




 StarSpace是一种由FAIR提出的神经嵌入模型,能处理多种嵌入形式,包括文本分类、信息检索、推荐系统及多关系图的嵌入。它通过将不同实体学习到同一空间中,实现了不同类型实体的比较。
StarSpace是一种由FAIR提出的神经嵌入模型,能处理多种嵌入形式,包括文本分类、信息检索、推荐系统及多关系图的嵌入。它通过将不同实体学习到同一空间中,实现了不同类型实体的比较。
StarSpace: Embed All The Things!
论文地址:https://arxiv.org/abs/1709.03856
GitHub:https://github.com/facebookresearch/StarSpace
收录于:AAAI 2018

本文是FAIR发表于2018 AAAI上的一篇文章,提出了一种通用性很强的神经嵌入模型, s t a r ( ∗ ) star(*) star(∗) 表示它可以处理多种形式的嵌入, s p a c e space space表示将不同的实体学习到一个空间中。它可以解决一系列不同的复杂问题,比如:
- 标注任务(labeling task):文本分类、情绪分类……
- 排序任务(ranking task):信息检索、网络搜索……
- 基于协同过滤或是基于内容的推荐任务:推荐文档、音乐等
- 多关系图的嵌入任务:如Freebase
- 学习词、句子、文档不同层级的嵌入
反正就是感觉厉害到不行~
主要贡献在于:
-
提出了一种新的嵌入学习算法,可以在不同的问题上进行泛化
-
可以实现不同类型的嵌入之间的相互比较。例如,可以将用户实体与推荐问题中的商品实体进行比较
StarSpace
StarSpace包含一系列的学习实体(learning entities),每一个实体被一系列的离散特征所描述(在本文所提出的模型中并不能泛化到连续特征的情况,在结论部分作者也提出连续特征的情况是未来的一个研究方向)。在StarSpace中,类似文档、句子这样的实体可以通过bag-of-words或n-grams进行描述,一个像user、movies、items等这样的实体可以通过bag-of-document的方式进行描述。重要的是,StarSpace模型将不同的实体通过学习嵌入到了一个相同的空间中,因此可以自由比较不同类型的实体。最终的目标是习得一个 D × d D \times d D×d 的矩阵,其中 D D D 表示特征的数量, d d d表示每一个嵌入向量的维度(或长度)。每一个实体 a a a 可以表示为 ∑ i ∈ a F i \sum_{i \in a} F_{i} ∑i∈aFi ,其中 F i F_{i} Fi 表示得到的嵌入矩阵 i t h i^{th} ith 个 d d d 维的特征。
训练过程需最小化的损失函数为:
∑
(
a
,
b
)
∈
E
+
b
−
∈
E
−
L
b
a
t
c
h
(
s
i
m
(
a
,
b
)
,
s
i
m
(
a
,
b
1
−
)
,
.
.
.
,
s
i
m
(
a
,
b
k
−
)
)
\sum_{(a,b)\in E^+\\b^- \in E^-}{L^{batch}(sim(a,b), sim(a,b_1^-),...,sim(a,b_k^-))}
(a,b)∈E+b−∈E−∑Lbatch(sim(a,b),sim(a,b1−),...,sim(a,bk−))
其中的正实体集(positive entity pairs)
E
+
E^+
E+和负实体集
E
−
E^-
E−取决于不同的问题。这里采用的是类似于word2vec中的k-negative sampling来采样得到负实体
b
i
−
b_{i}^-
bi−,不同实体之间的相似度度量函数
s
i
m
(
.
,
.
)
sim(.,.)
sim(.,.)这里选择的是常用的余弦相似度(cosine similarity)
Generally, they work similarly well for small numbers of label features (e.g. for classification), while cosine works better for larger numbers, e.g. for sentence or document similarity.
损失函数 L b a t c h L_{batch} Lbatch 这里选择的是margin ranking loss。
We also implement two possibilities: margin ranking loss and negative log loss of softmax. All experiments use the former as it performed on par or better.
在模型的优化过程中,仍然使用的是随机梯度下降(SGD),同时使用嵌入的最大范数(max-norm)来将嵌入向量限制在球半径为 r r r的空间 R d R^d Rd上。
测试时,可以使用学到的函数 s i m ( ⋅ , ⋅ ) sim(⋅,⋅) sim(⋅,⋅)来测量实体间的相似度。例如,对于分类,为给定输入a预测一个label,使用 m a x b ^ s i m ( a , b ^ ) max_{\hat{b}} sim(a,\hat{b}) maxb^sim(a,b^)来表示可能的 l a b e l b ^ label \hat{b} labelb^;对于ranking,通过similarity对实体进行排序。另外embedding向量可以直接被下游任务使用。
对于不同的任务如何生成 E + E^+ E+和 E − E^- E− 这里略~
实验
多类别分类问题(Multiclass classification)
在这个实验中, E + E^+ E+和 E − E^- E−来自文本分类数据集,作者分别在如下的3个不同的数据集上进行了实验:
- AG news:一个给定标题和描述字段的4类别文本分类任务,包含120 k个训练示例、7600个测试示例、4个类别、大约100 k个词和5 M个符号(token);
- DBpedia:维基百科文章分类问题,包含560 k训练示例、70 k测试示例、14个类、大约800k单词和32 M tokens;
- Yelp reviews dataset from 2015 Yelp Dataset Challenge:预测给定评论文本的star的总数,它包含1.2 M训练示例、157 k测试示例、5个类别、约50万单词,1.93 M tokens。
实验结果如下所示:
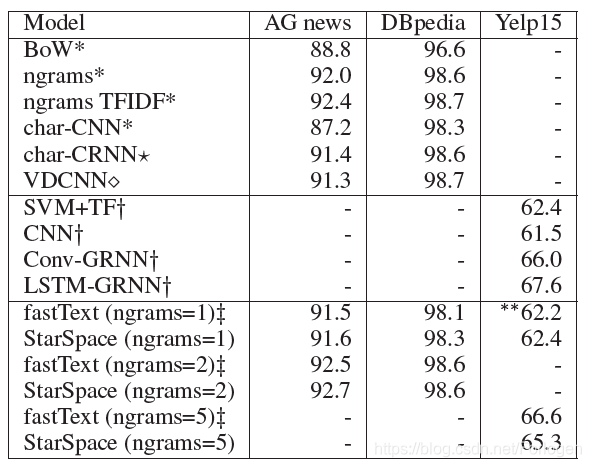
从中可以看出,StarSpace和fastText效果差别不大,但两者都优于其他的基准模型。特别是当 n − g r a m > 1 n-gram >1 n−gram>1时,fastText的速度要更快一些,但是StarSpace的通用性更强。

