




 本文记录了一次在使用TensorFlow进行训练过程中遇到的内存错误及解决方法。错误发生在尝试分配一个超大尺寸的数组时,通过减少数据集的样本数量来解决此问题。
本文记录了一次在使用TensorFlow进行训练过程中遇到的内存错误及解决方法。错误发生在尝试分配一个超大尺寸的数组时,通过减少数据集的样本数量来解决此问题。
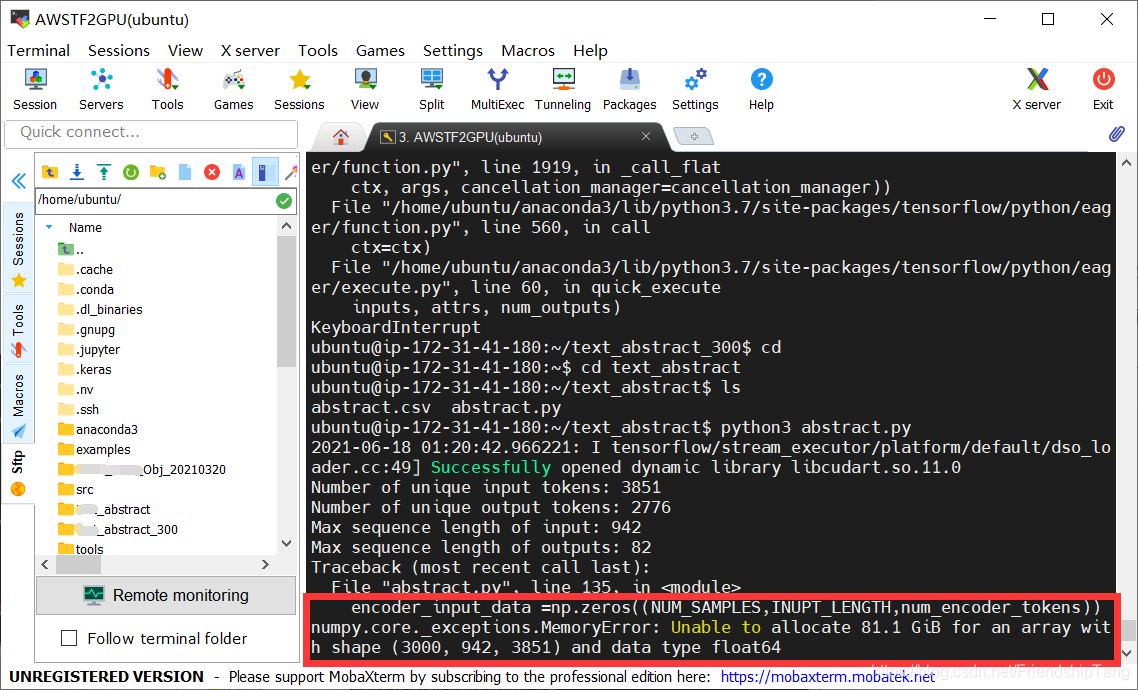
报错如下
Traceback (most recent call last):
File "abstract.py", line 278, in <module>
train()
File "abstract.py", line 253, in train
validation_split=0.2)
File "/home/ubuntu/anaconda3/lib/python3.7/site-packages/tensorflow/python/keras/engine/training.py", line 1100, in fit
tmp_logs = self.train_function(iterator)
File "/home/ubuntu/anaconda3/lib/python3.7/site-packages/tensorflow/python/eager/def_function.py", line 828, in __call__
result = self._call(*args, **kwds)
File "/home/ubuntu/anaconda3/lib/python3.7/site-packages/tensorflow/python/eager/def_function.py", line 888, in _call
return self._stateless_fn(*args, **kwds)
File "/home/ubuntu/anaconda3/lib/python3.7/site-packages/tensorflow/python/eager/function.py", line 2943, in __call__
filtered_flat_args, captured_inputs=graph_function.captured_inputs) # pylint: disable=protected-access
File "/home/ubuntu/anaconda3/lib/python3.7/site-packages/tensorflow/python/eager/function.py", line 1919, in _call_flat
ctx, args, cancellation_manager=cancellation_manager))
File "/home/ubuntu/anaconda3/lib/python3.7/site-packages/tensorflow/python/eager/function.py", line 560, in call
ctx=ctx)
File "/home/ubuntu/anaconda3/lib/python3.7/site-packages/tensorflow/python/eager/execute.py", line 60, in quick_execute
inputs, attrs, num_outputs)
KeyboardInterrupt
ubuntu@ip-172-31-41-180:~/text_abstract_300$ cd
ubuntu@ip-172-31-41-180:~$ cd text_abstract
ubuntu@ip-172-31-41-180:~/text_abstract$ ls
abstract.csv abstract.py
ubuntu@ip-172-31-41-180:~/text_abstract$ python3 abstract.py
2021-06-18 01:20:42.966221: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0
Number of unique input tokens: 3851
Number of unique output tokens: 2776
Max sequence length of input: 942
Max sequence length of outputs: 82
Traceback (most recent call last):
File "abstract.py", line 135, in <module>
encoder_input_data =np.zeros((NUM_SAMPLES,INUPT_LENGTH,num_encoder_tokens))
numpy.core._exceptions.MemoryError: Unable to allocate 81.1 GiB for an array with shape (3000, 942, 3851) and data type float64
解决方法
暂无很好方法解决,但可以通过减少数据集的样本数量,解决!!



















 2763
2763

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











