







 本文介绍了蒙特卡洛方法(MC),它由冯 - 诺伊曼等人提出,是对一类随机算法特性的概括。对比了MC与Las Vegas算法,还给出求解圆周率和积分的例子。阐述了重要性采样,当难以找到合适分布时可采用马尔可夫链蒙特卡罗方法(MCMC),同时指出MCMC存在的缺点。
本文介绍了蒙特卡洛方法(MC),它由冯 - 诺伊曼等人提出,是对一类随机算法特性的概括。对比了MC与Las Vegas算法,还给出求解圆周率和积分的例子。阐述了重要性采样,当难以找到合适分布时可采用马尔可夫链蒙特卡罗方法(MCMC),同时指出MCMC存在的缺点。
蒙特卡洛方法(Monte Carlo method,MC)在二十世纪四十年代由冯-诺伊曼、乌拉姆和尼古拉斯率先提出,名字来源于摩纳哥著名的赌城-蒙特卡洛。MC是一种通过生成合适的随机数和观察部分服从一些特定性质或属性的数据来解决问题的方法,通过统计抽样实验给各种各样的数学问题提供了近似解,这种方法对于一些太复杂以至很难分析求解的问题得到数字解法是非常有效的,而且同时适应于毫无概率性的问题 和 内在固有概率结构的问题。
但MC并不是某一种具体算法的名称,它是对一类随机算法的特性的概括。通常可以将随机算法分为两类:
- Las Vegas算法:精确的返回一个正确答案或是返回算法失败,采样次数越多,越有机会找到最优解
- MC:返回具有随机大小错误的答案,它是一个近似解,采样次数越多,越近似最优解
如何理解两种方法的差异呢?在蒙特卡罗算法是什么?中有一个很通俗易懂的例子。
- 假设现在有100个苹果,人只能蒙眼每次拿一个,挑出最大的。再随机拿1个跟它比,留下大的,再随机拿1个……每拿一次,留下的苹果都至少不比上次的小。拿的次数越多,挑出的苹果就越大,但除非拿100次,否则无法肯定挑出了最大的。这个挑苹果的算法,就属于蒙特卡罗算法——尽量找好的,但不保证是最好的
- 假如有一把锁,给100把钥匙,只有1把是对的。于是每次随机拿1把钥匙去试,打不开就再换1把。试的次数越多,打开(最优解)的机会就越大,但在打开之前,那些错的钥匙都是没有用的。这个试钥匙的算法,就是拉斯维加斯算法——尽量找最好的,但不保证能找到
蒙特卡洛方法最简单的一个例子就是求解圆周率 π \pi π,假设在正方形内嵌一个半径为 r r r的圆如下所示:
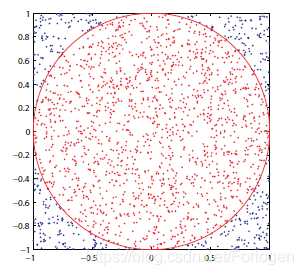
从公式推导上有 A circle A square = π r 2 4 r 2 = π 4 \frac{A_{\text { circle }}}{A_{\text { square }}}=\frac{\pi r^{2}}{4 r^{2}}=\frac{\pi}{4} A square A circle =4r2πr2=4π,为了求解 π \pi π可以随机的在正方形内选择 n n n个点,那么落在圆内的点可能有 m m m个,根据比例有 A circle A square = m n \frac{A_{\text { circle }}}{A_{\text { square }}}=\frac{m}{n} A square A circle =nm,那么如果采样点的数目足够多时, m n \frac{m}{n} nm的值就会等于 π 4 \frac{\pi}{4} 4π,因此有 π = 4 × m n \pi=4 \times \frac{m}{n} π=4×nm。
另一个例子便是求积分,这里不再赘述,有兴趣的可看一下蒙特卡洛求定积分。
在现实的很多问题中我们往往无法得到一个精确解,那么常用的一种方法便是进行采样计算逼近于精确解的近似解。例如当无法精确的计算积分时,就把它看做是某分布下的期望,然后通过估计对应的平均值来近似期望。假设所需求解的期望为 s = ∑ x p ( x ) f ( x ) = E p [ f ( x ) ] s=\sum_{\boldsymbol{x}} p(\boldsymbol{x}) f(\boldsymbol{x})=E_{p}[f(\mathbf{x})] s=∑xp(x)f(x)=Ep[f(x)],我们就可以从 p p p在随机的抽取 n n n个点,通过计算一个经验平均值来近似 s s s. s ^ n = 1 n ∑ i = 1 n f ( x ( i ) ) \hat{s}_{n}=\frac{1}{n} \sum_{i=1}^{n} f\left(\boldsymbol{x}^{(i)}\right) s^n=n1i=1∑nf(x(i))其中 p p p是关于 x x x的概率分布。而且得到的 s ^ \hat{s} s^具有如下的性质:
- s ^ \hat{s} s^的估计是无偏的: E [ s ^ n ] = 1 n ∑ i = 1 n E [ f ( x ( i ) ) ] = 1 n ∑ i = 1 n s = s \mathbb{E}\left[\hat{s}_{n}\right]=\frac{1}{n} \sum_{i=1}^{n} \mathbb{E}\left[f\left(\boldsymbol{x}^{(i)}\right)\right]=\frac{1}{n} \sum_{i=1}^{n} s=s E[s^n]=n1∑i=1nE[f(x(i))]=n1∑i=1ns=s
- 由大数定理可知,如果 x ( i ) x^{(i)} x(i)满足独立同分布,那么其平均值必然收敛到期望值: lim n → ∞ s ^ n = s \lim _{n \rightarrow \infty} \hat{s}_{n}=s limn→∞s^n=s
- 只要 V a r [ f ( x ( i ) ) ] Var[f(x^{(i)})] Var[f(x(i))]有界,当 n n n增大时, V a r [ s n ^ ] Var[\hat{s_{n}}] Var[sn^]就会减小并收敛至0: Var [ s ^ n ] = 1 n 2 ∑ i = 1 n Var [ f ( x ) ] = Var [ f ( x ) ] n \begin{aligned} \operatorname{Var}\left[\hat{s}_{n}\right] &=\frac{1}{n^{2}} \sum_{i=1}^{n} \operatorname{Var}[f(\mathbf{x})] \\ &=\frac{\operatorname{Var}[f(\mathbf{x})]}{n} \end{aligned} Var[s^n]=n21i=1∑nVar[f(x)]=nVar[f(x)]
- 根据中心极限定理可知, s n ^ \hat{s_{n}} sn^的分布将收敛到以 s s s为均值、 V a r [ f ( x ) ] n \frac{Var[f(x)]}{n} nVar[f(x)]为方差的正态分布
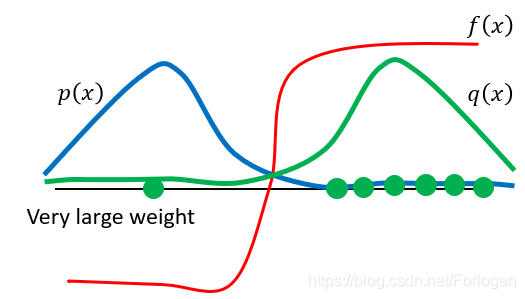
在蒙特卡洛方法中一个很重要的东西就是重要性采样(Importance Sampling)。它是使用一种分布来逼近所求分布的一种方法。假设我们想要求取目标分布 p p p下的函数 f ( x ) f(x) f(x)所满足的分布,如果 p p p可以直接采样,那么使用蒙特卡洛方法有如下的计算 E x ∼ p [ f ( x ) ] = ∫ x p ( x ) f ( x ) d x ≈ 1 N ∑ x i ∼ p , i = 1 N f ( x i ) E_{x \sim p}[f(x)]=\int_{x} p(x) f(x) d_{x} \approx \frac{1}{N} \sum_{x_{i} \sim p, i=1}^{N} f\left(x_{i}\right) Ex∼p[f(x)]=∫xp(x)f(x)dx≈N1xi∼p,i=1∑Nf(xi) 但是如果无法直接对 p p p进行采样,那么上面的方法就不能使用了,这时就可以使用可以进行采样的分布 q q q来近似 p p p,计算公式为 E x ∼ p [ f ( x ) ] = ∫ x p ( x ) f ( x ) d x = E x ∼ p ′ [ p p ′ f ( x ) ] ≈ 1 N ∑ x i ∼ p ′ , i = 1 N p ( x ) p ( x ) ′ f ( x ) E_{x \sim