







大型语言模型(LLM)在文本摘要、问答和角色扮演对话等语言任务上表现出色,在数学推理等复杂问题上也具有应用潜力。
但目前提高 LLM 数学问题解决能力的方法,往往会导致其他方面能力的下降。例如RLHF的方法,虽然可以提高文本生成的质量,但却会忽略解决数学问题所需要的准确性和逻辑连贯性,而 SFT 微调,则可能降低大模型本身的语言多样性。
针对这一问题,我们提出了一种「Self-Critique」的迭代训练方法,通过自我反馈的机制,可以使 LLM 的语言能力和数学能力得到同步提升。
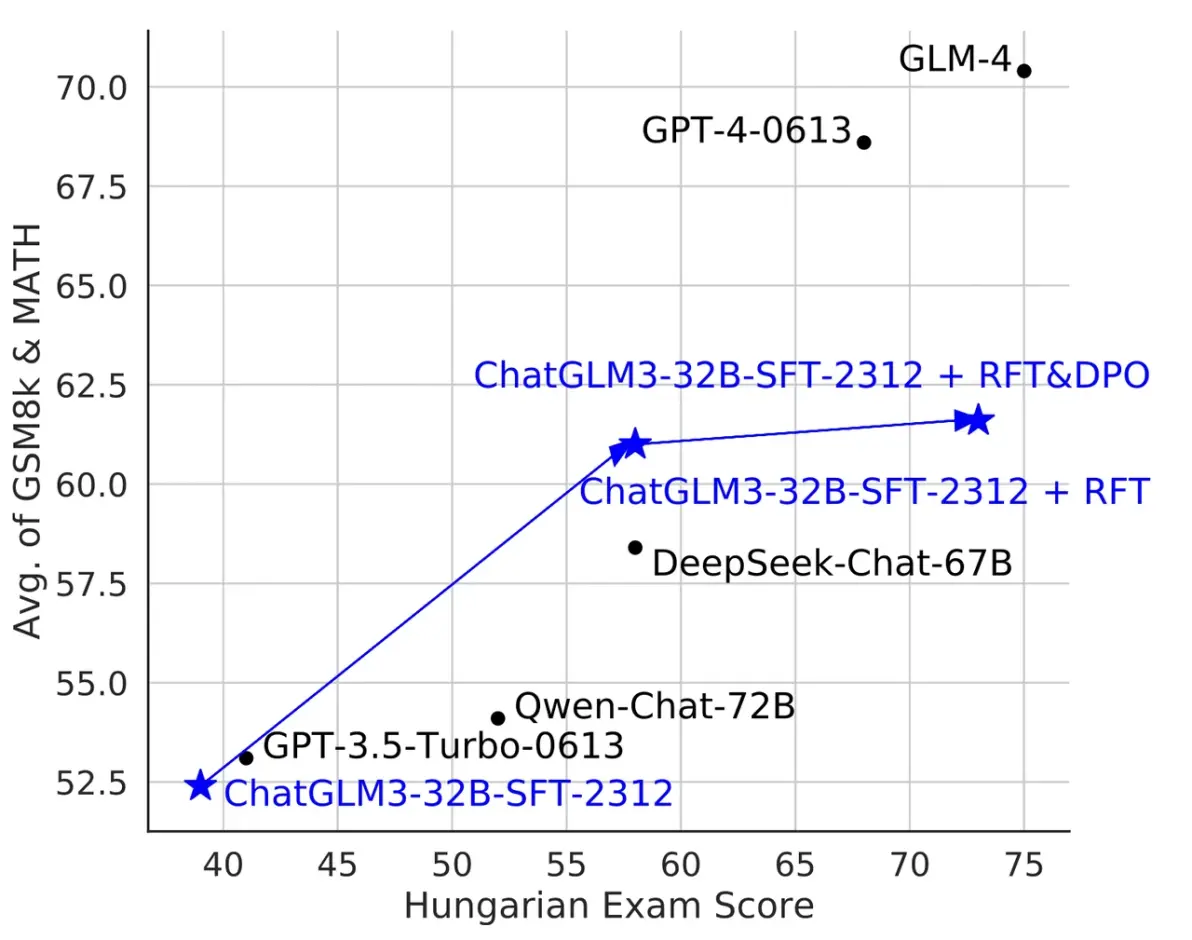
图:基于 Self-Critique 方法,ChatGLM3-32B的传统学术数据集数学能力(GSM8k)和分布外测试集匈牙利国家数学考试分数(Hungarian Exam Score)都得到了的提升。
此外,为了更加准确地评估 LLM 解决现实世界数学问题的能力,我们开发了 MathUserEval 评测基准。

项目地址:https://github.com/THUDM/ChatGLM-
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 347
347

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









