




 本文介绍了一种基于图卷积网络(GCN)的地理定位模型,该模型结合文本和社交网络信息来提高用户地理位置预测的准确性。通过在三个基准数据集上的实验证明,即使在标记数据极少的情况下,该模型也能取得较好的效果。
本文介绍了一种基于图卷积网络(GCN)的地理定位模型,该模型结合文本和社交网络信息来提高用户地理位置预测的准确性。通过在三个基准数据集上的实验证明,即使在标记数据极少的情况下,该模型也能取得较好的效果。
#ACL 2018
CCF评级:A类
官方网站:ACL 2018
会议时间:2018/07/15 至 2018/07/20
会议地址:Australia

推荐理由:本文利用GCN将用户文本与网络结构信息整合,来达到获取更加准确的社交媒体用户地理位置定位。
论文核心: 本文解决的问题是社交媒体用户的地理位置定位问题。位置定位常常依赖于用户的IP地址,WIFI使用足迹以及GPS信息。但是第三方的服务软件通常是很难拿到这样的信息,所以他们基本只能依赖于地理定位的公共信息如推文和社交关系。这些信息繁多,噪声大,给定位造成很大困难。因此本文采用GCN配上一种"highway gates"机制来进行信息过滤,利用少量的有明确地理位置信息的监督样本,学习如何海量文本和社交关系中提取位置信息。
模型方法
对于每个节点,传统GCN的分层传播规则为:


各个参数的定义请具体参考引言中的论文。
该文在这个规则的基础上,加入了"highway gates"的过滤机制,解释为:将邻域信息中的噪声信息过滤,达到控制应该将多少邻域信息传递给节点的所需平衡。具体机制表示如下:

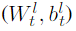 是"highway gates"的权重和偏置。
是"highway gates"的权重和偏置。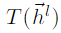 即为GCN中输出层
即为GCN中输出层 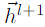 的门系数,这样最终的输出层
的门系数,这样最终的输出层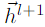 就是GCN的输出层,输入层的加权和。
就是GCN的输出层,输入层的加权和。
实验
- 数据集:
三个现有的Twitter用户地理位置数据集:GEOTEXT、TWITTER-US、TWITTER-WORLD。
- Baseline:
GCN-LP、MLP+TXT+NET
- 实验结果:

图3:比较50个训练样本的t-SNE可视化,这50个样本来自四个已经选好的用不同数据表示的GEOTEXT区域之一
图4:按照Median error,让GEO-TEX T,TWITTER-U S和TWITTER-WORL D的所有样品的一部分可用的标记数据在GCN,DCCA和MLP-TXT + NET模型的开发性能的效果。三个数据集的数据集大小分别为9k,440k和1.4k。
0 摘要:
社交媒体用户地理定位对于诸如事件检测等多种应用至关重要。在本文中,我们提出了基于图形卷积网络的多视图定位模型,它使用了文本网络上下文。我们将GCN与现有技术进行比较,以及我们提出的两个基线,并显示我们的模型或者在足够的监督可用时,与最先进的三个基准地理分布数据集竞争。我们还评估GCN的最小监督情景,并显示它优于基线我们发现highway network gates对于控制GCN中有用的相邻扩散量是必不可少的。
1 介绍
用户地理定位是识别用户“家”位置的任务,是公共卫生监测的许多应用的不可或缺的组成部分(Paul和Dredze,2011; Chon等,2015; Yepes等,2015)情感的区域研究,实时应急意识系统(De Longueville et al。,2009; Sakaki et al。,2010),它使用社交媒体作为关于人的隐含信息资源。