p}[f(x)]=\int_{x} p(x) f(x) d_{x}=E_{x \sim p^{\prime}}\left[\frac{p}{p^{\prime}} f(x)\right] \approx \frac{1}{N} \sum_{x_{i} \sim p^{\prime}, i=1}^{N} \frac{p(x)}{p(x)^{\prime}} f(x) Ex∼p[f(x)]=∫xp(x)f(x)dx=Ex∼p′[p′pf(x)]≈N1xi∼p′,i=1∑Np(x)′p(x)f(x)而且这里使用的分布 q q q不应该和 p p p相差太大,直观上我们可以理解所用分布自然不能和所要逼近的分布有太大的差距,否则就无法说的通了。下面从均值和方差的角度来看一下为什么要这样,从上面的式子中可以看出 E x ∼ p [ f ( x ) ] = E x ∼ q [ f ( x ) p ( x ) q ( x ) ] E_{x \sim p}[f(x)]=E_{x \sim q}\left[f(x) \frac{p(x)}{q(x)}\right] Ex∼p[f(x)]=Ex∼q[f(x)q(x)p(x)],它们的均值不会有太大差别。将两者的方差写为 Var x ∼ p [ f ( x ) ] \operatorname{Var}_{x \sim p}[f(x)] Varx∼p[f(x)]和 Var x ∼ q [ f ( x ) p ( x ) q ( x ) ] \operatorname{Var}_{x \sim q}\left[f(x) \frac{p(x)}{q(x)}\right] Varx∼q[f(x)q(x)p(x)],根据概率论中方差和均值的转换公式有 Var x ∼ p [ f ( x ) ] = E x ∼ p [ f ( x ) 2 ] − ( E x ∼ p [ f ( x ) ] ) 2 Var x ∼ q [ f ( x ) p ( x ) q ( x ) ] = E x ∼ q [ ( f ( x ) p ( x ) q ( x ) ) 2 ] − ( E x ∼ q [ f ( x ) p ( x ) q ( x ) ] ) 2 = E x ∼ p [ f ( x ) 2 p ( x ) q ( x ) ] − ( E x ∼ p [ f ( x ) ] ) 2 \begin{array}{l}{\operatorname{Var}_{x \sim p}[f(x)]=E_{x \sim p}\left[f(x)^{2}\right]-\left(E_{x \sim p}[f(x)]\right)^{2}} \\ {\operatorname{Var}_{x \sim q}\left[f(x) \frac{p(x)}{q(x)}\right]=E_{x \sim q}\left[\left(f(x) \frac{p(x)}{q(x)}\right)^{2}\right]-\left(E_{x \sim q}\left[f(x) \frac{p(x)}{q(x)}\right]\right)^{2}} \\ {=E_{x \sim p}\left[f(x)^{2} \frac{p(x)}{q(x)}\right]-\left(E_{x \sim p}[f(x)]\right)^{2}}\end{array} Varx∼p[f(x)]=Ex∼p[f(x)2]−(Ex∼p[f(x)])2Varx∼q[f(x)q(x)p(x)]=Ex∼q[(f(x)q(x)p(x))2]−(Ex∼q[f(x)q(x)p(x)])2=Ex∼p[f(x)2q(x)p(x)]−(Ex∼p[f(x)])2从中可以看出如果两者相差太大,就会导致 p ( x ) q ( x ) \frac{p(x)}{q(x)} q(x)p(x)的值太大或是太小,从而导致两个分布之间的差别太大。下面通过图像可视化的理解以下上述的问题,蓝色实线表示分布 p ( x ) p(x) p(x),绿色实线表示真实采样的分布 q ( x ) q(x) q(x)。从图中可以看出两者的分布是相反的,如果使用这样的 q ( x ) q(x) q(x)去逼近 p ( x ) p(x) p(x), q ( x ) q(x) q(x)在右面奖励为正的部分采样的概率更大,因此大部分情况下奖励值均是大于零的,可能会在左边采样导致结果符合真实情况,但是因为概率太小,要达到这样的结果往往需要采样很多次,这样耗费的时间将会很多,因此两者之间的差别不应该太大。
