






摘 要:最近老板要求我做一个算法实现隧道内岩石的目标检测,通过学习,发现目前网上比较成熟的算法就是基于OpenCV中的opencv_haartraining.exe级联分类器来实现正负样本训练得到一个强分类器。通过这个强分类器来进行检测,实验发现,也许是正负样本的选取不是很好,实际的检测结果并不是很好,看后续能否在算法上进行改善。本文先简要介绍haar特征+AdaBoost级联分类器的原理,然后辅助OpenCV 2.4中的opencv_createsample.exe和opencv_haartraining.exe来进行训练得到xml文件,最后利用xml文件来撰写检测程序来实现岩石检测。
首先声明,这篇文章是一篇学习笔记,是作者在阅读了各位大神的博客而写出来的一片学习总结,所有内容并非完全自己的原创,如果原作者觉得本篇文章侵权,请联系我,我会及时修改内容。
-
Haar分类器原理
这里有一篇博文介绍的非常好,在这边我就直接引用了。首先来简要介绍一下目标检测的背景。浅析人脸检测之Haar分类器方法:Haar特征、积分图、 AdaBoost 、级联
1.1目标检测算法简介
目标检测属于计算机视觉的范畴,早期人们的主要研究方向是目标识别,即输入图像只包含待检测对象,然后根据已知检测对象来识别图像是否为检测目标,而无需考虑图像的背景问题。后来在复杂背景下的目标检测需求越来越大,目标检测也逐渐作为一个单独的研究方向发展起来。
目前的目标检测方法主要有两大类:基于知识和基于统计。以人脸检测为例:
●基于知识的方法:主要利用先验知识将人脸看作器官特征的组合,根据眼睛、眉毛、嘴巴、鼻子等器官的特征以及相互之间的几何位置关系来检测人脸。主要方法包括:模版匹配、人脸特征、形状与边缘、纹理特性、颜色特征等。
●基于统计的方法:将人脸看作一个整体的模式---二维像素矩阵,从统计的观点通过大量人脸图像样本构造人脸模式空间,根据相似度量在判断人脸是否存在。主要方法包括:主成份分析与特征脸、神经网络方法、支持向量机、隐马尔可夫模型、Adaboost算法等。
其中按照算法的基本原理又可以分为传统的目标检测算法和深度学习的目标检测算法。传统算法的典型代表有:Haar特征+Adaboost算法、Hog特征+Svm算法和DPM算法等;深度学习的目标检测典型代表有:RCNN系列(RCNN、spp-net、fast-rcnn和faster-rcnn等)、YOLO系列(YOLO和YOLO9000)以及SSD等。本文主要讨论Haar特征+Adaboost算法,其原理比较简单。至于其他的算法,可以为想继续研究下去的朋友们提供一个方向。
1.2 Haar特征分类器原理
本文中介绍的Haar分类器方法,包含了Adaboost算法,稍候会对这一算法做详细介绍。其主要内容可以表示为Haar分类器=Haar-like特征+积分图方法+Adaboost级联。具体来说,可以概述为如下模式:
-
使用Haar-like特征做检测;
-
使用积分图(Integral Image)对Haar-like特征求值进行加速;
-
使用AdaBoost算法训练区分目标与非目标的强分类器;
-
使用筛选式级联把强分类器级联到一起,提高准确率。
1.2.1 Haar-like特征
要进行目标检测,也就是说要在一副图像中准确进行分类,就必须要给出一个评价指标,当这个评价指标达到一定的阈值时,我们就可以把它认为是目标(如人脸)。这个评价指标在Haar特征分类器中就是Haar-like特征。
