




 本文详细解析了Redis服务器如何利用事件驱动机制,通过文件事件处理器和时间事件实现高效网络通信与定时任务。涵盖了套接字、IO多路复用、事件类型、处理器如连接应答、命令请求及时间事件调度等内容。
本文详细解析了Redis服务器如何利用事件驱动机制,通过文件事件处理器和时间事件实现高效网络通信与定时任务。涵盖了套接字、IO多路复用、事件类型、处理器如连接应答、命令请求及时间事件调度等内容。
事件
在AOF那章提到过,Redis服务器是一个事件驱动的程序,由一个Loop循环不断地接收事件执行和执行时间事件
首先认识以下什么是套接字
套接字是对运输层以下的一个抽象封装,将运输层以下,包括运输层的细节全部封装起来,这样应用层传数据给下层时,就不需要关注下面的细节,只需传给套接字即可。
然后再认识以下什么是IO多路复用
一般来说,解决并发的问题会开启多个线程去执行不同的连接,但是这有一个弊端就是CPU要切换上下文,因为每个线程有自己的空间,执行不同的线程时候,CPU也要对应切换不同的上下文(所以多线程会很耗CPU)
IO多路复用是针对单线程并发的,多路是指多个连接,复用是指都是使用同一个线程,比如现在有4个客户端连接上了Redis,在Linux中一切都是文件,所以这4个连接可以当成是4个文件,假如这4个文件都没有数据,那么就会发生阻塞,等待某一个或多个文件被传输进数据,当文件有数据的时候(即要进行IO操作),该文件就会被标记,然后停止阻塞,准备进行IO,然后去轮询有标记的文件,针对进行IO操作,这样就实现了IO多路复用。
- 文件事件(file event):Redis服务器是通过套接字与客户端或别的服务器进行连接,而文件事件就是服务器套接字操作的抽象,服务器与客户端(或其他服务器)的通信会产生相应的文件事件,服务器则通过监听并处理这些事件来完成一系列操作
- 时间事件(time event):时间事件是Redis服务器一些定时执行的操作,比如前面提到的ServerCron函数,是需要在指定时间点上执行的
文件事件
Redis基于Reactor模式开发了自己的网络事件处理器,该处理器被称为文件事件处理器(file event handler)
- 文件事件处理器使用I/O多路复用程序来同时监听多个套接字,并根据套接字目前执行的任务来为套接字关联不同的事件处理器(即针对每个连接绑定事件处理器,事件处理器不同于文件事件处理器)
- 当被监听的套接字准备好执行连接应答(accept)、读取(read)、写入(write)、关闭(close)等操作时,与操作相对应的文件时间就会产生,这时文件事件处理器就会调用套接字之前关联好的事件处理器来处理这些事件。
虽然文件事件处理器是以单线程的方式运行(因为Redis是单线程的),但是采用了IO多路复用程序来监听多个套接字(多个连接,对于多个连接有优化),即实现了高性能的网络通信模型,又可以很好地与Redis服务器其他运行的单线程的模块对接(模块都在同一个单线程里面,对接性是很好的),而且保持了Redis内部单线程的设计。
文件事件处理的构成
文件事件处理器总共有4个部分
- 套接字
- I/O多路复用程序
- 文件事件分派器
- 事件处理器

