



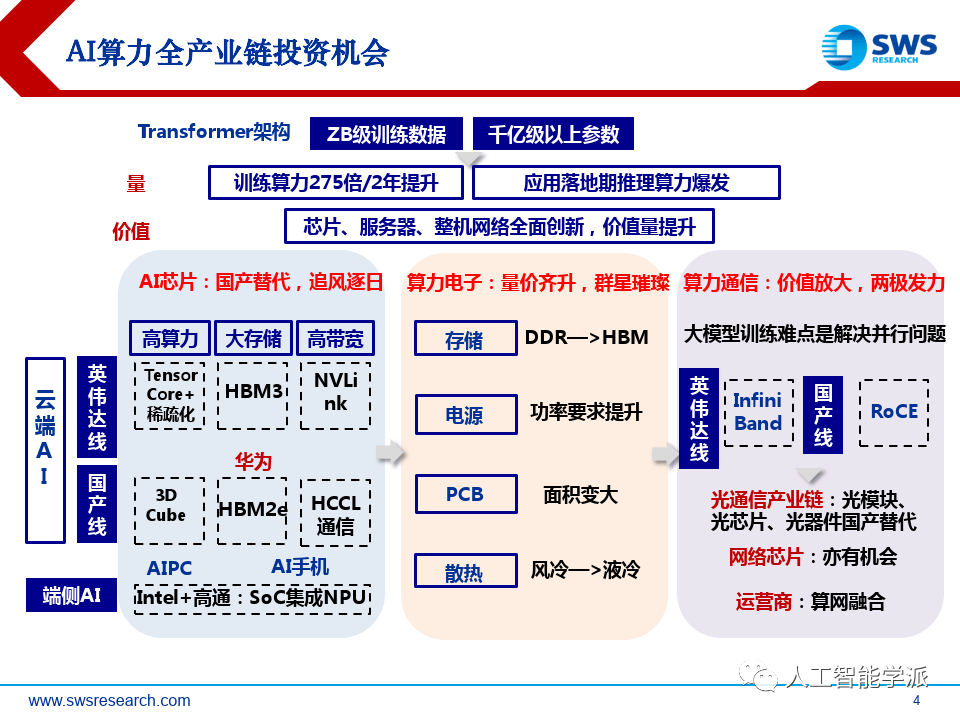
 报告分析了AI算力在大模型时代的需求增长,强调GPU计算性能提升和产业链各环节的创新,如内存封装、光模块发展和AI芯片国产替代。同时指出通信瓶颈在大模型训练中的重要性,以及华为在优化通信方面的努力。
报告分析了AI算力在大模型时代的需求增长,强调GPU计算性能提升和产业链各环节的创新,如内存封装、光模块发展和AI芯片国产替代。同时指出通信瓶颈在大模型训练中的重要性,以及华为在优化通信方面的努力。
今天分享的是AI算力系列深度研究报告:《2024年AI算力行业投资策略:全产业创新不断,国产化向阳而生》。
(报告出品方:SWS)
报告共计:53页



大模型时代,训练需求飙升
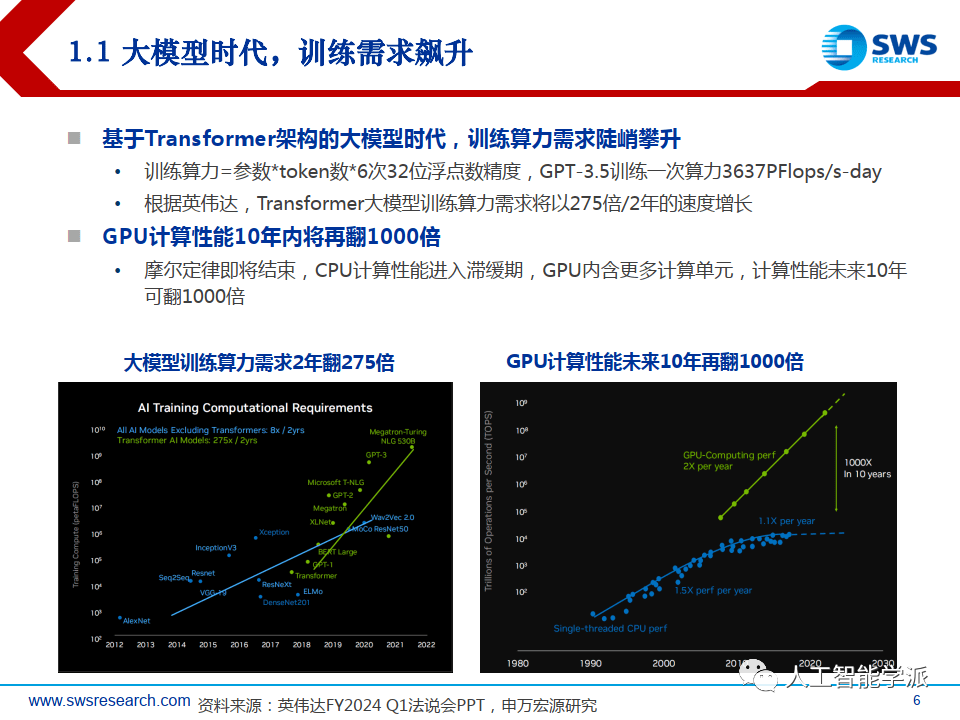
基于Transformer架构的大模型时代,训练算力需求陡峭攀升
