








 本文介绍了验证链技术,一种通过要求模型提供证据链来减少大型语言模型生成虚假信息的方法。文章详细描述了验证链的工作原理,应用场景,以及其在提高模型可信度上的效果和局限性。
本文介绍了验证链技术,一种通过要求模型提供证据链来减少大型语言模型生成虚假信息的方法。文章详细描述了验证链的工作原理,应用场景,以及其在提高模型可信度上的效果和局限性。
一、前言
随着大型语言模型在自然语言处理领域取得了惊人的进步。相信深度使用过大模型产品的朋友都会发现一个问题,就是有时候在上下文内容比较多,对话比较长,或者是模型本身知识不了解的情况下与GPT模型对话,模型反馈出来的结果都是看似合理却不是我们需要的答案,实际上就是大模型出现了“幻觉”,即生成不真实的信息或虚构的回答。这对模型的可信度产生了负面影响。
验证链技术为减少模型中的幻觉提供了一种有效方法。它要求模型在生成每个断言时,同时提供一个证据链以支持该断言。这强制模型生成更加符合事实和逻辑的输出,减少臆造信息的概率。
在本文中,我将详细介绍验证链技术的工作原理,以及如何应用这一技术来减少大型语言模型生成的虚假信息。我们将探讨验证链的不同构建方法,以及它们对模型生成结果的影响。最后,我将讨论验证链技术在提高模型可信度方面的优势、存在的 LIMIT、以及未来的发展方向。
二、幻觉频繁发生的几种场景
在大型语言模型(LLM)中,幻觉频繁发生的几种典型场景包括:
2.1、开放域问答
在开放域问答中,LLM可能会自信地生成错误或虚构的答案。例如,当被问及一些模型不了解的专业知识问题时,LLM可能会自造信息来回答问题。
2.2、长文本生成
让LLM进行长文本的自由生成时,它可能会逻辑混乱,产生大量不真实的内容。例如让其编故事或创作文章时,就容易出现脱离事实的虚构内容。
2.3、将个人价值判断作为事实
LLM可能会将自己的个人观点、偏见作为客观事实来生成文本,从而产生与真实情况明显不符的输出。
2.4、数值预估
在进行数值预估时,LLM可能给出完全不合理的数字,比如被问及一座山的高度时却给出明显不准确的估算。
2.5、推理和多步触发
在需要进行多步推理时,LLM容易在逻辑上出现断层,导致最后的输出存在诸多幻觉。
这些都是LLM目前容易产生幻觉的场景。我们需要通过验证链等技术来约束模型,减少这种虚假信息的生成。
三、什么是验证链 (Cove)?
