




1.需求:
在给定的订单数据,根据订单的分类ID进行聚合,然后按照订单分类名称,统计出某一天商品各个分类的成交金额,然后在结合商品分类表匹配上对应的商品分类字段,然后将计算结果保存到mysql中,要求结果如图所示:
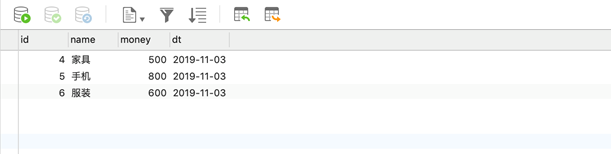
2.数据样例
{"cid": 1, "money": 600.0, "longitude":116.397128,"latitude":39.916527,"oid":"o123", }
"oid":"o112", "cid": 3, "money": 200.0, "longitude":118.396128,"latitude":35.916527}
{"oid":"o124", "cid": 2, "money": 200.0, "longitude":117.397128,"latitude":38.916527}
{"oid":"o125", "cid": 3, "money": 100.0, "longitude":118.397128,"latitude":35.916527}
{"oid":"o127", "cid": 1, "money": 100.0, "longitude":116.395128,"latitude":39.916527}
{"oid":"o128", "cid": 2, "money": 200.0, "longitude":117.396128,"latitude":38.916527}
{"oid":"o129", "cid": 3, "money": 300.0, "longitude":115.398128,"latitude":35.916527}
{"oid":"o130", "cid": 2, "money": 100.0, "longitude":116.397128,"latitude":39.916527}
{"oid":"o131", "cid": 1, "money": 100.0, "longitude":117.394128,"latitude":38.916527}
{"oid":"o132", "cid": 3, "money": 200.0, "longitude":118.396128,"latitude":35.916527}
字段说明:
oid:订单id,String类型
cid: 商品分类id,Int类型
money: 订单金额,Double类型
longitude: 经度,Double类型
latitude: 纬度,Double类型
2.商品分类表
分类信息
1,家具
2,手机
3,服装
3.idea中导入依赖
<properties> <maven.compiler.source>1.8</maven.compiler.source> <maven.compiler.target>1.8</maven.compiler.target> <scala.version>2.12.10</scala.version> <
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3275
3275

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