• 训练算力=参数*token数*6次32位浮点数精度,GPT-3.5训练一次算力3637PFlops/s-day
• 根据英伟达,Transformer大模型训练算力需求将以275倍/2年的速度增长
GPU计算性能10年内将再翻1000倍
• 摩尔定律即将结束,CPU计算性能进入滞缓期,GPU内含更多计算单元,计算性能未来10年 可翻1000倍
AI算力:大模型“卖铲人”,技术创新的基石
无论谁做大模型、采用何种模型技术路线,算力都是必须的,需求确定性强、持续性高(前期训练+应用铺开后推理),业绩率先体现,并且有明确的量价关系。
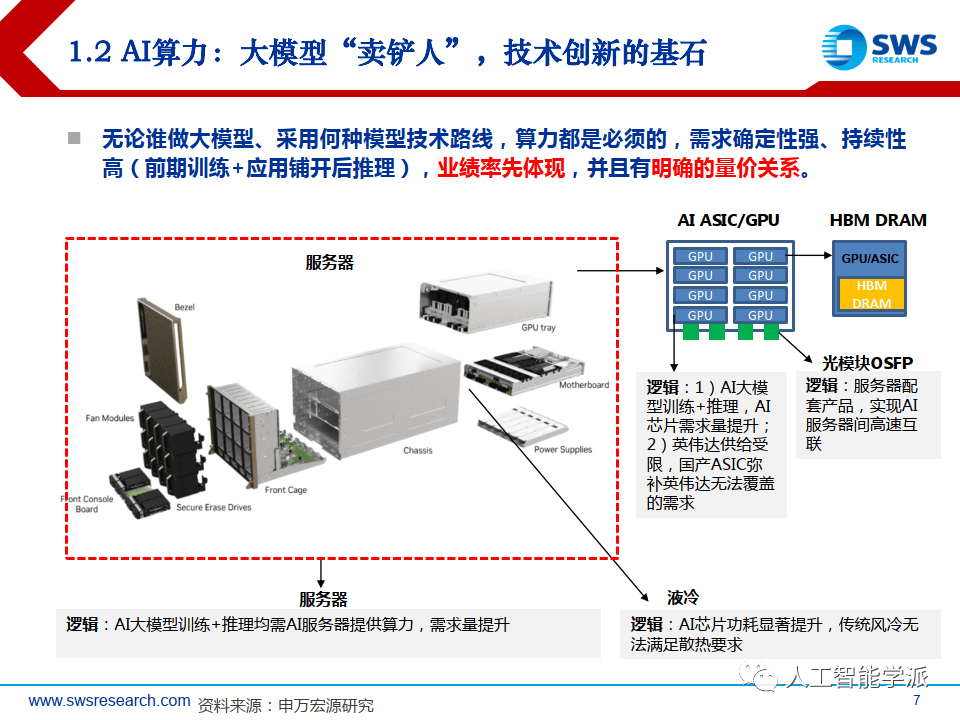
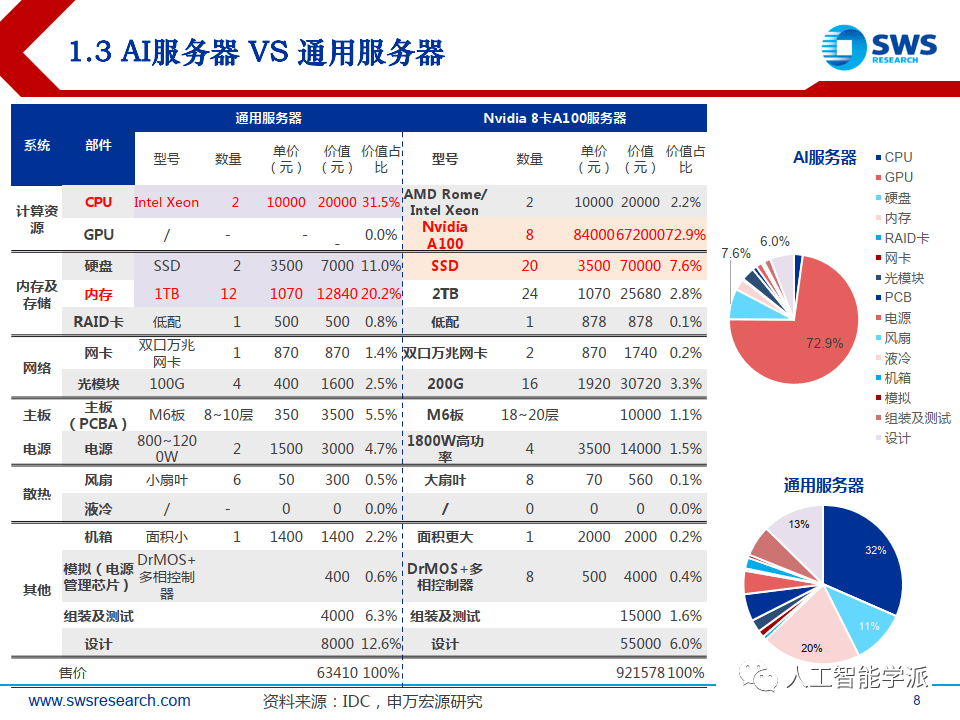
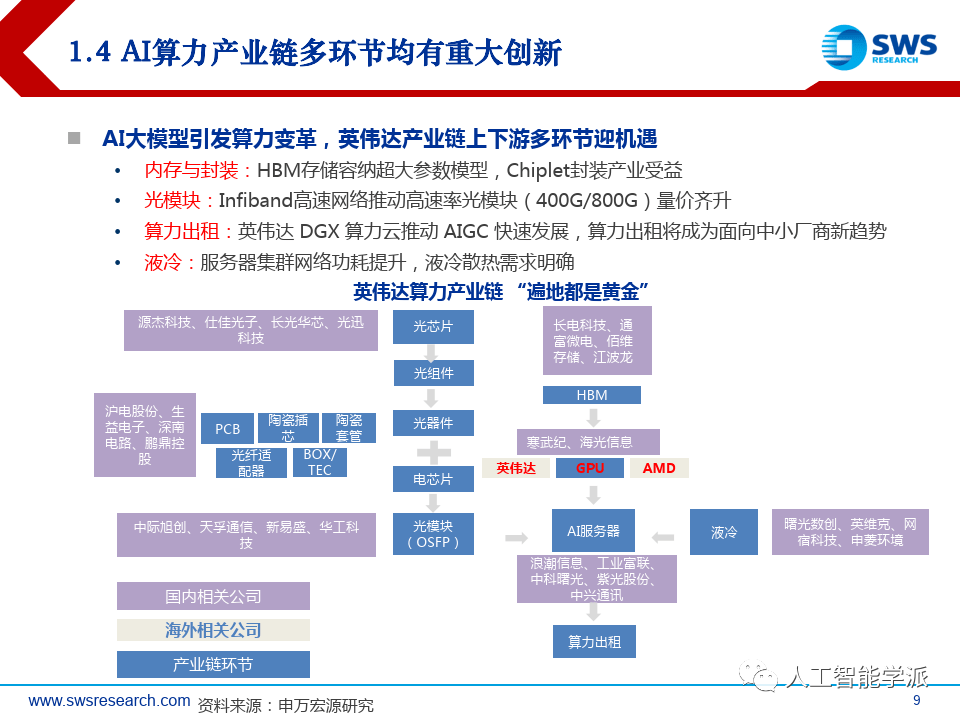
