




 Solr是一款基于Lucene的高性能全文搜索服务器,提供高级搜索功能,支持高通量流量,具备XML和HTTP标准接口,拥有管理界面并可扩展。其目录结构包括bin、contrib、docs等,每个core包含conf和data目录,用于配置和数据存储。Solrj是Java客户端库,用于对索引库进行增删改查操作。可以通过修改solr.xml注册多个core。
Solr是一款基于Lucene的高性能全文搜索服务器,提供高级搜索功能,支持高通量流量,具备XML和HTTP标准接口,拥有管理界面并可扩展。其目录结构包括bin、contrib、docs等,每个core包含conf和data目录,用于配置和数据存储。Solrj是Java客户端库,用于对索引库进行增删改查操作。可以通过修改solr.xml注册多个core。
1.solr的基本概念
导读模块:Lucene是基本上能满足我们的需求,但是针对特殊的使用场景和个性化的需求lucene还是显的有些吃力,例如搜索到数据之后的高亮显示,例如数据的多种查询等lucene都是略显吃力,于是在这样的大环境下solr出现了。
1.1 Solr:
是一个高性能,采用Java5开发,基于Lucene的全文搜索服务器。同时对其进行了扩展,提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面,是一款非常优秀的全文搜索引擎
简而言之:solr其实就是一款能够实现全文检索的软件
1.2 Solr的特点/优点:
①高级的全文搜索功能;
②专为高通量的网络流量进行的优化;
③基于开放接口(XML和HTTP)的标准;
④综合的HTML管理界面;
⑤可伸缩性-能够有效地复制到另外一个Solr搜索服务器;
⑥使用XML配置达到灵活性和适配性;
⑦可扩展的插件体系
2.solr的简介与目录结构
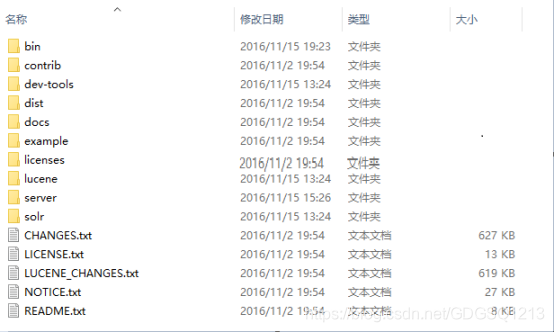
(1)bin:是脚本的启动目录
(2)contrib:第三方包存放的目录
(3)dev-tools:跟开发工具相关的包
(4)dist:编译打包后存放目录,即构建后的输出产物存放的目录
(5)docs:solr文档的存放目录
(6)example:示范例子的存放目录,这里展示了DIH,即数据导入处理的例子
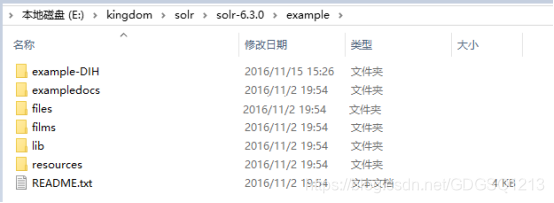
这里包含了core实例
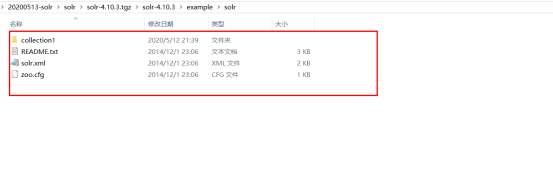
每一个core实例的结构都是这样的
(7)licenses:权限相关的
(8)lucene:solr基于Lucene开发,本身是lucene代码的目录,但是构建后都为空,相关东西已经到jar包中
(9)server:即solr搜索引擎框架,基于jetty web服务器开发的。包含jetty服务器的配置。(这个目录就类似于一个包含了tomcat服务器,里面有一个基于solr的web工程)
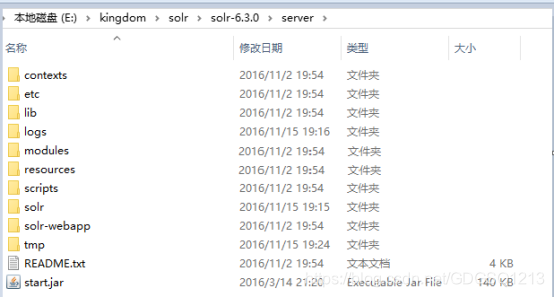
contexts:jetty的环境
etc:jetty的配置文件
lib:jetty服务器的jar包
logs:日志文件
modules:jetty的启动模式
resources:资源文件
scripts:脚本文件
solr:solr服务器的配置文件,solr基于jetty服务器开发的
solr-webapp:solr的web工程
tmp:临时文件
start.jar:启动jar包。通过java命令就可以启动一个基于jetty服务器的web工程
(10) solr:solr源码路径,编译构建后,已经打成jar包。此目录为空
2、部署到tomcat
看下一篇文章如何将solr部署到tomcat中
