




 本文详细介绍了如何在VMware中为Linux虚拟机增加硬盘空间,并使用gparted工具进行分区扩容。首先在VMware中修改硬盘大小,接着安装gparted。在确保有未分配空间的情况下,通过gparted调整一级目录和子目录的大小,例如将/dev/sda2和/dev/sda6的容量进行调整。最后,保存分区变更,完成磁盘扩容操作。
本文详细介绍了如何在VMware中为Linux虚拟机增加硬盘空间,并使用gparted工具进行分区扩容。首先在VMware中修改硬盘大小,接着安装gparted。在确保有未分配空间的情况下,通过gparted调整一级目录和子目录的大小,例如将/dev/sda2和/dev/sda6的容量进行调整。最后,保存分区变更,完成磁盘扩容操作。
linux磁盘扩容
一、在VMware中修改硬盘大小
修改硬盘大小之前必须删除当前虚拟机的快照才行(记得定时定项目保存你的虚拟机快照!!!这是一个好习惯)
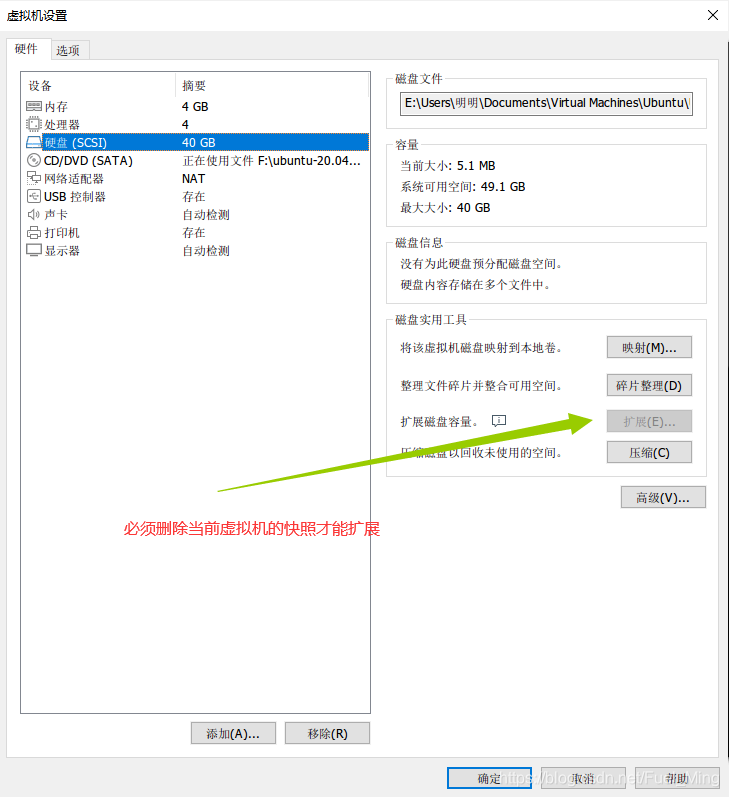
二、安装gparted
sudo apt-get install gparted
三、使用gparted修改分区大小
如何使用
1. 同级目录有未分配空间时才可以resize
2. 上级目录有未分配空间时才可以给更改子目录的大小
四、如何使用gparted给分区扩容
1. 在第一步操作完之后,打开gparted可以看到如图所示红框部分应该有一段灰色区域表示未分配空间
因为我这边已经操作过了,所以只能在图中用红框示意一下:
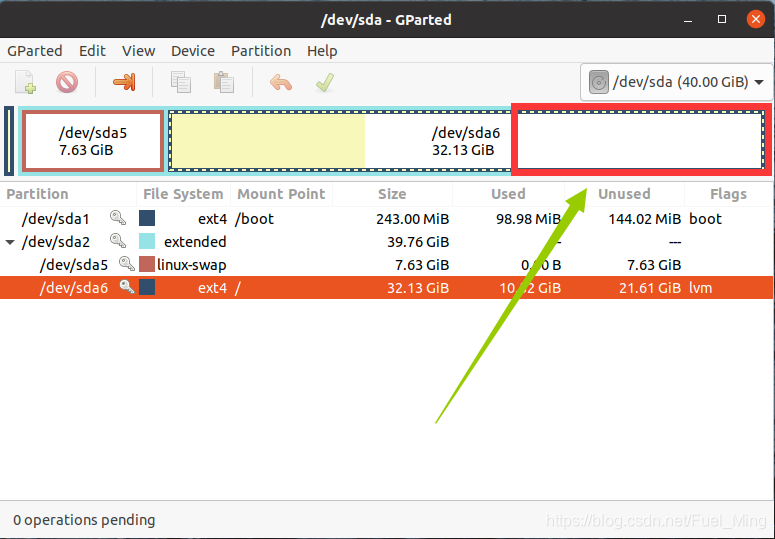
2. 这是就需要将灰色空间所示意的未分配空间分配到一级目录中,如图4-1所示:
图中所示一级目录(应该是分区)为:
dev/sda1、dev/sda2
如果你还有别的分区时可以根据你的需求操作接下来的步骤,我需要修改sda2的大小,之前只有12G的大小。
图4-1是我已经修改后的大小了
① 右击/dev/sda2,选择resize
② 修改New Size的大小40716,就是你修改完之后这个分区的大小,然后点击下一步Resize/Move(也可以直接拖动上边的小绿框直接修改大小)
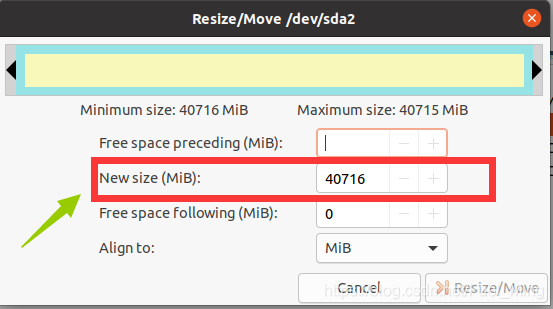
③ 执行完上一步之后,sda2就多了我加的20G空间,但是到这一步还没有完成,需要把这20G大小的硬盘再具体分配到你的下一级分区中,同样对sda6执行上述操作,最终点击保存图4-4即可,最终的磁盘分区就是图1-1所示的样子了。




















 2060
2060

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











