







 本文介绍了如何使用Python3爬取Max+新闻数据并存储到MySQL数据库中。通过分析新闻列表URL的JSON信息,提取了content_type、date、click、newsurl、newsid、title和source等字段。对于HTML结构差异导致的作者信息提取问题,采取了处理多余信息的方法。最后,创建了数据库表并成功存储了9551条新闻数据。反思中提到程序简单,未进行性能优化,如使用BeautifulSoup解析速度较慢,未来计划进行数据分析和可视化。
本文介绍了如何使用Python3爬取Max+新闻数据并存储到MySQL数据库中。通过分析新闻列表URL的JSON信息,提取了content_type、date、click、newsurl、newsid、title和source等字段。对于HTML结构差异导致的作者信息提取问题,采取了处理多余信息的方法。最后,创建了数据库表并成功存储了9551条新闻数据。反思中提到程序简单,未进行性能优化,如使用BeautifulSoup解析速度较慢,未来计划进行数据分析和可视化。
正文
上一篇文章我们已经分析了如何获取新闻的url页面,以及url页面的参数设置。现在就来具体编写代码实现爬取数据存入数据库。
首先看看我们想要的,用Chrome打开新闻list的url,F12进入开发者模式,在network中的preview可以查看json信息。
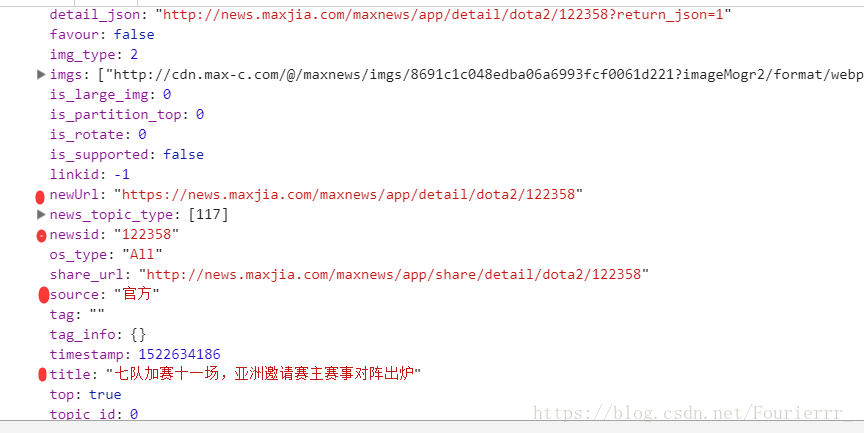
我们可以获取,类型content_type,时间date,点击click,文章链接newsurl,文章编号newsid,标题title,来源source。
但是实际上没有具体的作者信息,我们可以从newsurl点进去具体再分析,
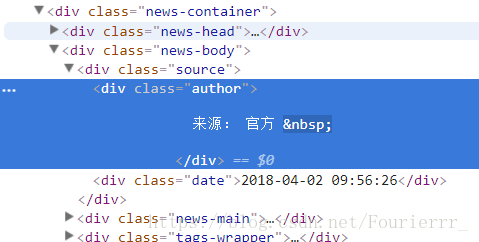
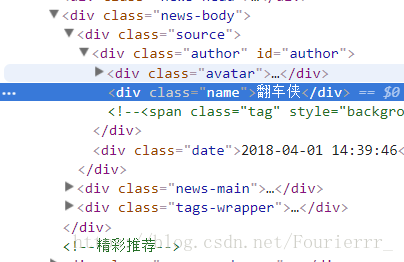
发现作者有两种形式,一种是没有具体作者的,直接写官方或者Max+的,还有一种是有具体作者的。html代码略有不同,不过都比较好提取。”author”提取出来可能会有一些多余信息,用replace方法或者re.sub()方法就能轻易解决。
同时兼顾到了max新闻早期的版本,15年的新闻html代码也略有不同,比如author前后有很多‘\t’占位符,不仔细还真不好去掉。
爬取的信息储存在mysql中,连接maxplus数据库,建立名为news的表:
conn=mysql.connector.connect(user='root',password='xxxxxx',database='maxplus')create table news
(id integer primary key auto_increment not null,
date text not null,
time text not null,
click text not null,
newsid text not null,
linkid text not null,
author text not null,
title text not null,
newsurl text not null,
content_type text not null) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