诸如Twitter之类的社交媒体服务依赖于IP地址,WiFi足迹和GPS数据来对用户进行地理定位。第三方服务提供商无法轻松访问此类信息,并且仅仅依靠地理定位信息的公共来源,例如嘈杂的地理位置,嘈杂且难以映射到某个位置(Hecht等,2011),或地理标记的推文只有1%的推文公开提供(Cheng et al。,2010; Morstat-ter et al。,2013)。公开可用的位置信息的稀缺性促使预测用户从诸如推文文本和社交交互数据之类的信息中获得信息。
以前关于用户地理定位的大多数工作都是基于文本的监督方法(Wing andBaldridge,2011; Han et al。,2012),依赖于语言使用的地理变异,或基于图形的半监督标签传播依赖于用户的同位置- 用户交互(Davis Jr等,2011; Jurgens,2013)。
需要文本和网络视图才能获得用户地理定位的完整信号。一些用户发布了很多本地内容,但他们的社交网络缺失或者不代表他们的位置;对于他们来说,文本是地理位置的主要观点。另一组用户有许多本地社交互动,并且大多使用社交媒体来阅读其他人的评论,以及与朋友互动。如果右视图不存在,单视图学习将无法准确地对这些用户进行地理定位。已经有一些使用文本和网络视图的工作,但是迭代完全忽略未标记的数据(Li等,2012a; Miura等,2017),或者只是在网络视图中使用未标记的数据(Rahimi等,2015b); Do et al。,2017)。鉴于1%的地理标记的推文通常用于监督,因此地理定位模型能够利用未经预测的数据,并在最低监督情景下表现良好至关重要。
在本文中,我们提出了GCN,一种基于图形转换网络(Kipf和Welling,2017)的端到端用户地理定位模型,它可以从文本和网络信息中共同学习,将用户时间线分类到一个位置。我们的贡献是:(1)我们评估我们的模型欠极小监督情景,它接近于现实世界的应用,并表明GCN 性能优于两个强大的基线;(2)给定足够的监督,我们表明GCN具有竞争性,尽管更简单的MLP-TXT + NEToutper形成了最先进的模型;(3)我们证明了highway gates在控制GCN中有用的邻域平滑量方面起着重要作用。
2 Model
我们使用图形卷积网络(GCN)(Kipf和Welling,2017)提出了转导多视图地理定位模GCN。我们还引入了两个多视图基线:MLP-TXT + NET基于文本和网络的连接,以及基于深度典型相关分析的DCA(Andrew等,2013)。
2.1 多元地理位置
设 X ∈ R ∣ U ∣ × ∣ V ∣ X∈R^{| U |×| V |} X∈R∣U∣×∣V∣是文本视图,由使用词汇表V的U中每个用户的单词包组成,并且 A ∈ l ∣ U ∣ × ∣ U ∣ A∈l^{| U |×| U |} A∈l∣U∣×∣U∣是network视图,编码用户 - 用户交互。我们将 U = U S ∪ U H U =U_S∪U_H U=US∪UH分别划分为受监督和保持(未标记)的集合, U S U_S US和 U H U_H UH,并且在给定标记样本 Y S Y_S YS的位置的情况下,推断未标记样本 Y U Y_U YU的位置,其中每个位置被编码作为one-hot的分类标签, y i ∈ l c y_i∈l^c yi∈lc, c c c是目标区域的数量。
2.2 GCN
GCN定义了每层的神经网络模型
f
(
X
,
A
)
f(X,A)
f(X,A):
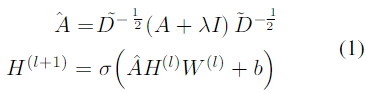
超参数
λ
λ
λ控制节点对邻域的权重,在原始模型中设置为1.
换句话说,对于用户
u
i
u_i
ui,
h
i
l
+
1
h_i^{l + 1}
hil+1,
l
l
l层的输出由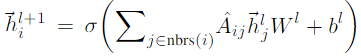 计算.
计算.
