







1. 模式评估方法
评估方法的规则
大部分关联规则挖掘算法都使用指支持度-置信度框架。尽管最小支持度和置信度阈值有助于排出大量无趣规则的探查,但仍然会产生一些用户不感兴趣的规则。
- 强规则不一定是有趣的
- 从关联分析到相关分析
2. 强规则不一定是有趣的
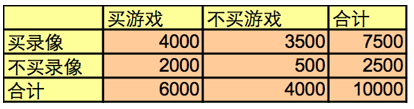
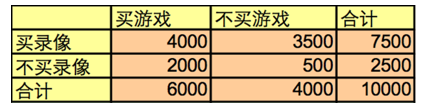
- 例1:买游戏->买录像
buys(X, “computer games”) => buys(X, “videos”) [40%, 66%]- 但其实全部人中购买录像带的人数是75%,比66%多;事实上录像带和游戏是负相关的。
- 但由此可见A => B的置信度有欺骗性,它只是给出A,B条件概率的估计,而不度量A,B间蕴涵的实际强度。
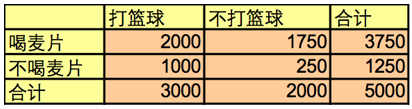
- 例2:打篮球->喝燕麦粥
- 在5000个学生中
a. 3000个打篮球
b. 3750个喝麦片粥
c. 2000个学生既打篮球又喝麦片粥 - 然而,打篮球 => 喝麦片粥 [40%, 66.7%]是错误的,因为全部学生中喝麦片粥的比率是75%,比打篮球学生的66.7%要高
- 打篮球 => 不喝麦片粥 [20%, 33.3%]这个规则远比上面那个要精确,尽管支持度和置信度都要低的多
- 在5000个学生中
- 支持度缺点
- 若支持度阈值过高,则许多潜在有意义的模式本删掉
- 若支持与之过低,则计算代价很高而且产生大量的关联模式
- 置信度的缺点
- 若支持度阈值过高,则许多潜在有意义的模式本删掉
- {打篮球}->{吃麦片}
- 置信度=P(吃麦片|打篮球)=0.67,
- 但P(吃麦片)=0.75
置信度忽略了规则前间和后见的统计独立性
3 从关联规则到相关性分析
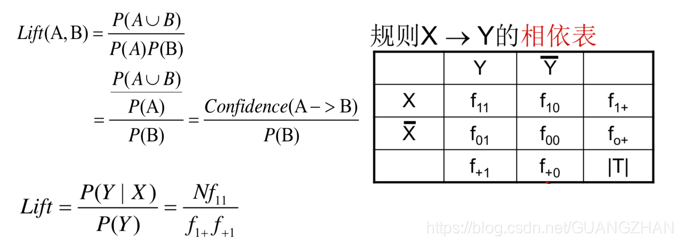
提升度
-
等价变换类算法(Eclat算法)
-
相关度量
- 可以使用相关度量来扩充关联规则的支持度—置信度框架,
- 我们需要一种度量事件间的相关性或者是依赖性的
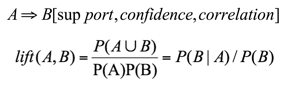
当P(A∪B)=P(A)P(B),即lift(A,B)=1,表明A与B无关, lift(A,B) >1表明A与B正相关, lift(A,B) <1表明A与B负相关 - 将相关性指标用于前面的例子,可以得出录像带和游戏将的相关性为
- P({game, video})/(P({game})×P({video}))=0.4/(0.75×0.6)=0.89
- 结论:录像带和游戏之间存在负相关
-
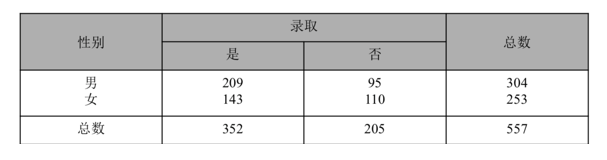
辛普森悖论
- 规则{性别=男}->{录取=是}的置信度是209/304=68.8%
- 规则{性别=女}->{录取=是}的置信度是143/253=56.5%
-
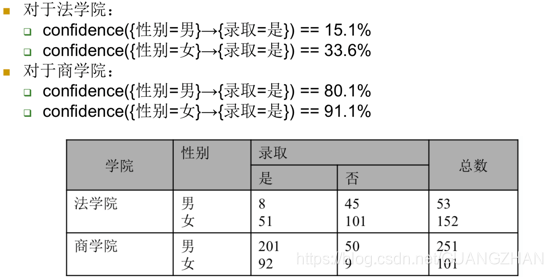
分组
-
避免辛普森悖论
- 置信度表明,对于每一个学院,女生更有可能录取,这与先前由包含两个学院的数据得到的结论恰好相反。
- 进行关联分析时,有的时候需要对数据进行适当的分组,才能 避免因辛普森悖论产生虚假的模式
-
其他的评估方式
- 进行关联分析时,有的时候需要对数据进行适当的分组,才能 避免因辛普森悖论产生虚假的模式
-
其他的评估方式


















 2572
2572

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