AI算力产业链多环节均有重大创新
AI大模型引发算力变革,英伟达产业链上下游多环节迎机遇
• 内存与封装:HBM存储容纳超大参数模型,Chiplet封装产业受益
• 光模块:Infiband高速网络推动高速率光模块(400G/800G)量价齐升
• 算力出租:英伟达 DGX 算力云推动 AIGC 快速发展,算力出租将成为面向中小厂商新趋势
• 液冷:服务器集群网络功耗提升,液冷散热需求明确
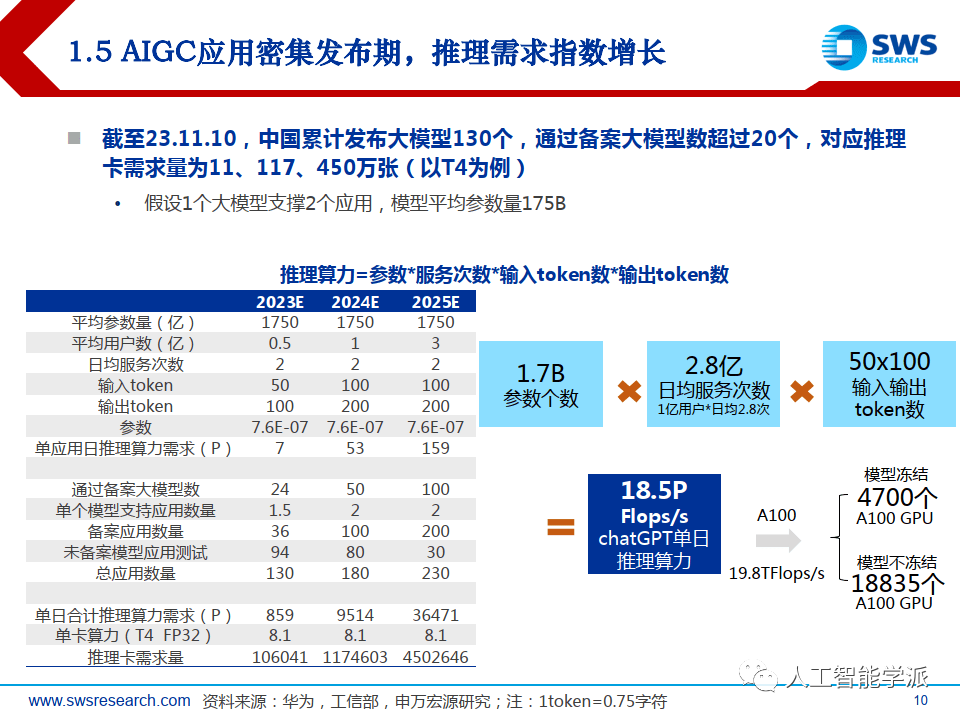
AIGC应用密集发布期,推理需求指数增长
截至23.11.10,中国累计发布大模型130个,通过备案大模型数超过20个,对应推理 卡需求量为11、117、450万张(以T4为例)
• 假设1个大模型支撑2个应用,模型平均参数量175B
半导体:制程进步对算力的带动大
半导体制程持续进步,设计密度有提升空间
• 参考制程/半导体时序/密度的关系