GCN中的每个额外层都扩展了邻居,使样本平滑。例如,具有3层的GCN平滑每个样品,其邻近距离可达3个跳跃,这是有益的,如果同位置延伸到这个大小的邻域。
2.2.1 Highway GCN
通过添加多个GCN层来扩展标签传播的邻域可以通过访问来自多跳的朋友的信息来改善地理定位,但是它也可能导致来自指数增加的扩展邻居成员的嘈杂信息传播给用户。为了控制应该将多少邻域信息传递给节点的所需平衡,我们使用类似于高速公路网络的分层门。在高速公路网络中(Srivastava等,2015),层的输出与其输入相加,门控权重为
T
(
h
l
)
T(h^l)
T(hl):
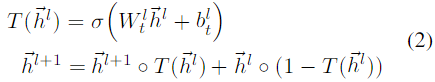
◦
◦
◦是元素乘法,
σ
σ
σ是Sigmoid函数
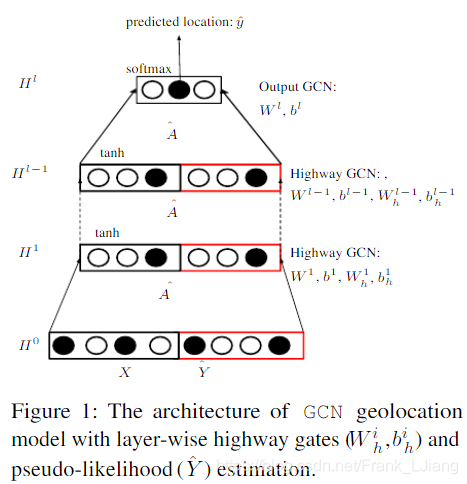
图1:具有分层highway gates(
W
i
h
{W_i^h}
Wih,
b
i
h
{b_i^h}
bih)和伪似然(
Y
Y
Y)估计的GCN地理定位模型的架构
2.2.2 伪似然风格估计(Pseudo-likelihood Style Estimation)
GCN假设节点的标签与节点的特征相关,并且当使用
l
l
l层时,它的邻居的特征也最多可达
l
l
l跳。我们使用一种伪似然估计的形式,通过将节点的标签调整为其邻居的预测标签,
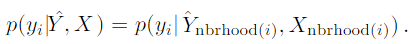
因为在培训时可能不知道邻居的标签,我们采用课程学习(Elman,1993)来首先仅使用来自节点的邻居的文本信息来学习合理的模型,然后使用邻居的预测标签作为输入。我们在模型基于特征已经达到了合理的性能(例如,训练数据的准确度为20%)之后提供邻居的预测标签,然后将节点邻居的预测与文本特征连接起来并将它们馈送到GCN网络中。在测试时,给定节点,其扩展邻域的标签(标记样本的基础事实或未标记样本的预测)与节点的文本特征连接,并馈送到GCN网络以进行最终预测。
这种技术实际上是邻域平均的一种手段,它已经是GCN公式的一部分。我们的方法不仅仅是加倍GCN的深度,因为我们不对这个“输入”执行梯度反向传播。根据经验,效果仅与直接从单个GCN学习分类器略有不同,没有伪似然样式输入馈送,因此我们仅呈现伪似然类型方法的结果。
2.3 DCCA
给定数据样本的两个视图
X
X
X和
A
A
A(等式1),CCA(Hotelling,1936)及其深度版本(DCCA)(Andrew等人,2013)学习函数
f
1
(
X
)
f_1(X)
f1(X)和
f
2
(
A
)
f_2(A)
f2(A),使得两个函数的输出之间的相关性最大化:
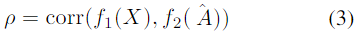
得到的
f
1
(
X
)
f_1(X)
f1(X)和
f
2
(
A
)
f_2(A)
f2(A)的表示是两个视图的压缩表示,其中它们之间的不相关噪声减小。新表示理想地表示网络视图的用户社区,以及用于文本视图的该社区的语言模型,并且它们的串联是数据的多视图表示,其可以用作其他任务的输入。
在DCCA中,对于每个视图(方程式3的
f
1
f_1
f1和
f
2
f_2
f2函数),使用单独的多层感知器将两个视图首先投影到较低维度,其输出用于估计CCA成本:
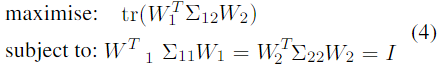
其中
Σ
11
Σ_{11}
Σ11和
Σ
22
Σ_{22}
Σ22是两个输出的协方差,
Σ
12
Σ_{12}
Σ12是交叉协方差。权重
W
1
W_1
W1和
W
2
W_2
W2是MLP输出的线性投影,用于估计CCA成本。通过SVD求解优化问题,并且反向传播误差以训练两个MLP的参数和最终的线性投影。训练之后,这两个网络用于预测看不见的数据的新预测。然后将看不见的数据的两个预测(两个网络的输出)连接起来形成多视图样本表示,如图2所示。
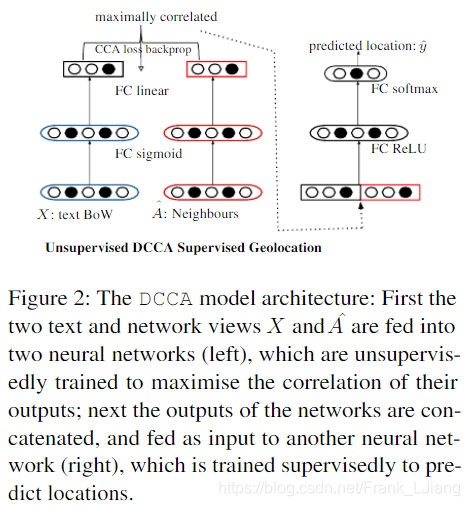
图2:DCCA模型架构:首先,两个文本和网络视图X和A被馈送到两个神经网络(左),这些神经网络经过无人监督训练,以最大化其输出的相关性;接下来,网络的输出被连接,并作为输入馈送到另一个神经网络(右),该神经网络被监督地训练以预先指示位置。
3 实验
3.1 数据
我们使用三个现有的Twitter用户地理定位数据集:(1)GEOTEX T(Eisenstein等,2010),(2)TWITTER-US(Roller等,2012),以及(3)TWITTER-WOR LD(Han等人。,2012)。这些数据集已广泛用于地理定位模型的训练和评估。它们都预先分配到训练,开发和测试集中。每个用户都用他们推文的串联来表示,并且在GEOTEXT和TWITTER-US的情况下用第一个收集的地理标记推文的纬度/经度标记,在TWITTER-WORLD的情况下标记为最近城市的中心。GEOTEXT和TWITTER-US覆盖美国大陆,TWITTER-WORLD覆盖全球,分别拥有9k,449k和130万用户。标签是使用Roller等人的k-d树的训练点的离散地理坐标。(2012),GEOTEXT,TWITTER-US和TWITTER-WORLD的标签数量分别为129,256和930。
3.2 构建视图
我们使用用户之间折叠的@ -mention图构建等式1中的矩阵A,其中两个用户连接( A i j = 1 A_{ij} = 1 Aij=1),如果有人提到另一个用户,或者他们共同提及另一个用户。文本视图是用户内容的BoW模型,具有二进制项频率,逆文档频率和样本的 l 2 l_2 l2归一化。
3.3 模型选择
对于GCN,我们使用公路层来控制传递给节点的邻域信息量。我们在GCN中使用3层,尺寸分别为300,600,900,分别用于GEOTEXT,TWITTER-US和TWITTERWORLD。注意,最终的softmax层也是图形卷积,它将平均邻域的半径设置为4。基于对验证集的调整,对于各个数据集,控制每个簇中的最大用户数的k-d树桶大小超参数被设置为50,2400和2400。GCN-LP的体系结构类似,区别在于文本视图设置为零。在DCCA中,对于无监督网络,我们使用大小为1000的单个S形隐藏层和三个数据集的大小为500的线性输出层。损失函数是CCA损失,它使输出相关性最大化。受监督的多层感知器有一个隐藏层,大小分别为300,600,1000,分别用于GEOTEXT,TWITTER-US和TWITTER-WORLD,我们通过调整开发集来设置。我们使用中位数误差,平均误差和Acc @ 161来评估模型,这是在距离已知位置161公里或100英里内预测用户的准确性。
3.4 基线
我们还将DCCA和GCN与两个基线进行比较:
GCN-LP基于GCN,但是对于输入而不是基于文本的功能,我们使用用户邻居的one-hot编码,然后与他们的k-hop邻居进行卷积。使用GCN。这种方法类似于平滑用户的标签分布与其邻居的标签传播,但使用具有额外层参数的图卷积网络,以及控制平滑邻域半径的门控机制。请注意,对于未标记的样本,在训练精度达到0.2后,预测标签用于输入。
MLP-TXT + NET是一个基于单层多层感知器的简单转换监督模型,其中网络的输入是文本视图X,用户内容的词袋和A(等式1)的串联,它代表 网络视图作为矢量输入。对于隐藏层,我们使用ReLU非线性,尺寸分别为300,600和600,分别用于GEOTEXT,TWITTER-US和TWITTER-WORLD。
4 结果与分析
4.1 Representation
Deep CCA和GCN能够以不同方式提供无监督的数据表示。Deep CCA采用两种基于文本和基于网络的视图,并发现深度非线性变换,从而在两个视图之间产生最大的相关性(Andrew et al。,2013)。表示可以使用t-SNE可视化,我们希望具有相同标签的样本聚集在一起。另一方面,GCN使用图形卷积。来自4个随机选择的GEOTEXT标签中的每一个的50个样本的表示如图3所示。如图所示,Deep CCA似乎略微改善了两个视图的纯级联的表示。另一方面,GCN大大改善了表示形式。GCN的进一步应用导致更多样品聚集在一起,这在具有强同源性时可能是期望的。
4.2 标记数据大小
为了在监督任务中获得良好的性能,通常需要大量标记数据,这对于Twitter地理定位来说是一个巨大的挑战,其中只有一小部分数据被地理标记(约1%)。缺乏监督表明半监督学习的重要性,其中未标记(例如,非地理标记)的推文用于训练。我们提出的三个模型(MLP-TXT + NET,DCCA和GCN)都是使用未标记数据的转换半监督模型,但是,它们在获得可接受性能所需的标记数据量方面是不同的。鉴于在现实世界的场景中,只有一小部分数据是地理标记的,我们进行了一项实验来分析标记样本对三种地理定位模型性能的影响。我们为三个模型提供了标记的不同部分样本(以数据集样本的百分比表示),同时使用余数作为未标记数据,并分析了它们在GEOTEXT,TWITTER-US和TWITTER-的开发集上的中位数误差性能。世界。请注意,文本和网络视图以及开发集对所有实验都保持固定。如图4所示,当标记样本的比例小于所有样本的10%时,由于参数较少,GCN和DCCA优于MLP-TXT + NET,因此,优化它们的监督要求较低。当有足够的训练数据时(例如,超过所有样本的20%),GCN和MLP-TXT + NET明显优于DCCA,可能是直接建模网络和文本视图之间的交互的结果。当两个较大数据集的所有训练样本(分别为TWITTER-US和TWITTERWORLD分别为95%和98%)可用于模型时,MLP-TXT + NET优于GCN。请注意,参数数量从DCCA增加到GCN和MLP-TXT + NET。对于GEOTEXT,1%的DCCA优于GCN,因为它具有较少的参数和少量标记样品,不足以训练GCN的参数。
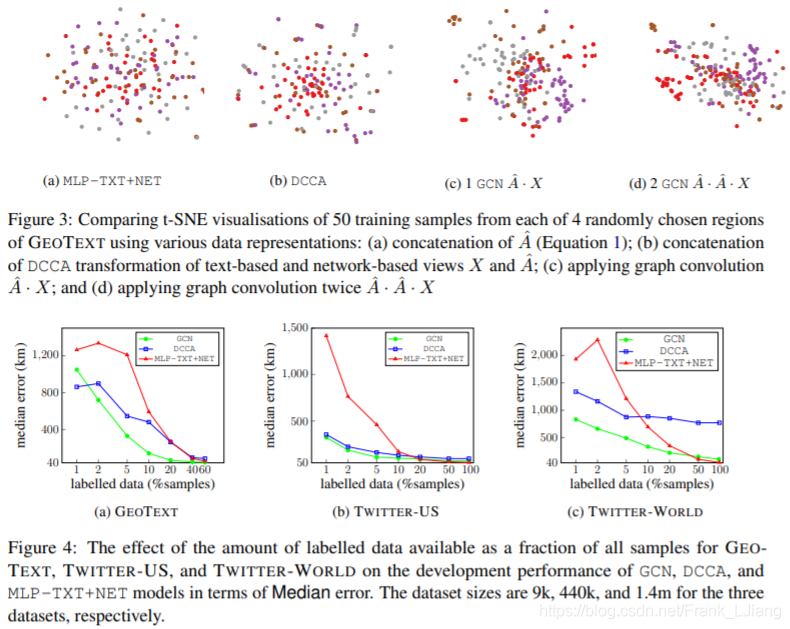
4.3 Highway Gates
