






 本文深入剖析了LinkedList的底层实现,揭示其由双向链表构成的本质,以及这种数据结构如何提升查询效率。通过源码解读,理解双向链表相较于单向链表的优势。
本文深入剖析了LinkedList的底层实现,揭示其由双向链表构成的本质,以及这种数据结构如何提升查询效率。通过源码解读,理解双向链表相较于单向链表的优势。
本文是源码入门浅析,突破我们对源码的恐惧。
希望大家不要看到源码就畏惧,一点点来,我们一样可以一步步成为大神。
结论:LinkedList 底层是由双向链表实现的。
链表不具有索引的概念,所以,遍历效率很低。
同时双向链表的查询效率可能高于单向链表。单向链表只能从头查到尾(一个方向);而双向链表可先判断查询元素离头近还是离尾近,从而选择近的一方开始查询,从而提升了查询效率。
之所以说可能,因为如果链表元素刚好是奇数个,且所查询元素刚好在正中间这种情况。
下面我们就通过源码的角度来验证以上的结论。
LinkedList 底层是由双向链表实现的
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
transient int size = 0;
/**
* Pointer to first node.
* Invariant: (first == null && last == null) ||
* (first.prev == null && first.item != null)
*/
transient Node<E> first;
/**
* Pointer to last node.
* Invariant: (first == null && last == null) ||
* (last.next == null && last.item != null)
*/
transient Node<E> last;
}
以上是 LinkedList 类的声明及成员变量,相信小伙伴看到first和last 可能就认为这是一个双向链表了。
但实际上,这两个 Node 节点的索引,是为了方便我们从头或从尾开始查找。first指向头节点,而last指向尾节点。
哪到底哪里可以看出LinkedList是双向链表呢?
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
这是LinkedList的内部类 Node。我们可以看到存在三个成员变量。
E item; //当前节点的元素
Node<E> next; //指向下一个节点的内存地址
Node<E> prev; //指向上一个节点的内存地址
图示:
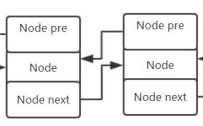
至此,我们的第一个结论就已经验证完毕了!
下面我们来验证第二个结论:
双向链表的查询效率可能比单向链表高
这里我们就看下双向链表的查询效率即可,看下它为什么比单向链表快?
public E get(int index) {
checkElementIndex(index); //检查元素的索引,如果超出,就会抛 IndexOutOfBoundsException
return node(index).item;
}
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {//这里是位运算,相当于 / 2
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
从以上 node( index ) 方法可看出,当前 index < 总大小/2 的时候,从头开始查找;否则,从尾部看是查找。
因为这是链表,不能直接通过 index 获取到对应的索引。所以,只能通过遍历的方式查询。
可能部分看官不太清除 size >> 1 的意思。下面我举个栗子大家就应该明白了。
| 十进制 | 二进制 |
|---|---|
| 4 | 0100 |
| 2 | 0010 |
可以看到 4 >> 1 ,就相当于 0100 -> 0010,向右移动了一位。
所以,4 >> 1 ,就等于十进制的 2
看到这里,想必各位看官对 LinkedList 的底层实现也有了一个比较好的认识。如果您对文章有什么建议,欢迎评论区留言。


















 759
759

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