• 逻辑可更复杂。关键路径Critical Path能容纳的 逻辑单元更复杂
• 频率提升。可以实现更复杂的功能和算法,工作 频率也可能提高
根据通信协议,做可借鉴案例
• 星闪是一个案例。制程进步,有重新设计逻辑单 元的自由度
• 可重新设计协议,不用兼容10-20年前协议

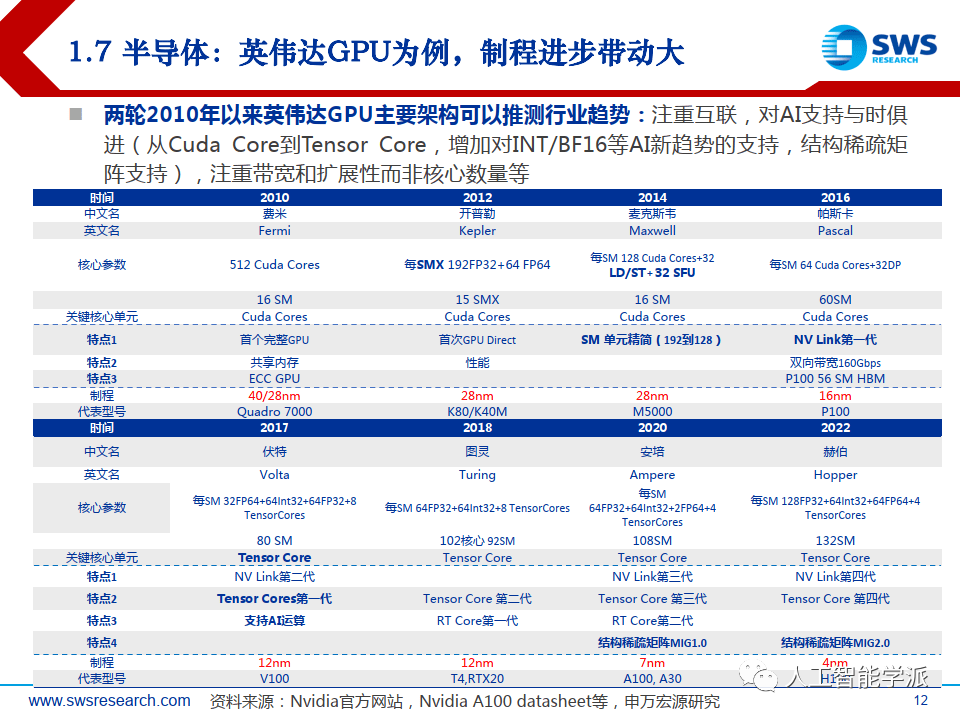
半导体:英伟达GPU为例,制程进步带动大
两轮2010年以来英伟达GPU主要架构可以推测行业趋势:注重互联,对AI支持与时俱进(从Cuda Core到Tensor Core,增加对INT/BF16等AI新趋势的支持,结构稀疏矩阵支持),注重带宽和扩展性而非核心数量等

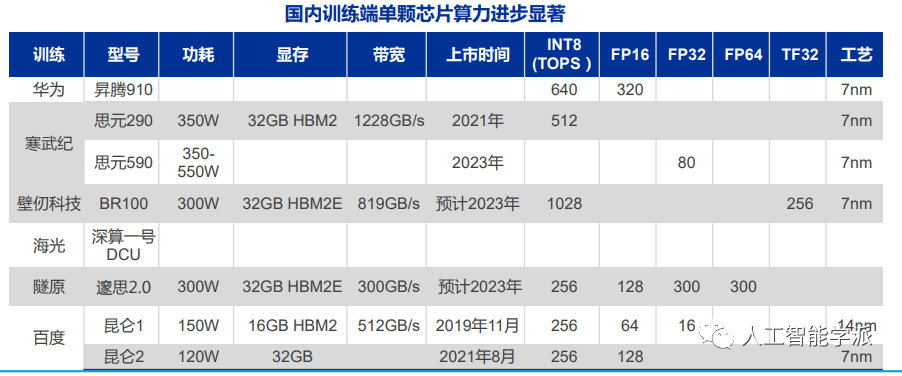
AI芯片国产替代单芯片性能进步明显
两轮禁令后,AI芯片供给安全需求更加迫切