那么什么是特征呢?例如,假设在目标检测时我们需要有这么一个子窗口在待检测的图片窗口中不断的移位滑动缩放等操作,子窗口每到一个位置,就会计算出该区域的特征,然后用一阈值与其对比,这个阈值由训练好的级联分类器提供,一旦该特征通过所有强分类器的筛选,则判定该区域为目标。下面是viola&Jones提出的Haar-like特征模版:
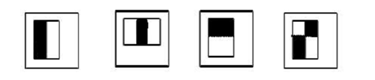
(1) (2) (3) (4)
图1 Viola使用的4种矩形特征
(1、3为边界特征,2为细线特征,4为对角线特征)
OpenCV中的Haar特征有一下几种
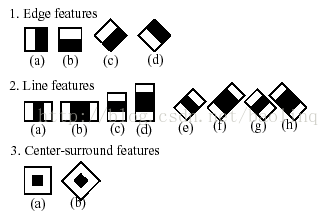
图2 OpenCV中使用的Haar特征模版
这些所谓的特征不就是一堆带条纹的矩形么,到底是干什么用的?我这样给出解释,将上面的任意一个矩形放到正样本(只包含检测目标)区域上,然后,将白色区域的像素和减去黑色区域的像素和,得到的值我们暂且称之为监测特征值;如果把这个矩形放到一个负样本(不包含检测目标)图像区域,那么计算出的特征值应该和监测特征值是不一样的,而且越不一样越好,所以这些方块的目的就是把检测特征量化,以区分检测目标和非检测目标。
举个例子,对于一幅24*24分辨率的图像来说,可以通过改变特征模板的大小和位置,穷举出大量的特征来表示一幅图像。其中特征模板称为"特征原型";特征原型在图像子窗口中扩展(平移伸缩)得到的特征称为"矩形特征";矩形特征的值称为"特征值"。在24*24大小的图像中可以以坐标(0,0)开始宽为20高为20矩形模板计算图1中的(1)特征,也可以以坐标(0,2)开始宽为20高为20矩形模板计算特征,也可以以坐标(0,0)开始宽为22高为22矩形模板计算特征,这样矩形特征值随着类别、大小和位置的变化,使得很小的一幅很小的图像含有非常多的矩形特征[1]。一幅24*24分辨率的图像通过变换可以获得160,000个左右的特征值。
那么问题是,就这么一个简单的检测方案就能实现目标检测吗?答案是不能的。那么为了提高检测精度,就必须使用一些方法来进一步改善。这个方法就是AdaBoost算法。
1.2.2 AdaBoost算法简介
Adaboost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器)[2]。下面介绍就目标检测而言,如何获取弱分类器以及强分类器。
所谓弱分类器就是指一个学习算法对一组概念的识别率只比随机识别好一点的分类器;所谓强分类器是指一个学习算法对一组概率的识别率很好的分类器。弱学习算法是比较容易获得的,获得过程需要数量巨大的假设集合,这个假设集合是基于某些简单规则的组合和对样本集的性能评估而生成的,而强学习算法是不容易获得的,然而,有学者提出了弱学习和强学习等价的问题并证明了只要有足够的数据,弱学习算法就能通过集成的方式生成任意高精度的强学习方法。这一证明使得Boosting有了可靠的理论基础,Boosting算法成为了一个提升分类器精确性的一般性方法。
-
弱分类器的获取
弄清楚了什么弱分类器和强分类器的概念,下面就来讨论如何获取第一个弱分类器。前面已经说过了,通过比较待检测图像的矩形特征值来判断其是否是检测目标,这样我们就需要定下一个最佳的阈值来作为检测标准,当待检测图像的特征值大于这个阈值时就认为是检测目标,否则就认为不是检测目标。以24*24的图像为例[3],其矩形特征(haar)将近有160,000个,对每一个特征都有一个最佳的阈值,通过公式计算其误差,然后再比较这160,000个误差中最小的一个就作为整个图像的最佳阈值。