在重要性采样中可知,理论上可以使用任意的 q ( x ) q(x) q(x)来近似 p ( x ) p(x) p(x),只要两者间的差别不是很大即可。但有时一个满足要求的 q ( x ) q(x) q(x)是不易找到的,这时就可以采用另外一个工具马尔可夫链蒙特卡罗方法(Markov Chain Monte Karlo,MCMC)。马尔科夫链定义本身比较简单,它假设某一时刻状态转移的概率只依赖于它的前一个状态。MCMC的原理是:从某个可取任意值的状态 x x x出发,随着时间的推移,随即反复的更新状态 x x x,最终 x x x会成为一个从 p ( x ) p(x) p(x)中抽出的(非常接近)比较一般的样本。在MCMC的马尔可夫链中包含两个部分:
- 随机状态 x x x:表示某时刻的状态
- 转移分布 T ( x ′ ∣ x ) T(x'|x) T(x′∣x):表示从 x x x随即转移到 x ′ x' x′的概率
下面考虑并行运行多个马尔可夫链的情况,其中每一个均是采样自 q ( x ) q(x) q(x),使用 q 0 q^0 q0来初始化 x x x。如果用向量描述 q ( x ) q(x) q(x)有 q ( x = i ) = v i q(\mathrm{x}=i)=v_{i} q(x=i)=vi,对于单一链的状态转移来说有 q ( t + 1 ) ( x ′ ) = ∑ x q ( t ) ( x ) T ( x ′ ∣ x ) q^{(t+1)}\left(x^{\prime}\right)=\sum_{x} q^{(t)}(x) T\left(x^{\prime} | x\right) q(t+1)(x′)=∑xq(t)(x)T(x′∣x),进一步的将 T T T看作矩阵 A : A i , j = T ( x ′ = i ∣ x = j ) A:A_{i, j}=T\left(\mathrm{x}^{\prime}=i | \mathrm{x}=j\right) A:Ai,j=T(x′=i∣x=j)的话,有如下的推导 v ( t ) = A t v ( 0 ) = ( V diag ( λ ) V − 1 ) t v ( 0 ) = V diag ( λ ) t V − 1 v ( 0 ) \boldsymbol{v}^{(t)}=A^tv^{(0)}=\left(\boldsymbol{V} \operatorname{diag}(\boldsymbol{\lambda}) \boldsymbol{V}^{-1}\right)^{t} \boldsymbol{v}^{(0)}=\boldsymbol{V} \operatorname{diag}(\boldsymbol{\lambda})^{t} \boldsymbol{V}^{-1} \boldsymbol{v}^{(0)} v(t)=Atv(0)=(Vdiag(λ)V−1)tv(0)=Vdiag(λ)tV−1v(0)
最终这个过程会收敛到均衡分布,得到 v ′ = A v = v v'=Av = v v′=Av=v,此时 q q q将等于 p p p。但是这样的方法也有很多的缺点:
- 无法预知何时到达均衡分布
- 到达均衡分布前磨合时间较长
- 采样两个互不相关的样本耗费时间较长
另外在确定 q ( x ) q(x) q(x)是否为一个有效的分布时,常用的有两种方法:
- 从学习到的分布 p m o d e l p_{model} pmodel中推导出 T T T,如Gibbs采样
- 直接用参数描述 T T T
因为目前还用不到,所以就不写啦~
P.S. GoodFellow的《Deep Learning》第17章第5小节关于不同的峰值之间的混合挑战部分很有意思,有兴趣的可以看一下.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