验证链是一项新技术,由Meta AI的研究人员 Shehzaad Dhuliawala 等人在论文《验证链减少大型语言模型中的幻觉》中提出。它结合了模型的提示和一致性检查。验证链(CoVe)背后的概念是,由大型语言模型(LLM)生成的回答可以用来验证自身。这种自我验证过程用于评估初始回答的准确性,并对其进行精炼以提高精度。要实现这一点,需要巧妙地构建和排序LLM提示。
该研究旨在解决大型语言模型产生可信但不正确信息的问题,即幻觉。研究人员提出了一种名为验证链(CoVe)的方法,首先模型生成初稿回答,然后创建问题来检查初稿中的事实,以无偏见地回答这些问题,并最终生成经过验证的最终回答。研究发现,验证链在各种任务中减少了幻觉的发生。
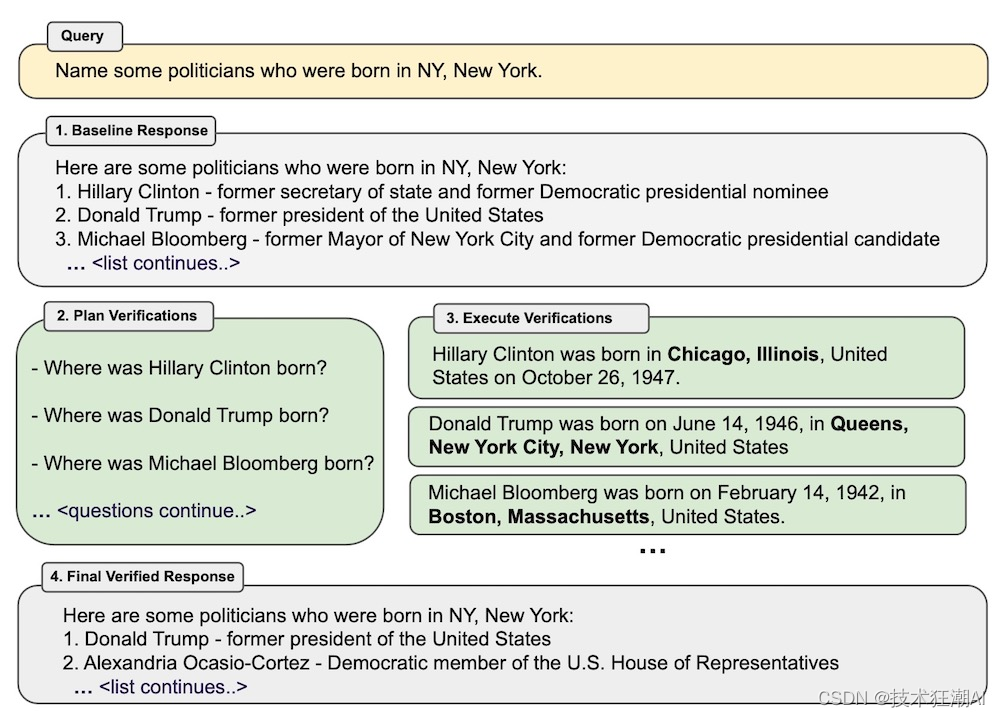
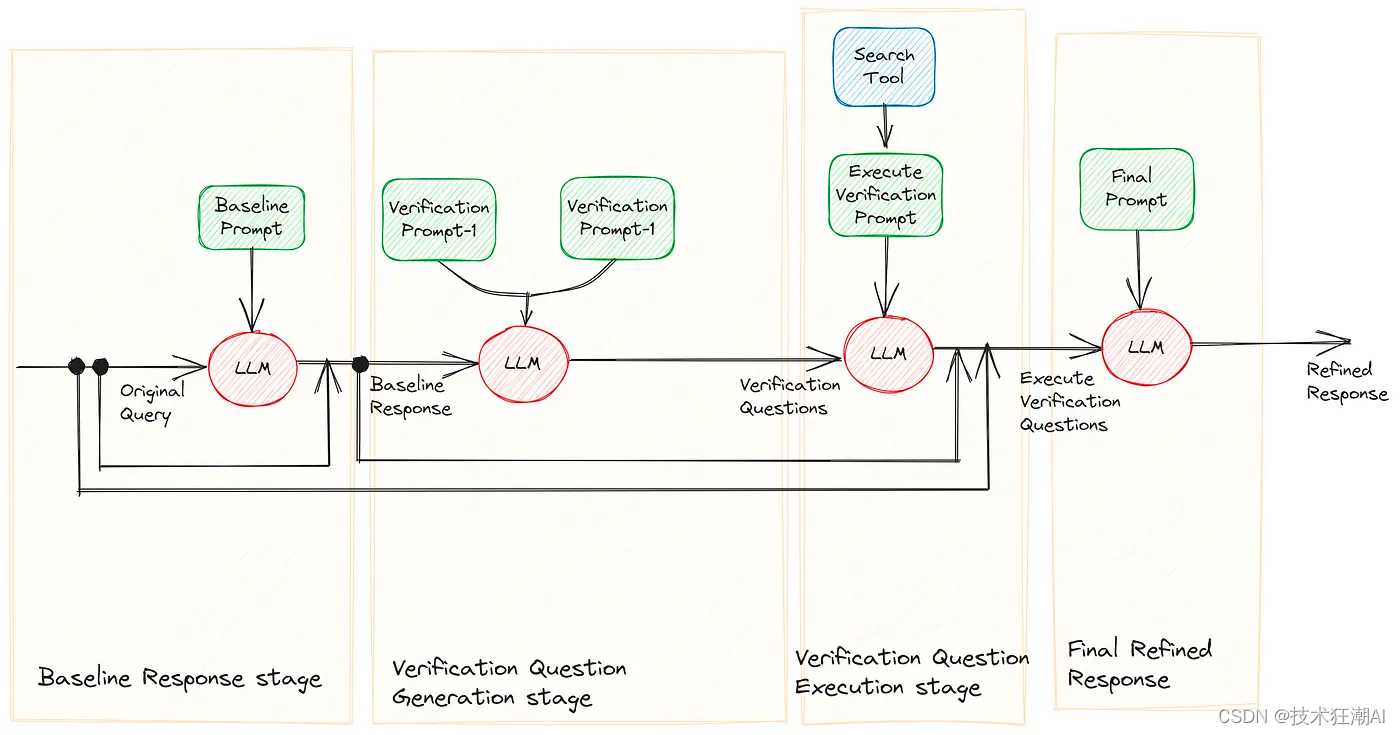
四、验证链 (CoVe) 减少幻觉的4个步骤
-
生成基准回答:从大型语言模型中获得一个简单的输出作为起点,无需任何其他特殊提示,以获得初始回答。这一初始步骤不仅作为验证链的起点,还作为通过验证链提升的基准。然而,由于这样的基准回答通常容易出现幻觉,CoVe方法旨在在后续阶段检测和纠正这些不准确之处。
-
计划验证问题:在给定原始查询和基准回答的条件下,模型被指示生成一组验证问题,旨在评估初始基准回答中所做的事实断言的准确性。重要的是强调,这些验证问题不是预定义的模板;相反,语言模型可以根据需要以任何适当的方式来表达它们。然而,这些验证问题应该以一种有助于改进基准回答的方式构建。
-
回答验证问题:大型语言模型通过多种变体(如联合、两步、分解和分解+修订)回答计划的验证问题,每种变体都有其独特的方法和复杂程度。这个验证过程可以包括通过网络搜索进行验证等工程技术/外部工具。同时,您可以在验证链的所有阶段依赖LLM本身,LLM将验证自己的回答。
-
生成最终验证的回答:利用这些答案,模型对初始草稿进行了改进,并生成了一个更准确的最终回答。
五、基于 LangChain 来测试验证链
作者引入的验证过程通过一系列的问题进行基准测试。这些问题被分为三个主要类别(尽管作者最初将它们分为四个类别):
-
维基数据与维基类别列表:这个类别涉及到期望以实体列表形式回答的问题。例如,像“哪些政治家出生在波士顿?”或者“能举出一些越南特有的兰花吗?”这样的问题,应该得到提供特定实体列表的答案。
-
多跨度 QA:这个类别的问题寻求多个独立的答案,每个答案都来自文本中不相邻的不同部分。一个例子是:“谁发明了第一台机械化印刷机,是在哪一年?”答案是“约翰内斯·古腾堡,1450年”。