具体说来,给定一个训练数据集,其中实例 ,而实例空间
,而实例空间 ,属于标记集合{-1,+1},Adaboost的目的就是从训练数据中学习一系列弱分类器或基本分类器,然后将这些弱分类器组合成一个强分类器。
,属于标记集合{-1,+1},Adaboost的目的就是从训练数据中学习一系列弱分类器或基本分类器,然后将这些弱分类器组合成一个强分类器。
Adaboost训练弱分类器最佳阈值的算法流程如下[4]:
-
步骤1 . 首先,初始化训练数据的权值分布。计算每个全部训练样本的某个特征值并将其按大小排序,同时对每一个训练样本最开始时都被赋予相同的权值: 1/N 。
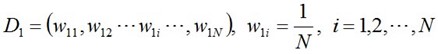
-
步骤2. 进行多轮迭代,用 m=1,2,...,M 表示迭代的第多少轮
a.使用具有权值分布的训练数据集学习,得到基本分类器(选取让误差率最低的阈值来设计基本分类器):
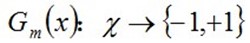
b.计算Gm(x)在训练数据集上的分类误差率
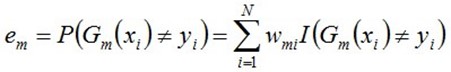
由上述式子可知,在训练数据集上的误差率就是被误分类样本的权值之和。这里说明一下,误差率按另一种表示法可以表示为:
式中,表示该阈值前的全部正样本的权重和;表示该阈值后的全部负样本的权重和;表示该阈值前的全部负样本的权重和;表示该阈值后的全部负样本的权重和。这其实代表了采用该阈值所误分类的样本概率,以括号中的前一项为例,假设我们认为大于该阈值为正样本,小于该阈值为负样本,那么这个公式表示该阈值前正样本和该阈值后负样本的权重和,那么这个误差就能代表这个阈值错误分类的样本的带权和。现在看不懂没关系,后面我会举一个粒子。先继续往下看。
c. 计算的系数,表示在最终分类器中的重要程度(目的:得到基本分类器在最终分类器中所占的权重):
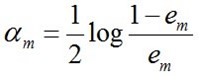
由上述式子可知,时,,且随着的减小而增大,意味着分类误差率越小的基本分类器在最终分类器中的作用越大。
d. 更新训练数据集的权值分布(目的:得到样本的新的权值分布),用于下一轮迭代
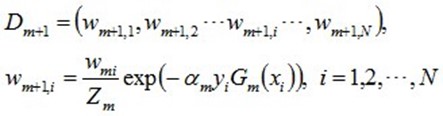
使得被基本分类器Gm(x)误分类样本的权值增大,而被正确分类样本的权值减小。就这样,通过这样的方式,AdaBoost方法能"重点关注"或"聚焦于"那些较难分的样本上。
其中,是规范化因子,使得成为一个概率分布:
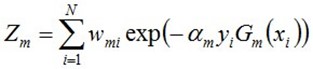
通过不断的更新权重,重新训练得到新的阈值,训练T轮之后就可以得到T个弱分类器。得到T个弱分类器之后再通过级联就可以得到一个强分类器。
(2)强分类器的获取
为了得到强分类器,将各个弱分类器组合起来,其组合组合策略如下:
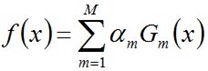
从而得到最终分类器,如下:
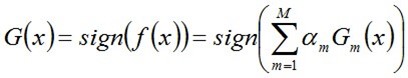
这个最终的分类器相当于让所有弱分类器投票,再对投票结果按照弱分类器的错误率加权求和,将投票加权求和的结果与平均投票结果比较得出最终的结果。当然了,每个分类器重要程度不同,误差越高的弱分类器所占的权重越少,也就是其的值越小。
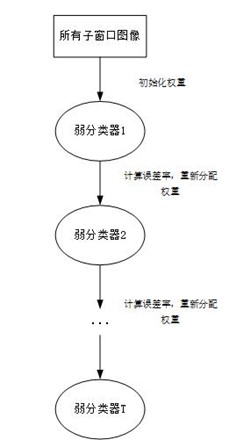
图3 弱分类器的形成
