



本文旨在总结 HashTable, HashMap, ConcurrentHashMap 之间的区别
HashMap本身不是线程安全的
在多线程环境下使用哈希表可以使用:
- HashTable
- ConcurrentHashMap
1.HashTable
只需要给各种public方法 加上synchronized 关键字


相当于直接针对HashTable 对象本身加锁
- 如果多线程访问两个不同元素,都会引起锁竞争
- size属性也是通过synchronized 来控制同步 比较缓慢
- 一旦触发扩容,就由该线程完成整个扩容过程,此过程会涉及到大量的数据拷贝,效率很低
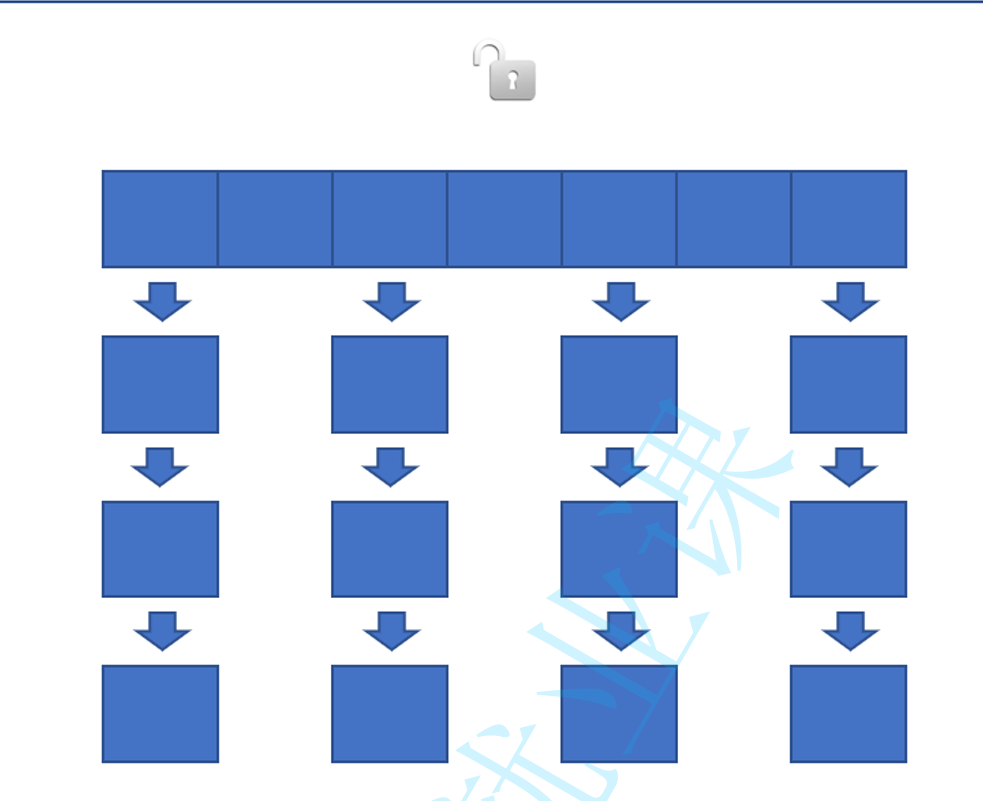
一个HashTable 只有一把锁
两个线程访问Hashtable中的任意数据 都会出现锁竞争
2.ConcurrentHashMap
相比于HashTable 做出一系列优化和改进(此处以 JDK1.8为例)
- 读操作没有加锁——使用volatile 保证从内存读取结果
- 写操作加锁——使用synchronized “锁桶”方式 以每个链表的头结点 作为锁对象 大幅降低锁冲突的频率(实际开发中,同一时刻 多个线程访问同一个链表的可能性比较低)
- 对size属性 使用原子类
- 优化扩容方式——化整为零:
- 发现需要扩容,创建一个新数组,同时搬运几个元素过去
- 扩容期间,新老数组同时存在
- 后续每个操作ConcurrentHashMap 的线程,都会参与搬运,每次搬运一小部分元素
- 搬完最后一个元素后 删去旧数组
- 此期间,插入只往新数组加
- 此期间,查找需要同时查新数组和老数组
- 确保每个操作的加锁时间不要太长
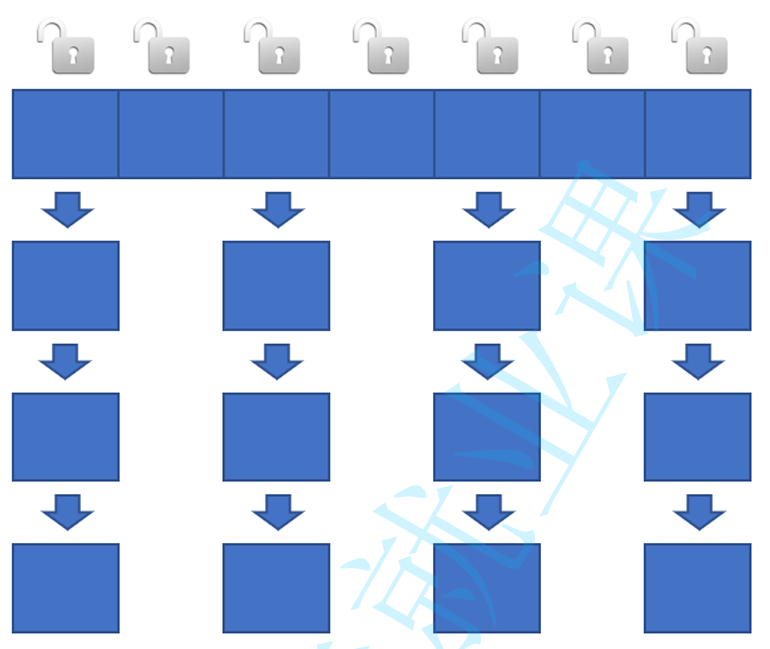
ConcurrentHashMap每个哈希桶 都有一把琐
只有两个线程访问的恰好是同一个哈希桶上的数据 才会出现锁冲突
3.相关重要概念
3.1ConcurrentHashMap的读是否要加锁,为什么?
读操作没有加锁,这样可以降低锁冲突的频率,同时为了保证读到刚修改的数据,使用volatile关键字
3.2锁分段技术
锁分段技术是JDK1.7采用的技术
将若干哈希桶 分为一段 给每一段加锁
其目的也是降低锁冲突的频率
当两个线程访问的数据恰好在一个段上的时候,才触发锁竞争
3.3ConcurrentHashMap在jdk1.8做了哪些优化?
取消使用分段锁,直接给每个哈希桶(链表)分配了一个锁
将原来 数组+链表 的实现方式改进成 => 数组+链表/ 红黑树
当链表较长(元素个数大于8个) 就转换成 红黑树
4.Hashtable和HashMap、ConcurrentHashMap之间的区别?
- HashMap :线程不安全 ,key可以是null
- HashTable :线程安全 使用synchronized 锁 HashTable对象 效率较低,key不允许为null
- ConcunrrentHashMap:线程安全 使用synchronized 锁每个链表头结点 锁冲突概率低 使用原子类,优化扩容方式,key不允许为null

















 1412
1412




 到【灌水乐园】发言
到【灌水乐园】发言