-
长篇生成:这个类别主要包括作者基准测试中强调的传记性问题,但并不仅限于传记。任何需要详细或长篇回答的问题都属于此类别。
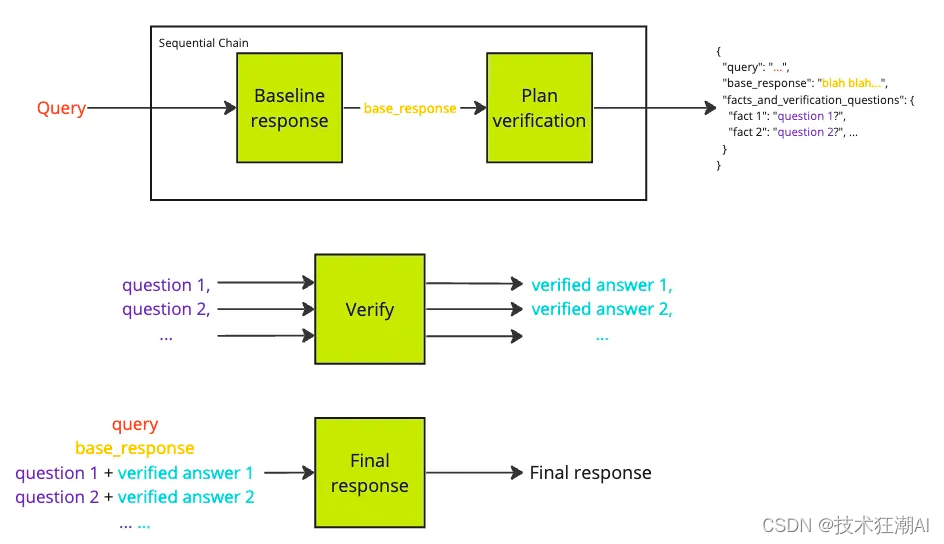
我已经按照原始论文中概述的四个阶段实施了 CoVe 管道测试。基于前面提到的问题类型,我建立了三个不同的 CoVe 链。此外,我还加入了一个路由机制,将原始查询引导到适当的链条。
路由器机制:当用户输入他们的查询或问题时,这个机制就开始运作。它将用户的问题分类为之前提到的三个类别之一:维基列表问题、多跨度问题或长篇问题。根据这种分类,路由器然后将问题引导到适当的链条,每个链条都专门设计来处理三种问题类型中的一种。这种分类是通过一个简单的少量提示设计实现的。你可以在这里获取更多关于提示的想法。
基线响应:这个阶段很直接,不需要任何提示制作。此时,用户的查询被 LLM 处理,得到我们称之为“基线响应”的结果。这个初始响应将随后被评估和精炼,以产生最终答案。你可以在这里获取更多关于所有类型问题的提示。
验证问题生成:这个阶段至关重要,需要精心制作和优化提示,以确保验证问题与原始查询无缝对接。如果这些验证问题偏离了主要意图,整个链条的目的可能会受到损害。为了更好地理解这一点,我们举一个例子。
基线响应:1. 萨蒂亚·纳德拉 (Microsoft 的 CEO),2. 桑达尔·皮查伊 (Google 的 CEO)3. 马克·扎克伯格 (Meta 的 CEO)
验证问题(第一套):1. 萨蒂亚·纳德拉是 Microsoft 的 CEO 吗?2. 桑达尔·皮查伊是 Google 的 CEO 吗?3. 马克·扎克伯格是 Meta 的 CEO 吗?
验证问题(第二套):1. 萨蒂亚·纳德拉是 Microsoft 的 CEO,他是印度裔吗?2. 桑达尔·皮查伊是 Google 的 CEO,他是印度裔吗?3. 马克·扎克伯格是 Meta 的 CEO,他是印度裔吗?
仔细观察两套验证问题,我们可以发现以下情况:
在第一套中,所有三个问题都会得到“是”的验证答案。最终精炼后的答案将包括基线响应中提供的三个名字。这并不是我们希望的结果,因为问题的主要目标是识别出印度裔的 CEO。第一套问题没有捕捉到这个特定的意图。
相反,第二套更符合我们的目标。例如,第三个验证问题将正确地排除马克·扎克伯格,因为虽然他是 Meta 的 CEO,但他并非印度裔。