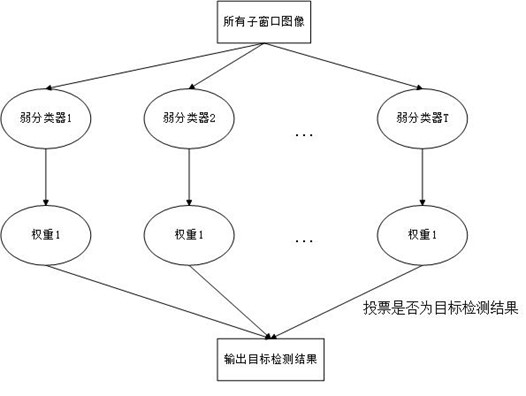
图3 T个弱分类器组合形成强分类器
1.2.3 AdaBoost算法案例[4]
下面,给定下列训练样本,请用AdaBoost算法学习一个强分类器。
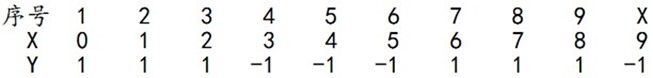
求解过程:初始化训练数据的权值分布,令每个权值,其中,N=10,i=1,2, ..., 10,然后分别对于m = 1,2,3, ...等值进行迭代。
拿到这10个数据的训练样本后,根据X和Y的对应关系,要把这10个数据分为两类,一类是"1",一类是"-1",根据数据的特点发现:"0 1 2"这3个数据对应的类是"1","3 4 5"这3个数据对应的类是"-1","6 7 8"这3个数据对应的类是"1",9是比较孤独的,对应类"-1"。抛开孤独的9不讲,"0 1 2"、"3 4 5"、"6 7 8"这是3类不同的数据,分别对应的类是1、-1、1,直观上推测可知,可以找到对应的数据分界点,比如2.5、5.5、8.5 将那几类数据分成两类。当然,这只是主观臆测,下面实际计算下这个具体过程。
迭代过程1
对于m=1,在权值分布为D1(10个数据,每个数据的权值皆初始化为0.1)的训练数据上,经过计算可得:
阈值v取2.5时误差率为0.3(x<2.5时取1,x>2.5时取-1,则6 7 8分错,误差率为0.3),
阈值v取5.5时误差率最低为0.4(x<5.5时取1,x>5.5时取-1,则3 4 5 6 7 8皆分错,误差率0.6大于0.5,不可取。故令x>5.5时取1,x<5.5时取-1,则0 1 2 9分错,误差率为0.4),
阈值v取8.5时误差率为0.3(x<8.5时取1,x>8.5时取-1,则3 4 5分错,误差率为0.3)。
可以看到,无论阈值v取2.5,还是8.5,总得分错3个样本,故可任取其中任意一个如2.5,弄成第一个基本分类器为:
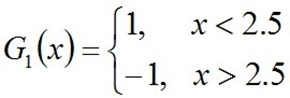
上面说阈值v取2.5时则6 7 8分错,所以误差率为0.3,更加详细的解释是:因为样本集中
1. 0 1 2对应的类(Y)是1,因它们本身都小于2.5,所以被G1(x)分在了相应的类"1"中,分对了。
2. 3 4 5本身对应的类(Y)是-1,因它们本身都大于2.5,所以被G1(x)分在了相应的类"-1"中,分对了。
3. 但6 7 8本身对应类(Y)是1,却因它们本身大于2.5而被G1(x)分在了类"-1"中,所以这3个样本被分错了。
4. 9本身对应的类(Y)是-1,因它本身大于2.5,所以被G1(x)分在了相应的类"-1"中,分对了。
从而得到G1(x)在训练数据集上的误差率(被G1(x)误分类样本"6 7 8"的权值之和)e1=P(G1(xi)≠yi) = 3*0.1 = 0.3。
然后根据误差率e1计算G1的系数:
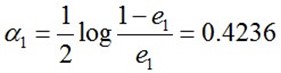
这个a1代表G1(x)在最终的分类函数中所占的权重,为0.4236。
接着更新训练数据的权值分布,用于下一轮迭代:
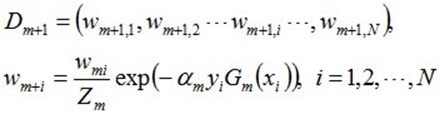
值得一提的是,由权值更新的公式可知,每个样本的新权值是变大还是变小,取决于它是被分错还是被分正确。
即如果某个样本被分错了,则yi * Gm(xi)为负,负负得正,结果使得整个式子变大(样本权值变大),否则变小。