向GCN添加更多层会扩展用户特征平均的图形邻域,因此可能会引入噪声,从而降低精度,如图5所示,当没有使用门时。我们看到,通过添加高速公路网络门,GCN的性能略有提高,直到添加了三层,但随后通过添加更多层,性能不会发生太大变化,因为门允许层输入通过网络而没有太大变化。性能在4层达到峰值,这与图6中所示的最短路径长度分布兼容。
4.4 Performance
所提出的三种模型(MLP-TXT + NET,DCCA和GCN)的性能如表1所示。这些模型也与有监督的基于文本的方法进行了比较(Wing和Baldridge,2014; Cha等,2015; Rahimi)等,2017b),基于网络的方法(Rahimi等,2015a)和GCN-LP,以及联合文本和网络模型(Rahimi等,2017b; Do等,2017; Miura等。,2017)。MLP-TXT + NET和GCN优于所有仅文本或网络模型,以及Rahimi等人的混合模型。(2017b),表明文本和网络特征的联合建模很重要。MLP-TXT + NET与Do等人竞争。(2017),在较大的数据集上表现优异,在GEO-TEXT上表现不佳。然而,由于他们在其功能集中使用时区数据,因此很难进行公平的比较.MLP-TXT + NET在TWITTERUS和TWITTER-WORLD上优于GCN,这非常大,并且具有大量标记数据。在几乎没有监督的情况下(标记总样本的1%),DCCA和GCN明显优于MLP-TXT + NET,因为它们具有较少的参数。除了GEOTEXT上的Acc @ 161,其中最小监管情景中标记样本的数量非常低,GCN的表现优于DCCA,表明对于只有1%样本被标记的中等数据集(如随机样本中所发生的那样)推特)GCN优于MLP-TXT + NET和DCCA,与4.2节一致。与仅网络,纯文本和混合模型相比,MLP-TXT + NET和GCN都实现了最先进的结果。使用图形卷积网络进行标签传播的基于网络的GCN-LP模型优于Rahimi等人。(2015a),它基于使用改良吸附的位置传播(Talukdar和Crammer,2009),可能是因为GCN中的标记传播是参数化的。
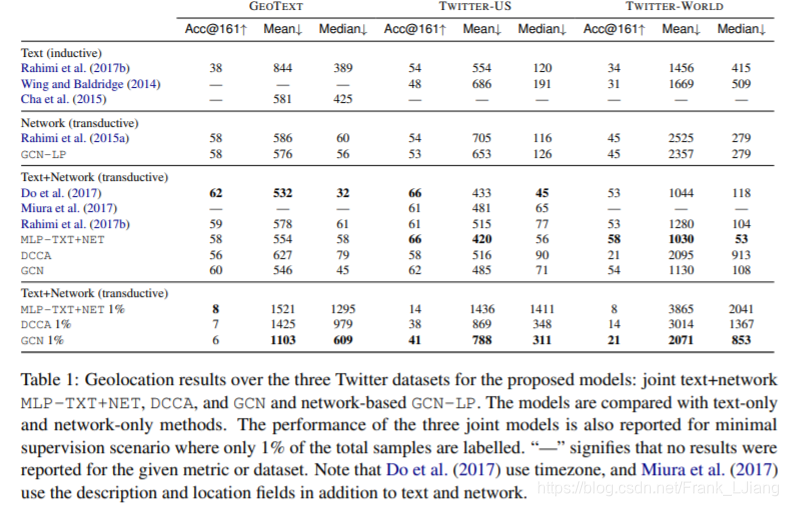
表1:所提出模型的三个Twitter数据集的地理定位结果:联合文本+网络MLP-TXT + NET,DCCA和GCN以及基于网络的GCN-LP。将模型与纯文本和仅网络方法进行比较。还报告了三种关节模型的性能,用于最小监督方案,其中仅标记了总样本的1%。“ - ”表示没有报告给定指标或数据集的结果。注意Do等人。(2017)使用时区,Miura等。(2017)除了文本和网络之外,还使用描述和位置字段。
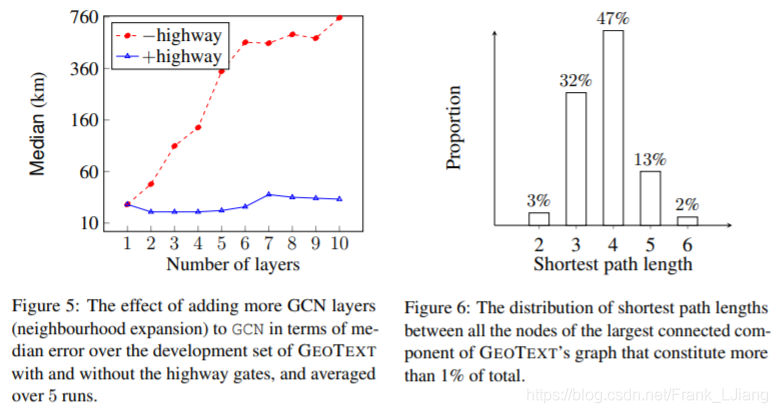
图5:在有和没有高速公路大门的GEOTEXT开发集中,在GCN上添加更多GCN层(邻域扩展)的影响,平均超过5次运行。
图6:GEOTEXT图表中最大连通分量的所有节点之间的最短路径长度分布,占总数的1%以上。
4.5 Error Analysis
虽然当大量标记数据可用时,MLP-TXT + NET的性能优于GCN和DCCA(表1),但在没有标记数据的情况下(1%的数据),DCCA和GCN优于MLP -TXT + NET,主要是因为MLP-TXT + NET中的参数数量随样本数量的增加而增加,并且比GCN和DCCA大得多。GCN使用1%的数据优于DCCA和MLP-TXT + NET,但是,TWITTER-US开发集中的错误分布表明较小的状态(如罗德岛(RI),爱荷华州(IA),北达科他州的误差较高 (ND)和Idaho(ID),这仅仅是因为这些状态中标记样本的数量不足。
