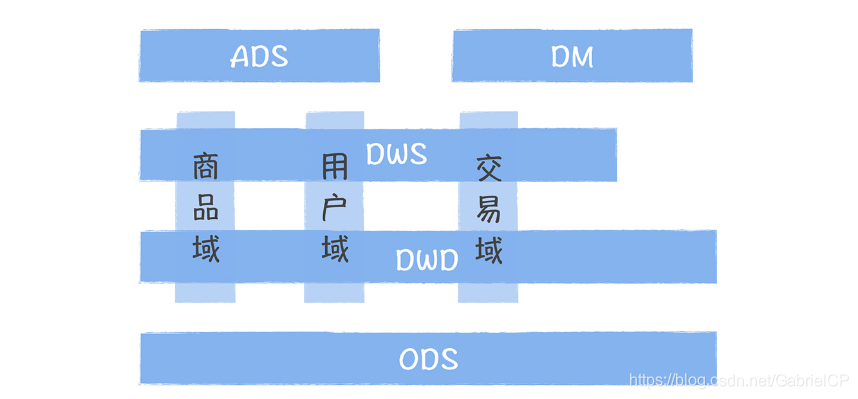
下图是数仓分层架构图,方便你回忆数据模型分层的设计架构:
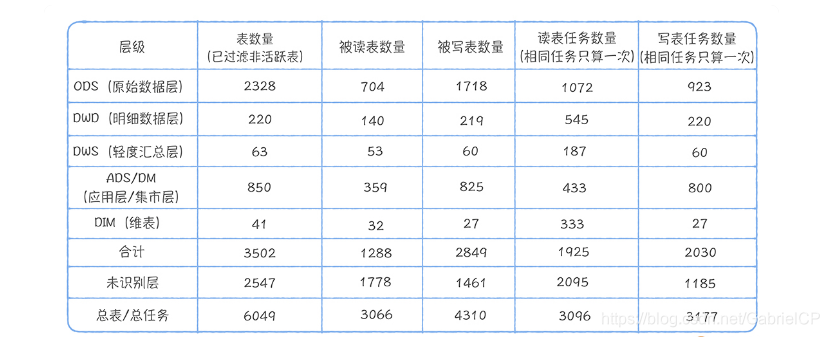
我们首先来看表 1。表 1 中有 2547 张未识别分层的表,占总表 6049 的 40%,它们基本没办法复用。 重点是在已识别分层的读表任务中,ODS:DWD:DWS:ADS 的读取任务分别是 1072:545:187:433,直接读取 ODS 层任务占这四层任务总和的 47.9%,这说明有大量任务都是基于原始数据加工,中间模型复用性很差。
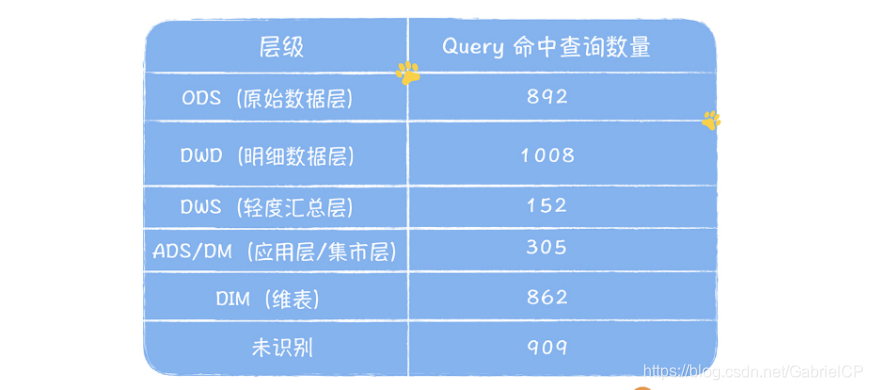
我们再来看看表 2,在已识别的分层的查询中,ODS:DWD:DWS:ADS 的命中的查询分别是 892:1008:152:305,有 37.8% 的查询直接命中 ODS 层原始数据,说明 DWD、DWS、ADS 层数据建设缺失严重。尤其是 ADS 和 DWS,查询越底层的表,就会导致查询扫描的数据量会越大,查询时间会越长,查询的资源消耗也越大,使用数据的人满意度会低。
最后,我们进一步对 ODS 层被读取的 704 张表进行分解,发现有 382 张表的下游产出是 DWS,ADS,尤其是 ADS 达到了 323 张表,占 ODS 层表的比例 45.8%,说明有大量 ODS 层表被进行物理深加工。
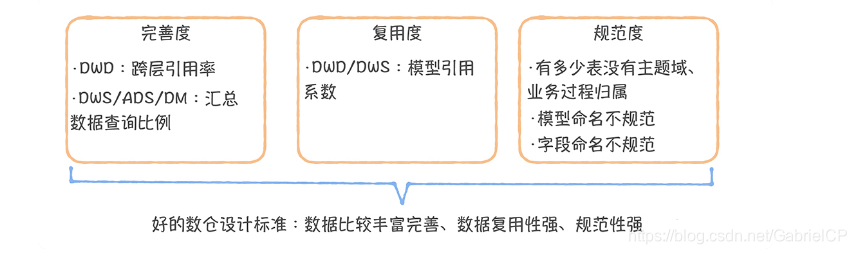
通过上面的分析,我们似乎已经找到了一个理想的数仓模型设计应该具备的因素,那就是“数据模型可复用,完善且规范”。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