第一轮迭代后,最后得到各个数据新的权值分布D2=(0.0715, 0.0715,0.0715,0.0715,0.0715,0.0715,0.1666,0.1666,0.1666,0.0715)。由此可以看出,因为样本中是数据"6 7 8"被G1(x)分错了,所以它们的权值由之前的0.1增大到0.1666,反之,其它数据皆被分正确,所以它们的权值皆由之前的0.1减小到0.0715。
分类函数f1(x)= a1*G1(x) = 0.4236G1(x)。
此时,得到的第一个基本分类器sign(f1(x))在训练数据集上有3个误分类点(即6 7 8)。
从上述第一轮的整个迭代过程可以看出:被误分类样本的权值之和影响误差率,误差率影响基本分类器在最终分类器中所占的权重。
迭代过程2
对于m=2,在权值分布为D2=(0.0715,0.0715,0.0715,0.0715, 0.0715,0.0715,0.1666,0.1666,0.1666,0.0715)的训练数据上,经过计算可得:
1. 阈值v取2.5时误差率为0.1666*3(x<2.5时取1,x>2.5时取-1,则6 7 8分错,误差率为0.1666*3),
2. 阈值v取5.5时误差率最低为0.0715*4(x>5.5时取1,x<5.5时取-1,则0 1 2 9分错,误差率为0.0715*3 + 0.0715),
3. 阈值v取8.5时误差率为0.0715*3(x<8.5时取1,x>8.5时取-1,则3 4 5分错,误差率为0.0715*3)。
所以,阈值v取8.5时误差率最低,故第二个基本分类器为:
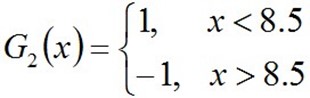
面对的还是下述样本:
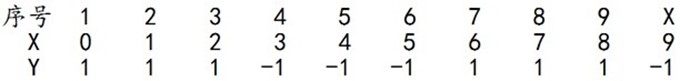
很明显,G2(x)把样本"3 4 5"分错了,根据D2可知它们的权值为0.0715,0.0715,0.0715,所以G2(x)在训练数据集上的误差率e2=P(G2(xi)≠yi)=0.0715*3 =0.2143。
计算G2的系数:
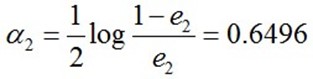
更新训练数据的权值分布:
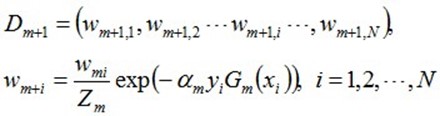
D3=(0.0455,0.0455,0.0455,0.1667,0.1667,0.01667,0.1060,0.1060,0.1060,0.0455)。被分错的样本"3 4 5"的权值变大,其它被分对的样本的权值变小。
f2(x)=0.4236G1(x)+0.6496G2(x)
此时,得到的第二个基本分类器sign(f2(x))在训练数据集上有3个误分类点(即3 4 5)。
迭代过程3
对于m=3,在权值分布为D3=(0.0455,0.0455,0.0455,0.1667,0.1667, 0.01667,0.1060,0.1060,0.1060,0.0455)的训练数据上,经过计算可得:
1. 阈值v取2.5时误差率为0.1060*3(x<2.5时取1,x>2.5时取-1,则6 7 8分错,误差率为0.1060*3),
2. 阈值v取5.5时误差率最低为0.0455*4(x>5.5时取1,x<5.5时取-1,则0 1 2 9分错,误差率为0.0455*3+0.0715),
3. 阈值v取8.5时误差率为0.1667*3(x<8.5时取1,x>8.5时取-1,则3 4 5分错,误差率为0.1667*3)。
所以阈值v取5.5时误差率最低,故第三个基本分类器为:
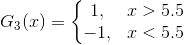