• 2022年9月后,A100/H100进口受限;2023年10月后,A800/H800进口受限
对标A100/H100的国产产品仍未大规模放量
• 仅华为昇腾910规模出货,其余国产AI芯片截止目前均未规模放量
国产推理芯片品类丰富,可满足下游需求
• 华为昇腾310,寒武纪100、270、370,燧原,沐曦,壁仞等均有产品可用
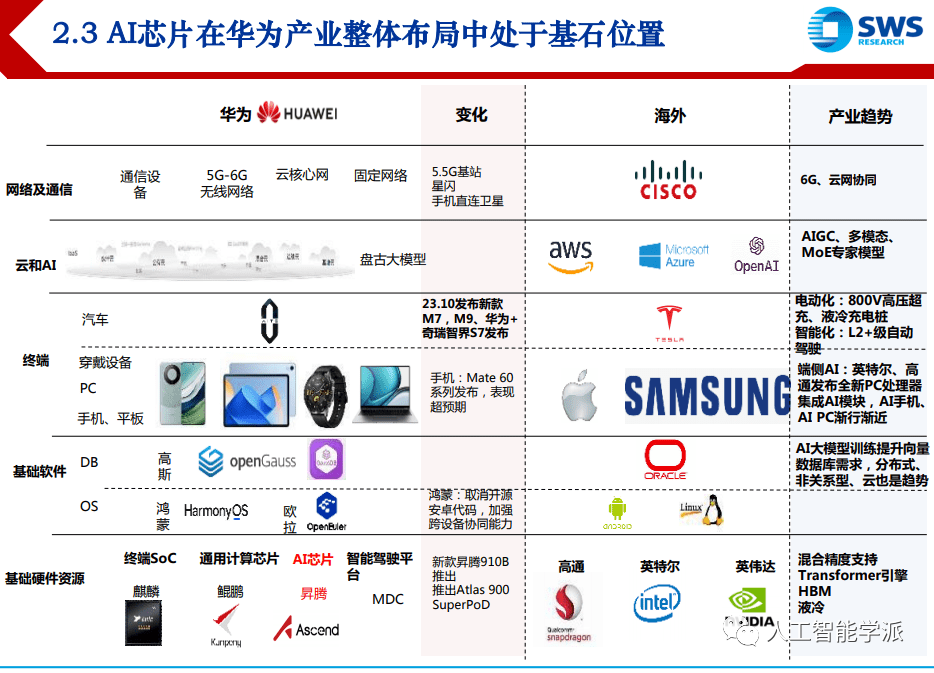
华为AI芯片通信瓶颈通过芯片、设备、组网优化
大模型训练性能瓶颈之一在通信,吞吐带宽与连接架构是算力性能的决定因素之一
• 类似 GPT3 的千亿参数模型,通信的端到端耗时占比达到 20%,
• 针对某个万亿参数 MoE 模型建模发现,通信的端到端耗时占比急剧上升到约 50%
英伟达:芯片层面采用高速C2C连接方案NVlink,集群层面,引入 InfiniBand网络 , 并将 C2C场景下应用的NVLink延伸至设备间互联,提出fat-tree胖树架构