- 文件事件是对套接字操作的抽象,即每当一个套接字准备好执行连接应答、写入、读取、关闭等操作时,就会产生一个文件事件(即将所有套接字操作都抽象文件事件),一个用户连接代表一个套接字,所以可能会有多个套接字。
I/O多路复用是让单线程可以同时监听多个套接字,并且向文件事件分派器传送那些要产生事件的套接字(即发送了命令的用户),但注意这里每次都只传一个套接字,I/O多路复用会有一个阻塞队列来存储要发生事件的套接字,每次以传一个套接字的方式向文件事件分派器发送套接字,只有当上一个套接字产生的事件被处理完后,IO多路复用才会发送下一个套接字。
文件事件分派器接收IO多用复活传来程序传来的套接字,并根据套接字产生事件的类型,调用相应的事件处理器。
服务器会为执行不同任务的套接字关联不同的事件处理器,这些处理器都是一个个的函数,函数定义了服务器应该执行的动作。
IO多路复用程序的实现
Redis的IO多路复用程序的所有功能都是通过包装常见的select、epoll、evport和kqueue这些IO多路复用函数库来实现的(上面那些都是底层系统的多路复用函数库,每个库都是多路复用的一种实现方式),上面封装的每一个多路复用函数库在Redis源码中都是对应一个单独的文件。
因为Redis为每一个多路复用函数库都实现了相同的API,所以Redis的多路复用底层实现是可以进行互换的,在编译时自动选择系统中性能最高的IO多路复用函数库作为Redis底层的IO多路复用程序的实现。
当套接字发送事件时,IO多路复用程序会监听该事件,并且为套接字关联其需要的事件处理器。
事件的类型
IO多路复用程序可以监听多个套接字的事件,事件包括下面的两种
- ae.h/AE_READABLE事件
- ae.h/AE_WRITABLE事件
这两类事件和套接字之间的对应关系如下
- AE_READABLE(可读状态):当套接字产生AE_READABLE事件时,表示套接字变得可读,即服务端可以读取套接字里面的内容,即用户端那边进行了write操作、close操作或者connect操作。
- AE_WRITEABLE(可写状态):当套接字产生AE_WRITEABLE事件时,表示套接字变得可写,即服务端可以往套接字写入内容,给用户端看,即用户端那边进行了Read操作。
IO多路复用程序允许服务器同时监听套接字的两种事件,而且如果一个套接字同时产生了两种事件,如果套接字同时出现了这两种事件时,当IO多路复用程序将套接字传给文件事件派发器时,会优先处理AE_READABLE再处理AE_WRITEABLE,即会优先进行读取套接字(读取套接字内容,往服务器写入数据),然后再往套接字写入(从服务器读取数据,写入到套接字中)
文件事件的处理器
Redis为文件事件编写了多个处理器,这些事件处理器分别用于实现不同的网络通信需求
- 为了对连接服务器的各个客户端进行应答,服务器要为监听的套接字关联连接应答处理器
- 为了接收客户端传来的命令请求,服务器要为客户端套接字关联命令请求处理器
- 为了向客户端传回命令的执行结果,服务器要为客户端套接字关联命令回复处理器
- 当主服务器和从服务器进行复制操作时,主从服务器都需要关联特别为复制功能编写的复制处理器
连接应答处理器
该处理器用于对连接服务器监听套接字的客户端进行应答(即套接字被服务器监听的客户端)。
当Redis服务器进行初始化的时候,程序会将这个连接应答处理器和服务器监听套接字的AE_READABLE事件关联起来,当有客户端用函数连接服务器监听套接字的时候(即客户端连接上服务器),该套接字就会产生AE_READABLE事件,然后经由IO多路复用程序和文件事件派发器,引发连接应答处理器执行,并执行相应的套接字应答操作。

命令请求处理器
这个处理器负责从套接字中读入客户端发送的命令请求内容。
当一个客户端通过连接应答处理器成功连接到服务器之后,服务器会将客户端连接的套接字的AE_READABLE事件和命令请求处理器关联起来,当客户端向服务器发送命令请求的时候,套接字就会产生AE_READABLE事件,并且引发命令请求处理器执行,然后执行相应的套接字读入操作(读取用户的输入)。
命令回复处理器
该处理器负责将服务器执行命令后得到的命令回复通过套接字返回给客户端
当服务器有命令回复需要传送给客户端的时候,服务器会将客户端套接字的AE_WRITABLE事件和命令回复处理器关联起来,当客户端那边准备好接收服务器传回的命令回复时,就会产生AE_WRITABLE事件,然后引发命令回复处理器执行,然后执行相应的套接字写入操作。
当命令回复发送完毕之后,服务器就会解除命令回复处理器与客户端套接字的AE_WRITABLE事件之间的关联。
完整的连接过程
Redis初始化,产生连接套接字,服务器开始监听连接套接字,并且该套接字的AE_READABLE事件会关联连接应答处理器,此时客户端连接服务器,连接的是套接字,套接字产生AE_READABLE事件,服务器监听到该事件,IO多路复用程序监听到该事件,将套接字发到阻塞队列里面,然后再给文件事件派发器,再对应给连接应答处理器处理,处理完后就创建客户端套接字,并将客户端套接字的AE_READABLE事件与命令请求处理器进行关联,让客户端可以向主服务器发送命令请求。
之后,客户端向主服务器发送命令请求的时候,是发送到新建的客户端套接字,然后命令请求会让套接字产生AE_READABLE事件,该套接字因为关联了命令请求处理器,所以会交由命令请求处理器去执行,此时是会有命令回复的,所以,还需要将套接字的AE_WRITEABLE事件与命令回复处理器进行关联,当客户端那边尝试读取命令回复的时候,对应的客户端套接字将产生AE_WRITEABLE事件,触发命令回复处理器执行,为了不影响之后的AE_WRITEABLE事件的处理,命令回复处理器执行完后,会解除命令回复处理器与AE_WRITEABLE事件的关联。

