 向量数据库:概念、用途与PostgreSQL扩展pgvector
向量数据库:概念、用途与PostgreSQL扩展pgvector





 文章介绍了向量数据库在处理高维数据和相似性搜索中的重要性,特别提到了PostgreSQL的扩展pgvector,它支持向量数据的存储和查询。向量数据库适用于自然语言处理、图像识别等多种场景,并通过欧几里得距离、余弦相似度等运算符进行相似性比较。pgvector提供索引支持和易于使用的SQL查询,是处理矢量数据的一个强大工具。
文章介绍了向量数据库在处理高维数据和相似性搜索中的重要性,特别提到了PostgreSQL的扩展pgvector,它支持向量数据的存储和查询。向量数据库适用于自然语言处理、图像识别等多种场景,并通过欧几里得距离、余弦相似度等运算符进行相似性比较。pgvector提供索引支持和易于使用的SQL查询,是处理矢量数据的一个强大工具。
一、介绍
随着基础模型的兴起,向量数据库的受欢迎程度也飙升。事实上,在大型语言模型环境中,向量数据库也很有用。
在机器学习领域,我们经常处理的是向量嵌入。向量嵌入是通过特定的机器学习模型运行对象的特征,将对象的上下文信息投射到潜在空间中来创建的。
为了在使用向量嵌入时能够表现得特别好,创建向量数据库是必要的。这方面的工作包括存储、更新和检索向量。当我们谈论检索时,通常是指检索与查询最相似的向量,这些向量与嵌入到同一潜在空间并传递到向量数据库中。这个检索过程被称为近似最近邻。
嵌入是由人工智能模型生成的,并且由于它们包含大量属性或特征,因此管理它们的表示可能很困难。在人工智能和机器学习的背景下,这些特征代表数据的许多元素,所有这些元素对于理解模式、相关性和底层结构都是必要的。
因此,我们需要专门为管理此类信息而开发的数据库。像Chroma-DB这样的向量数据库能够满足这一需求,因为它们提供了经过优化的嵌入式存储和查询功能,并且具备典型数据库所不具备的独立向量索引特性。此外,向量数据库还具备处理向量嵌入的专门能力,这是传统基于标量的数据库所不具备的。