虽然我们使用Median,Mean和Acc @ 161来评估地理定位模型,但这并不意味着错误的分布在所有位置都是一致的。大城市经常吸引更多的本地在线讨论,使这些领域的用户地理位置更加简单。例如,洛杉矶的用户更倾向于谈论与洛杉矶相关的问题,例如他们的运动队,好莱坞或当地赛事,而不是罗德岛州(RI)的用户,这些用户缺乏大型运动队或重大赛事。
人口密度较低的地区的人们也可能彼此进一步分开,因此,由于离散化的结果在不同的群集中。局部讨论的不均匀性导致美国中西部人口密度较低的地区的地理定位性能较低,而纽约市和洛杉矶等人口密集地区的地理定位性能较高,如图7所示.GCN,DCCA和MLP的误差地理分布 最小监督情景下的-TXT + NET显示在补充材料中。
为了更好地了解状态之间的错误分类,我们使用仅使用1%标记数据的GCN,为TWITTER-US的开发用户构建了基于已知状态和预测状态的混淆矩阵。用户被错误地预测在CA,NY,TX以及令人惊讶的OH。特别是位于靠近CA的TX,AZ,CO和NV等州的用户被错误地预测在CA中,并且来自NJ,PA和MA的用户被错误地分类为在纽约。对于OH和TX来说也是如此,其中来自相邻较小州的用户被错误分类到那里。来自CA和NY的用户也在两个州之间被错误分类,这可能是纽约市和LA / SF之间存在的商业和娱乐连接的结果。有趣的是,对于来自CA,NY和TX的用户,FL存在许多错误分类,这可能是用户度假或退休到FL的影响。美国各州之间的完全混淆矩阵在补充材料中提供。
4.6 本地术语
在表2中,显示了GCN在最小监督下检测到的少数区域的本地术语。排除标记数据中存在的术语,以显示社交图上的图形卷积如何扩展词汇表。例如,在西雅图的情况下,#goseahawks是1%标记数据中不存在的重要术语,但存在于未标记数据中。社交图上的卷积能够利用标记数据中不存在的这些术语。
5 相关工作
以前关于用户地理定位的工作大致可分为基于文本,基于网络和多视图的方法。基于文本的地理定位使用语言使用中的地理偏差来推断用户的位置。
地理定位有三种主要的基于文本的方法:(1)基于地名词典的模型,它将文本中的地理参考映射到位置,但忽略非地理参考和语言的本地使用(Rauch等,2003; Amitay等。,2004; Lieberman等,2010); (2)学习区域特定主题但不扩展到社交媒体规模的地理主题模型(Eisenstein等,2010; Hong等,2012; Ahmed等,2013); (3)监督模型,通常被定义为文本分类(Serdyukov等,2009; Wing和Baldridge,2011; Roller等,2012; Han等,2014)或文本回归(Iso等, 2017; Rahimi等,2017a)。监督模型可以很好地扩展,并且可以通过充分的监督来实现良好的性能,这在现实世界的场景中不可用。
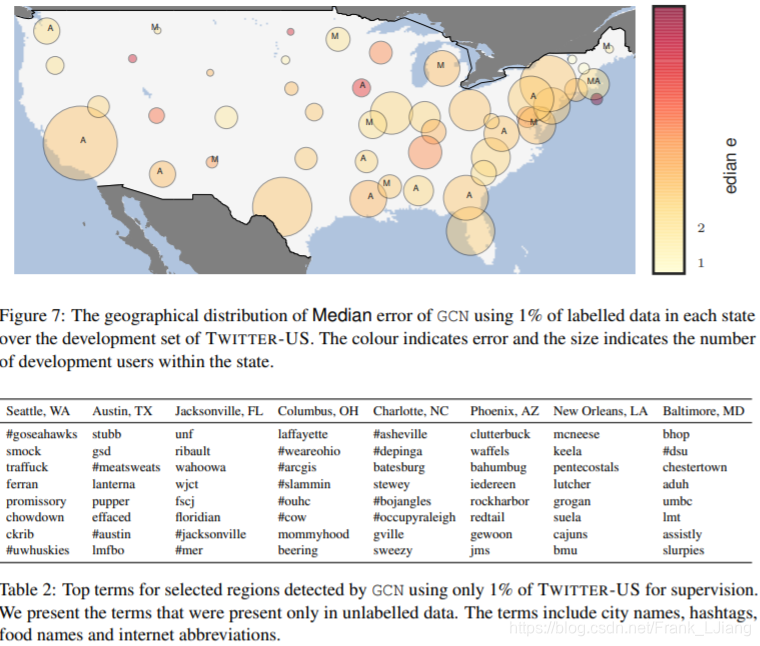
图7:在TWITTER-US开发集中,每个州使用1%标记数据的GCN中位数误差的地理分布。颜色表示错误,大小表示该州内的开发用户数。
表2:GCN检测到的选定区域的主要术语仅使用TWITTER-US的1%进行监督。