依然还是原样本:
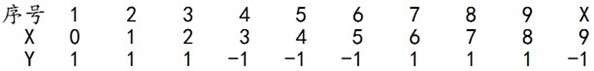
此时,被误分类的样本是:0 1 2 9,这4个样本所对应的权值皆为0.0455,所以G3(x)在训练数据集上的误差率e3=P(G3(xi)≠yi) =0.0455*4=0.1820。
计算G3的系数:
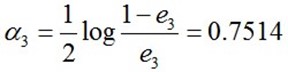
更新训练数据的权值分布:
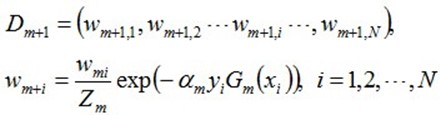
D4=(0.125,0.125,0.125,0.102,0.102,0.102,0.065,0.065,0.065,0.125)。被分错的样本"0 1 2 9"的权值变大,其它被分对的样本的权值变小。
f3(x)=0.4236G1(x)+0.6496G2(x)+0.7514G3(x)
此时,得到的第三个基本分类器sign(f3(x))在训练数据集上有0个误分类点。至此,整个训练过程结束。
现在,咱们来总结下3轮迭代下来,各个样本权值和误差率的变化,如下所示(其中,样本权值D中加了下划线的表示在上一轮中被分错的样本的新权值):
1. 训练之前,各个样本的权值被初始化为D1=(0.1,0.1,0.1,0.1,0.1, 0.1,0.1,0.1,0.1,0.1);
第一轮迭代中,样本"6 7 8"被分错,对应的误差率为e1=P(G1(xi)≠yi)=3*0.1=0.3,此第一个基本分类器在最终的分类器中所占的权重为α1=0.4236。第一轮迭代过后,样本新的权值为D2=(0.0715, 0.0715,0.0715,0.0715,0.0715,0.0715,0.1666,0.1666,0.1666,0.0715);
第二轮迭代中,样本"3 4 5"被分错,对应的误差率为e2=P(G2(xi)≠yi)=0.0715*3=0.2143,此第二个基本分类器在最终的分类器中所占的权重为α2 =0.6496。第二轮迭代过后,样本新的权值为D3= (0.0455,0.0455,0.0455,0.1667,0.1667,0.01667,0.1060,0.1060,0.1060,0.0455);
第三轮迭代中,样本"0 1 2 9"被分错,对应的误差率为e3=P(G3(xi)≠yi)=0.0455*4=0.1820,此第三个基本分类器在最终的分类器中所占的权重为α3=0.7514。第三轮迭代过后,样本新的权值为D4=(0.125,0.125,0.125,0.102,0.102,0.102,0.065,0.065,0.065,0.125)。
从上述过程中可以发现,如果某些个样本被分错,它们在下一轮迭代中的权值将被增大,反之,其它被分对的样本在下一轮迭代中的权值将被减小。就这样,分错样本权值增大,分对样本权值变小,而在下一轮迭代中,总是选取让误差率最低的阈值来设计基本分类器,所以误差率e(所有被Gm(x)误分类样本的权值之和)不断降低。
综上,将上面计算得到的α1、α2、α3各值代入G(x)中,G(x)=sign[f3(x)]=sign[α1*G1(x)+α2*G2(x)+α3*G3(x)],得到最终的分类器为:
G(x)=sign[f3(x)]=sign[0.4236G1(x)+0.6496G2(x)+0.7514G3(x)]






































 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