时间事件
Redis的时间事件分为以下两类
- 定时事件:让一段程序在指定的时间之后执行一次,比如30秒之后执行。
- 周期性事件:让一段程序在指定的时间之后执行一次,比如每天晚上12点。
一个时间事件主要由以下三个属性组成:
- id:服务器为时间事件创建的全局唯一ID(标识号),该ID是从小到大按顺序递增的,即新时间事件的ID会比旧事件的ID号要大
- when:毫秒精度的UNIX时间戳,记录了时间事件执行时候的时间戳(无论是定时任务还是周期性任务,都会有一个准确执行的UNIX时间戳)
- timeProc:时间事件处理器,是一个函数,当时间事件到达后,就会调用时间事件处理器去处理事件
一个时间事件是定时事件还是周期性事件,取决于时间事件处理器的返回值:
- 如果事件处理器返回值是ae.h/AE_NOMORE,那么这个事件就是定时事件,该事件在达到一次之后就会被删除,之后不再被到达,相当于事件过期了
- 如果事件处理器返回值是一个非AE_NOMORE的整数值,那么这个事件就是周期时间事件,当事件在达到之后,并不会被删除,而是更新when属性,让这个事件在指定时间之后又会到达。
时间事件的实现
服务器将所有时间事件都放在一个无序链表中,每当时间事件执行器运行时,就遍历整个链表,查找所有已到达的时间事件(通过对比当前UNIX时间戳和时间事件的when属性),然后调用时间事件里面的时间事件处理器。
回顾前面提到过,对于过期删除策略时,对于定时删除是无法实现的,原因在于时间事件存放在无序链表中的,会占用资源,而且执行时间事件时会遍历整个无序链表,需要 O ( N ) O(N) O(N)的复杂度。
无序链表是指,存放的时间事件并不是按when来进行排序的,而是按ID逆序排的,比如第一个时间事件的ID为1,第二个时间事件ID为2,那么无序链表上的头结点第一个时间事件的ID就为2(采用头插法),但并不是根据when进行排序,所以当执行时间事件时,需要遍历整个无序链表来确保已到达时间点的时间事件可以全部被执行。
下面是一个存储时间事件的无序链表
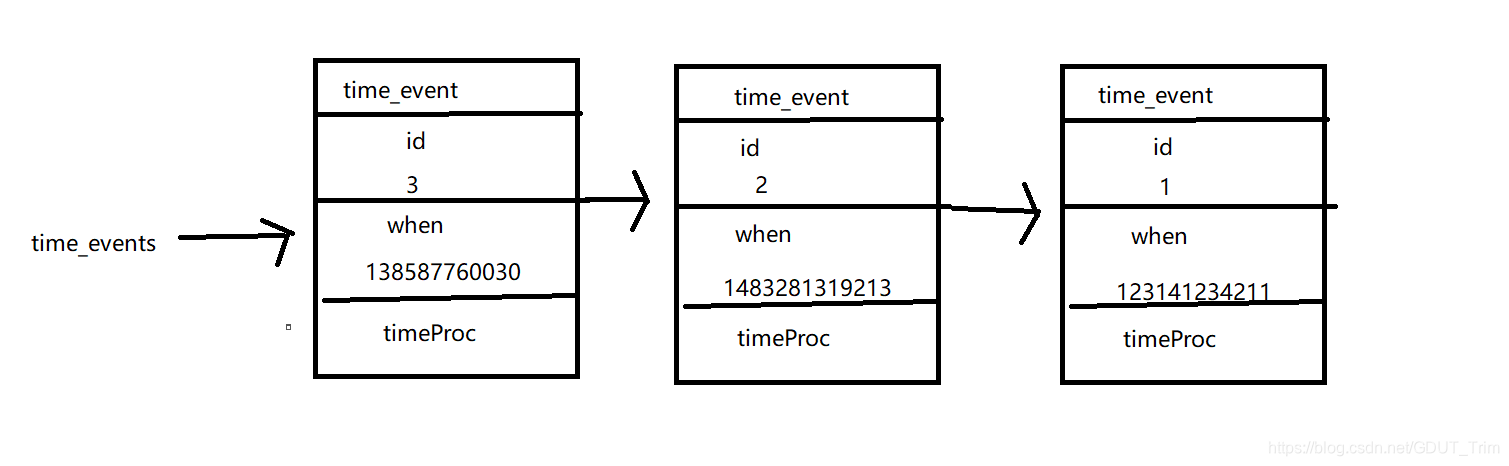
注意
无序链表并不影响时间事件处理器的性能,因为在当前版本中,正常模式下的Redis服务器只是用一个serverCron时间事件,即使在benchmark模式下,服务器也只使用两个时间事件,在这种情况下,服务器几乎是将无序链表退化成一个指针来用了(长度太短,一个指针即一个结点就存储完所有时间事件了),所以使用无序链表去保存,也不会消耗很多资源,并不会影响事件执行的性能。
ServerCron函数
Redis服务器通常是持续运行的,所以会定期对自身的资源和状态进行检查和调整,这样才可以确保服务可以长期稳定地运行下去,这些定期操作由redis.c/serverCron函数负责执行的,主要工作包括如下这些:
- 更新服务器的各类统计信息,比如时间、内存占用、数据库占用情况等
- 清理数据库中的过期键值对(定期删除策略)
- 关闭和清理连接失效的客户端
- 尝试进行AOF或RDB持久化操作(前面提到过,会进行判断,RDB根据save选项,AOF根据appendfsync选项)
- 如果服务器是主服务器,那么对从服务器进行定期同步
- 如果处于集群模式,对集群进行定期同步和连接测试
Redis服务器默认规定serverCron每秒运行10次,这个次数可以通过配置文件里面的hz选项来进行调整

