






一、什么是token
要将文本内容作为Transformer的输入,最符合直觉的方式是用Unicode编码。(介绍Unicode:A Programmer’s Introduction to Unicode – Nathan Reed’s coding blog,这篇博客底下的附录网页内容也很精彩)。但是,每个字节对应一个编码值,这会导致输入的长度过于长。然而这会限制模型长程依赖关能力系,超出一定的范围会导致一些上下文信息的丧失。
用token代替字节对应的编码作为模型的输入,显然更合适
一个token能代表多个byte。 可视化tokens的网站 :https://tiktokenizer.vercel.app/?model=cl100k_base

在LLM中,token本质上是在文本中的常见字符序列,不受严格规则或语言语义的约束。此外,token可以包括任何符号,而不仅仅是字母。分词器会将文本中的每个字符都分配给一个token,包括标点符号、数字、空白字符,甚至是表情符号。
二、核心思想——BPE(Byte_pair_encoding)
迭代合并出现频率高的字符对。
aaabdaaabac => ZabdZabac(Z=aa)
ZabdZabac => ZYdZYac (Y=ab, Z=aa)
ZYdZYac => XdXac ( X=ZY, Y=ab, Z=aa)
Tokenizer 采用BPE算法来形成词汇表,然后使用词汇表对字符串进行encode,并可decode回字符串。
核心代码
def get_stats(ids, counts=None):
"""
Given a list of integers, return a dictionary of counts of consecutive pairs
Example: [1, 2, 3, 1, 2] -> {(1, 2): 2, (2, 3): 1, (3, 1): 1}
Optionally allows to update an existing dictionary of counts
"""
counts = {} if counts is None else counts
for pair in zip(ids, ids[1:]): # iterate consecutive elements
counts[pair] = counts.get(pair, 0) + 1
return counts就像注释中所说的,get_stats函数实现给一系列的整数,返回一个字典,形式为——连续的pair:出现的次数
def merge(ids, pair, idx):
"""
In the list of integers (ids), replace all consecutive occurrences
of pair with the new integer token idx
Example: ids=[1, 2, 3, 1, 2], pair=(1, 2), idx=4 -> [4, 3, 4]
"""
newids = []
i = 0
while i < len(ids):
# if not at the very last position AND the pair matches, replace it
if ids[i] == pair[0] and i < len(ids) - 1 and ids[i+1] == pair[1]:
newids.append(idx)
i += 2
else:
newids.append(ids[i])
i += 1
return newidsmerge函数,用新的整数idx替换原来ids中的pair。这里的pair一般是字典中key最大的,即出现次数最多的,可以用一个max方法获取。
以上是核心的函数。有了这些,就可以完成encode和decode任务
def train(self, text, vocab_size, verbose=False):
assert vocab_size >= 256
num_merges = vocab_size - 256
# 输入文本预处理
text_bytes = text.encode("utf-8") # 转换为原始字节
ids = list(text_bytes) # 转换为范围在 0..255 的整数列表
# 迭代合并最常见的字符对以生成新token
merges = {} # (int, int) -> int,记录字符对与新token的映射关系
vocab = {idx: bytes([idx]) for idx in range(256)} # int -> bytes,初始化词汇表
for i in range(num_merges):
# 统计每个连续字符对的出现次数
stats = get_stats(ids)
# 找到出现次数最多的字符对
pair = max(stats, key=stats.get)
# 创建一个新token:分配下一个可用的id
idx = 256 + i
# 将列表中的所有该字符对替换为新token
ids = merge(ids, pair, idx)
# 保存合并记录
merges[pair] = idx
vocab[idx] = vocab[pair[0]] + vocab[pair[1]]
# 如果verbose为True,打印合并的过程
if verbose:
print(f"merge {i+1}/{num_merges}: {pair} -> {idx} ({vocab[idx]}) had {stats[pair]} occurrences")
# 保存类变量
self.merges = merges # 在encode()中使用
self.vocab = vocab # 在decode()中使用
def decode(self, ids):
# 给定id列表(整数列表),返回解码后的Python字符串
text_bytes = b"".join(self.vocab[idx] for idx in ids)
text = text_bytes.decode("utf-8", errors="replace")
return text
def encode(self, text):
# 给定字符串文本,返回对应的token id列表
text_bytes = text.encode("utf-8") # 转换为原始字节
ids = list(text_bytes) # 转换为范围在 0..255 的整数列表
while len(ids) >= 2:
# 找到合并索引值最小的字符对
stats = get_stats(ids)
pair = min(stats, key=lambda p: self.merges.get(p, float("inf")))
# 注意:如果没有可用的合并操作,键值将导致每个字符对的值为正无穷,
# 此时min将选择列表中的第一个字符对(随意的结果)
# 我们可以通过检查是否在self.merges中来检测这种终止情况
if pair not in self.merges:
break # 没有其他可合并的字符对,结束循环
# 否则,合并最佳字符对(最小合并索引值)
idx = self.merges[pair]
ids = merge(ids, pair, idx)
return ids
三、gpt2中的Tokenizer
很多时候,一些词我们并不希望合并在一起,比如dog和一些标点符号:"dog.","dog!","dog?"(详见gpt2的论文),但是用naive的BPE方法将他们合并在了一起。为了强制使这些merge不发生,用到一些正则化的方法:

split出来的每个部分再分别被tokenizer单独处理。

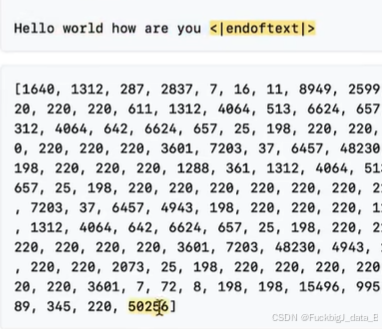
图中注释清晰的展示tokens的组成:50257 = 256 + 50000 + 1
四、more Tokenizer
4.1 tiktoken库(openai用的)
# match this
import tiktoken
enc = tiktoken.get_encoding("cl100k_base") # this is the GPT-4 tokenizer
ids = enc.encode("hello world!!!? (你好!) lol123 😉")
text = enc.decode(ids) # get the same text back详情见
minbpe/minbpe/gpt4.py at master · karpathy/minbpe · GitHub
4.2 sentencepiece (llama的tokenizer)
GitHub - google/sentencepiece: Unsupervised text tokenizer for Neural Network-based text generation.
当设置byte_fallback = True时,会预留一些id给未知的code point
五、vacab_size为什么不能无限长?
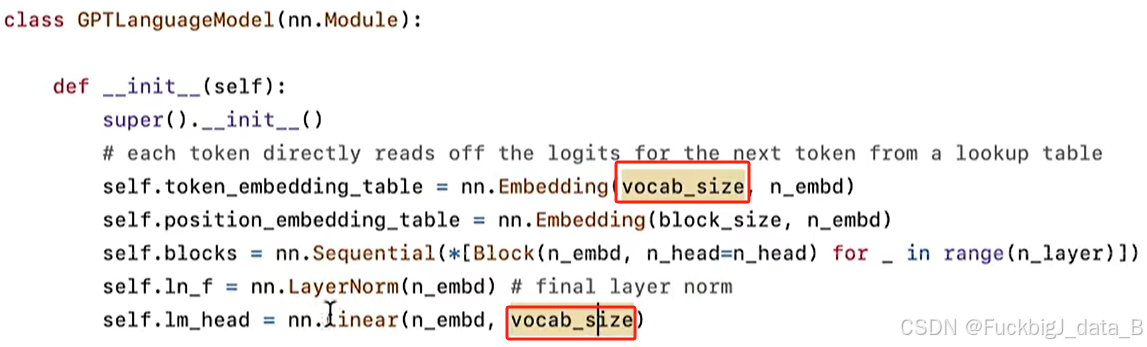
原因如下:
1、模型的计算成本将变高
2、同一文本量中,每个标记出现的次数也更少,每个标记的训练不充分
3、序列的增加,你会大幅缩减你的序列,很大的文本块被压缩成单个 token , 导致模型没有足够的机会考虑一定数量的字符串,transformer的前向传播不足以实际适当地处理该信息。
目前词汇表一般在1-10万量级
六、tokenizer对LLM能力的限制
下面这些问题是训练一个LLM会碰到的问题:
- 为什么大模型不能处理简单的字符串处理任务,例如反转?
因为tokenizer 切割成的是token, token 内部无法反转
- 为什么大模型在非英语语言任务方面的性能更差?
tokenizer 可能会把一个非英语的词切分成多个token, 例如中文 你好,
- 为什么大模型不擅长简单的算术?
因为计算的进位不是通过简单的token 预测概率得到,
- 大模型处理不存在的词,词汇表里没有的词,得不到回答
- SolidGoldMagikarp (挺好玩的,但是现在好像已经修正了)SolidGoldMagikarp (plus, prompt generation) — LessWrong
这是一个博主的用户名,在Tokenization的过程中经常用到,所以vacab_tabel中给了它一席之地。但是在训练时,数据集再也没有遇到这个词了,这个token的embedding向量在向前向后传播中也从来没有更新过。所以测试的时候遇到它,模型就懵逼了。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