3、了解core
core交由solr管理,solr服务器框架中可以包含多个core实例,每个core有自身的配置文件及数据。
解压后的文件/example/solr/collection1就是一个core,这个core由/example/solr/solr.xml管理。
如图:
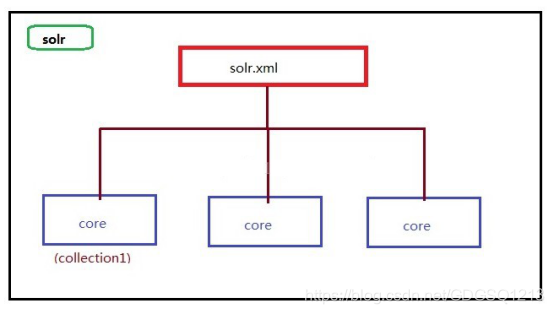
一个core如果想让solr管理,就需要注册到solr.xml配置文件中,solr.xml配置如见如下:
<?xml version="1.0" encoding="UTF-8" ?>
<solr persistent="true">
<cores defaultCoreName="collection1" adminPath="/admin/cores" zkClientTimeout="${zkClientTimeout:15000}" hostPort="8983" hostContext="solr">
<core loadOnStartup="true" instanceDir="collection1" transient="false" name="collection1"/>
</cores>
</solr>
4、创建多个core
在实际的项目中,有时候一个solr下面不可能只有一个core,会有多个。比如企业搜索、产品搜索等等。这时你可以复制一份或多份/example/solr/collection1到你的solr home中,并改成你想要的文件名,最后把新添加的core注册到/example/solr/solr.xml中:
<?xml version="1.0" encoding="UTF-8" ?>
<solr persistent="true">
<cores defaultCoreName="collection1" adminPath="/admin/cores" zkClientTimeout="${zkClientTimeout:15000}" hostPort="8983" hostContext="solr">
<core loadOnStartup="true" instanceDir="collection1" transient="false" name="collection1"/>
<core loadOnStartup="true" instanceDir="db" transient="false" name="db"/></cores> </solr>
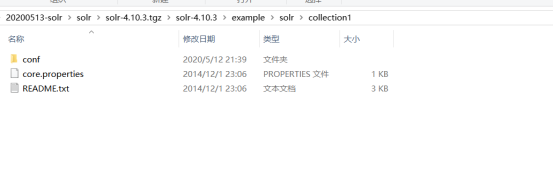
5、认识core的目录结构
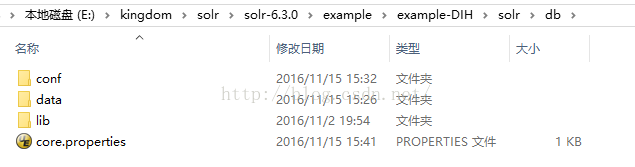
每个core中都有两个文件,conf和data
conf:主要用于存放core的配置文件,
(1)、schema.xml用于定义索引库的字段及分词器等,这个配置文件是核心文件
(2)、solrconfig.xml定义了这个core的配置信息,比如:
<autoCommit>
<maxTime>15000</maxTime>
<openSearcher>false</openSearcher>
</autoCommit>
定义了什么时候自动提交,提交后是否开启一个新的searcher等等。
data:主要用于存放core的数据,即index-索引文件和log-日志记录。
3.Solrj实现对索引库的增删改查
1.查询


















 3070
3070

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