事件的调度与执行
Redis中存在文件事件和时间事件,这是两种不同的事件,所以Redis需要进行事件调度,规定何时处理这两种事件,以及花多少时间去进行处理
事件的调度由ae.c/aeProcessEvents函数负责
def aeProcessEvents():
//获取到达时间离当前时间最接近的时间事件,通过遍历无序链表获取
time_event = aeSearchNearestTimer();
//计算还剩多少毫秒执行最接近的时间事件
//通过时间事件的when属性减去当前unix时间戳
remaind_ms = time_event.when - unix_ts_now();
//如果事件已经到达,则remaind_ms为0或者为负数
//如果为负数就要进行处理
if(remaind_ms < 0): remaind_ms = 0;
//根据remaind_ms的值,创建timeval结构
timeval = create_timeval_with_ms(remaind_ms)
//现在会进行阻塞,阻塞的时间由timeval控制,即由最近的时间事件还剩多少秒执行的时间决定
//如果remaind_ms的值为0,那么aeApiPoll调用之后会立马返回,不会进行阻塞
aeApiPoll(timeval)
//处理所有已产生的文件事件
//如果时间没有到达,会停留在这里继续等待文件事件
//所以这里这一步是,处理该时间段内产生的所有文件事件
//这个函数是不存在的,这里只是方便表示,其实处理文件事件的代码是直接写在aeProcessEvents函数里面的
processFileEvents();
//处理所有已到达的时间事件
//通过遍历找已到达时间的时间事件,并执行
processTimeEvents();
End aeProcessEvents;
将aeProcessEvents函数置于一个循环里(关机才停止循环),就构成了Redis服务器的主函数了
调度规则
- aeApiPoll函数的最大阻塞时间由到达时间最接近当前时间的时间事件决定,这个方法可以避免服务器长时间对时间事件的无序链表进行遍历,即进行频繁的轮询,也可以确保aeApiPoll函数不会阻塞太长时间,从而影响了文件事件的执行
- 因为文件事件是随时、随机发生的,所以当未有任何时间事件到达时,即设置的阻塞时间还未到达,就会继续等待文件事件的产生,然后执行,然后慢慢的,到达了指定时间,就会执行已到达时间的时间事件,然后重新开始循环
- 对文件事件和时间事件的处理都是原子、同步、有序,服务器不会中途停止对某一事件的执行,也不会对事件进行抢占,因此,不管是时间事件的处理器还是文件事件的处理器,都会尽可能地减少阻塞时间,早点执行完将CPU让给另一个事件,即让出执行权。
- 比如说,时间事件会将一些非常耗时的持久化操作用一个新的进程去执行(AOF、RDB)
- 又比如说,当文件事件的命令回复处理器在写入命令回复到客户端的套接字时,如果写入字节超过了某个某个预设常量,那么将会跳出,等下一次再写入
- 因为时间事件在文件事件之后执行的,并且事件之间不会出现抢占线程,所以时间事件的实际处理时间通常会比设置的时间稍晚一点。
重点
- Redis服务器是一个事件驱动程序,整个服务器处理的事件分为时间事件和文件事件
- 文件事件处理器是基于Reactor模式实现的网络通信程序,即可以接收多个输入,然后通过事件驱动,将事件采用IO多路复用方式交给处理器执行
- 文件事件是对套接字操作的抽象,当套接字状态改变时,文件事件也会改变状态,套接字的状态可以变为可应答(acceptable)、可写(writable)或者可读(readable),相应的文件事件也会产生
- 文件事件可以分为READABLE、WRITEABLE两种
- 时间事件可以分为定时事件和周期性事件
- 服务器一般情况下执行的时间事件只有serverCron函数,所以无序链表存储时间函数基本不会对执行时间函数过程造成影响
- 文件事件和时间事件之是合作关系,服务器会轮流执行这两种事件,并且不会发生抢占

















 3082
3082

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