因此,在此阶段,精确的提示工程和彻底的实验至关重要。关于各种问题类型的提示结构的进一步了解,你可以参考这里。
执行验证问题:这个阶段与前一个阶段同样重要。即使有高度准确的验证问题与主要目标对齐,最终精炼答案的质量也很大程度上取决于这个阶段。虽然完全依赖 LLM 来处理生成的验证问题,但一个人可以灵活地利用各种概念或外部工具来达到这个目的。在我的方法中,我使用了一个免费的搜索工具,“duckduckgo-search”,来获取答案。这些搜索结果然后作为 LLM 处理每个验证问题的参考上下文。替代方案包括更复杂的搜索工具,基于 RAG 的系统,数据库,或其他检索工具和机制来回答早期制定的验证问题。
最终精炼答案:这一步相对简单。它涉及利用所有的前面的数据(原始查询,基线响应,验证问题,及其各自的答案)来制定一个提供最终精炼答案的提示。参见示例提示以供参考。
六、CoVe 的实践结果
CoVe 的有效性在各种任务中进行了测试,包括Wikidata、Wikipedia分类列表、MultiSpanQA和长篇传记。结果还是很不错的:
-
在基于列表的任务中显著提高了准确性。
-
在闭卷问答中表现出色,F1分数提高了23%(这表示准确率和召回率都有所提高)。
-
长篇生成中事实得分提高了28%。
-
值得注意的是,通过CoVe,Llama 65B在长篇生成任务中超过了ChatGPT、InstructGPT和PerplexityAI等领先模型,标志着开源大型语言模型领域的重大成就。
七、CoVe 的改进方法
1️. 提示工程:改进任何LLM驱动的应用性能的主要方法之一是通过提示工程和优化。您可以查看我在GitHub上实现的所有提示。尝试进行自己的提示工程,在您的具体用例中进行实验。
2️. 外部工具:由于最终输出高度依赖于验证问题的答案,根据不同的用例,您可以尝试不同的工具。对于事实问答,您可以使用高级搜索工具,如Google搜索或serp API等。对于自定义用例,您可以使用RAG方法或其他检索技术来回答验证问题。
3️. 更多链条:我已经根据作者在研究中使用的三种问题类型(Wiki Data、多段问答和长篇问答)实现了三个链条。根据您的用例,您可以创建其他链条,以处理其他类型的问答方法,增加多样性。
4️. 人机交互(HIL):在许多LLM驱动的应用中,人在环(HIL)是一个重要的步骤。在您的特定应用中,可以将整个流程设计为将HIL纳入其中,无论是为了生成适当的验证问题还是回答验证问题,以进一步改进整体的CoVe流程。