华为:目前动作主要在集群层面,与英伟达思想类似,最新华为星河交换机采用 800GE端口,同时降低组网层数,最新Atlas 900 SuperCluster仅2层交换网络便能 实现无收敛集群组网
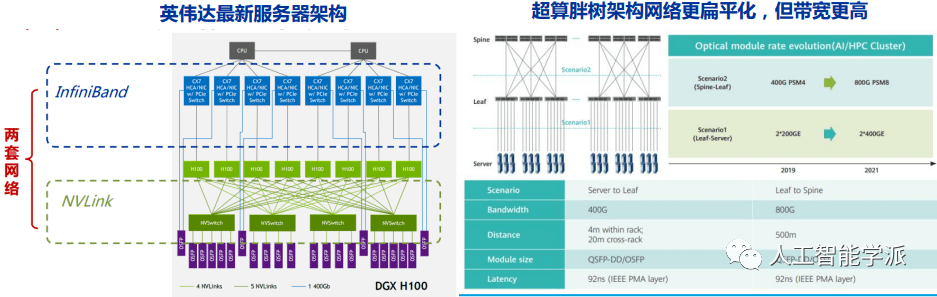

需求确定性:根源是通信的AI边际价值被放大
AI背景下通信环节的价值,从内容驱动的流量逻辑,延伸至模型驱动的算力逻辑。
• 历史上的几轮通信周期,下游驱动主要是互联网和云。
• 每一轮成长都叠加了内容或应用的创新,通信的流量管道属性充分体现。
• 当前通信环节的最大边际价值在于,网络与算力强耦合,网络需求与算力需求共进退。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