PostgreSQL是一个强大的对象关系数据库系统,可在开源许可下使用。它已经积极开发了超过35年,这使得它在可靠性、稳健性和性能方面建立了良好的声誉。好消息是,除了外部扩展之外,PostgreSQL还支持向量。
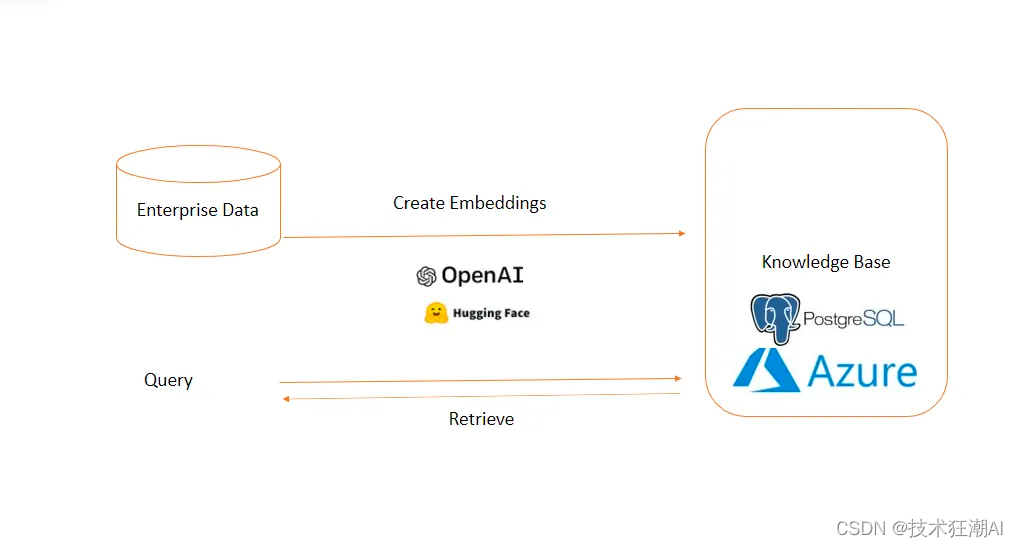
一些流行的向量数据库包括:Pinecone、Weviate、Chroma、Milvus、Faiss。尽管Redis、Cassandra等数据库并非向量数据库,但越来越多的数据库提供商开始提供ANN搜索功能。
二、什么是向量数据库
向量数据库是一种专门用于存储、管理和搜索向量数据的数据库。它以向量的形式存储数据,其中向量是抽象实体(如图像、音频文件、文本等)的数学表示。通过存储数据向量并使用向量之间的相似度度量,向量数据库可以实现高效、准确的数据搜索和分析。
下面显示了一个非常简单的示例。虽然顶部的两个句子的含义非常相似,但底部的句子却截然不同。向量数据库能够将这些句子编码为向量,然后找到接近的句子 - 这意味着它们是相似的。
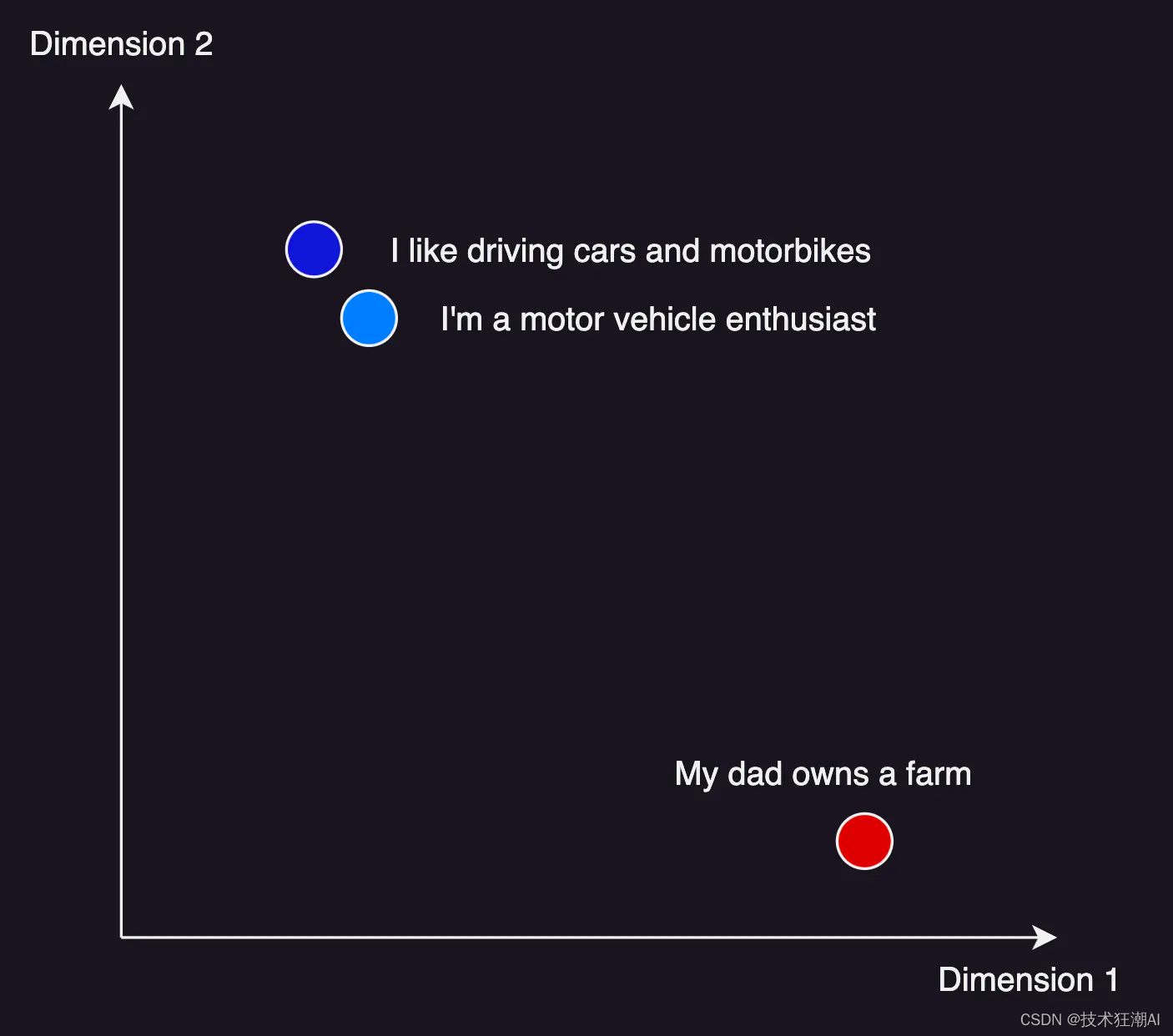
请记住,在实际应用中,我们拥有的维度远不止 2 个维度 - OpenAI 嵌入目前使用大约 1500 个维度来进行有意义的语言矢量化。
向量数据库的核心特点如下:
1)、向量表示:向量数据库将复杂的数据类型转换为向量表示,使得高维数据能够以多维空间中的点的形式表示。这种表示不仅具有高计算效率,还简化了数据点之间的比较和关联过程。
2)、基于相似性的搜索:向量数据库擅长
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3011
3011

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