八、Cove 方法的局限性
尽管CoVe采用了开创性的方法,但它并非没有限制。虽然它显著减少了幻觉,但并不能完全消除。模型仍有可能生成误导性信息。此外,幻觉可能以其他形式出现,例如在错误的推理过程中或在长篇回答中表达观点时。
幻觉的不完全消除:CoVe并不能完全消除生成内容中的幻觉,这意味着它仍然可能产生不正确或误导性的信息。
幻觉缓解的范围有限:CoVe主要解决直接陈述的事实不准确性形式的幻觉,但可能无法有效处理其他形式的幻觉,如推理错误或观点错误。
计算开销增加:在CoVe中生成和执行验证问题会增加计算成本,类似于其他推理方法(如思维链)。
改进的上限:CoVe的有效性受限于底层语言模型的整体能力,特别是其识别和纠正自身错误的能力。
九、总结
验证链(CoVe)方法在减少大型语言模型中的幻觉方面迈出了重要的一步,提高了它们在各种任务中的可靠性和准确性。通过使模型能够验证自己的回答,CoVe将我们带向了更可靠和无误的人工智能的目标,尽管仍然存在一些限制和挑战需要解决。
对于单个问题的答案包含的错误明显减少,从而使 CoVe 能够显着改进提示的最终输出。对于基于列表的问题,例如政治家的例子,Cove 可以将准确率提高一倍以上,从而显着降低错误率。
对于更复杂的问答场景,该方法仍然可以提高 23%,即使对于长格式内容,Cove 也可以将事实准确性提高 28%。然而,对于较长的内容,团队还需要检查验证答案是否不一致。
在他们的测试中,Meta 团队还可以证明指令调整和思维链提示不会减少幻觉,因此带有 CoVe 的 Llama 65B 击败了更新的指令调整模型 Llama 2。在较长的内容中,带有 CoVe 的模型也优于 ChatGPT 和 PerplexityAI,后者甚至可以收集其世代的外部事实。 Cove 完全利用模型中存储的知识来工作。
然而,在未来,该方法可以通过外部知识来改进,例如通过允许语言模型通过访问外部数据库来回答验证问题。
十、References
[1]. CHAIN-OF-VERIFICATION REDUCES HALLUCINATION IN LARGE LANGUAGE MODELS(https://arxiv.org/pdf/2309.11495v1.pdf)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