我们提供仅在未标记数据中出现的术语。这些术语包括城市名称,主题标签,食品名称和互联网缩写。基于网络的方法利用位置同音假设:附近的用户更可能彼此交朋友并互动。
有四种主要的基于网络的地理定位方法:基于距离的监督分类,基于图形的标签传播和节点嵌入方法。基于距离的方法模拟了给定距离的友谊概率(Backstrom等,2010; McGee等,2013; Gu等,2012; Kong等,2014),监督模型使用邻域特征来分类 用户进入某个位置(Rout et al。,2013; Malmi et al。,2015),基于图形的标签传播模型通过用户 - 用户图传播位置信息以估计未知标签(Davis Jr et al。,2011) ; Jurgens,2013; Compton等,2014)。节点嵌入方法在用户 - 用户,用户位置和位置 - 位置之间构建异构图,并学习嵌入空间以最小化连接节点的距离,并最大化断开节点的距离。然后将嵌入用于监督模型中进行地理定位(Wang et al。,2017)。基于网络的模型无法对断开连接的用户进行地理定位:Jurgens等。(2015)由于断线而无法将37%的用户进行地理定位。
以前关于混合文本和网络方法的工作可以大致分为三种主要方法:(1)将基于文本的信息(例如地名或从基于文本的模型预测的位置作为辅助节点)合并到用户 - 用户图中,然后将其用于基于网络的模型(Li et al。,2012a,b; Rahimi et al。,2015b,a);(2)对分别训练的基于文本和网络的模型进行集合(Gu et al。,2012; Ren et al。,2012; Jayasinghe et al。,2016; Ribeiro and Pappa,2017);(3)从文本和网络信息等几个信息来源共同学习地理定位(Miura等,2017; Do等,2017),可以捕获文本和网络视图中的补充信息,并模拟交互两者之间。以前的多视图方法都没有 - 除了李等人。(2012a)和李等人。(2012b)仅使用地名 - 在文本视图中有效地使用未标记的数据,并且仅通过用户 - 用户图使用网络视图的未标记信息。
我们在本文中讨论的用户地理定位的前期工作存在三个主要缺点:(1)除了最近的一些工作(Miura等,2017; Do等,2017),之前的模型没有共同利用文本和网络信息,因此文本和网络视图之间的交互没有建模;(2)文本和网络视图中未标记的数据未得到有效利用,这在少量可用监督的情况下至关重要;(3)以前的模型很少在最小监督情景下进行评估,这种情景反映了现实世界的情况。
6 结论
我们提出了GCN,DCCA和MLP-TXT + NET,三种多视图,转换,半监督地理定位模型,它们使用文本和网络信息在联合设置中推断用户位置。我们发现,文本和网络信息的联合建模优于仅网络,纯文本和混合地理定位模型,这是对文本和网络信息之间的交互进行建模的结果。我们还表明,通过有效地使用未标记数据,GCN和DCCA能够在类似于现实世界应用的最小监督场景下表现良好。我们忽略了用户互相交互的上下文,并假设所有连接都保持位置同音。在未来的工作中,我们感兴趣的是模拟社交互动由地理接近度引起的程度(例如,使用用户 - 用户门)。

















 5759
5759

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