基于内容的文档推荐(Content-based Document Recommendation)
任务为基于用户的喜欢记录的历史向他们推荐社交媒体上的帖子。一个帖子可以表示为一个 b a g − o f − w o r d s bag-of-words bag−of−words的形式。所用的数据集由641385个用户和3119909篇文章组成。问题是根据前 ( n − 1 ) (n - 1) (n−1)篇文章预测第 n t h n^{th} nth篇文章,实验结果如下所示:
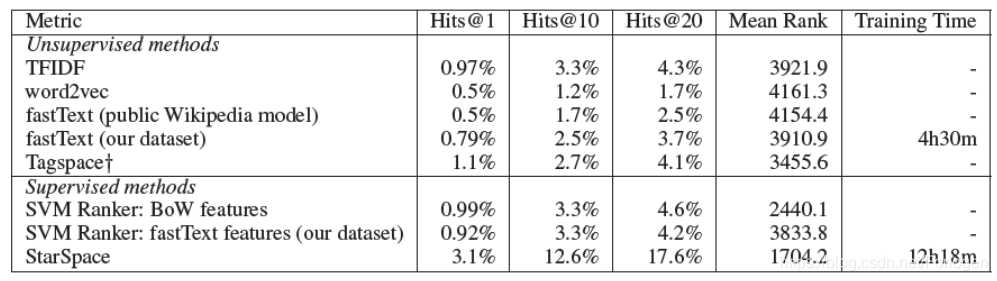
其中涉及的基准测试模型有:
- word2vec model
- Unsupervised fastText model
- Linear SVM ranker
- Tagspace model trained on a hashtag task
- TFIDF bag-of-words cosine similarity model
在这个任务上,StarSpace的效果也明显优于其他的基准模型。
连接预测:多联系的知识图谱的嵌入任务(Link Prediction: Embedding Multi-relation Knowledge Graphs)
Freebase 15 k数据集由一个triplets ( h e a d 、 r e l a t i o n t y p e 、 t a i l ) (head、relation_type、tail) (head、relationtype、tail)组成,例如:(Obama,born-in,Hawaii)。它的任务是在 ( ? , r e l a t i o n t y p e , t a i l ) (?, relation_type, tail) (?,relationtype,tail)中预测 h e a d head head,或$ (head, relation_type, ?) 中 预 测 中预测 中预测tail$。所用数据集由14951个概念(concepts)和1345个关系类型(relation_type)组成。训练集有483142个triplets,验证集有50000个,测试集有59071个,实验结果如下所示:
结果也是StarSpace的效果更好。同时作者也探究了 K = ? K=? K=?对于模型效果的影响,结果如下:
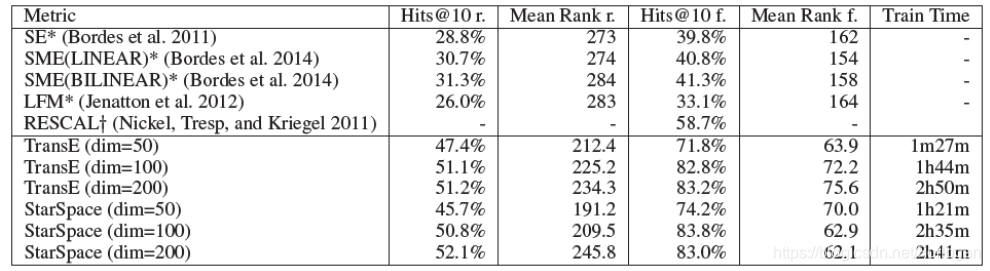
证明了 k k k的最优区间为[1,100], K = 50 K=50 K=50 时效果最好。

维基百科文章搜索和句子匹配(Wikipedia Article Search & Sentence Matching)
任务使用的是Wikipedia 数据集,对于每一篇文章,只提取纯文本,并删除列表和图等所有结构化数据部分。它总共包含5075,182篇文章,其中包含9,008,962种惟一的无大小写token类型。数据集分为5035182个训练示例、10,000个验证示例和10,000个测试示例。
- 任务1:将文章中的某个句子做为查询,试图找到它出自的文章;
- 任务2:从文章中随机选择两个句子,使用其中一个作为查询,然后尝试找到来自相同原始文档的另一个句子
实验结果如下所示:
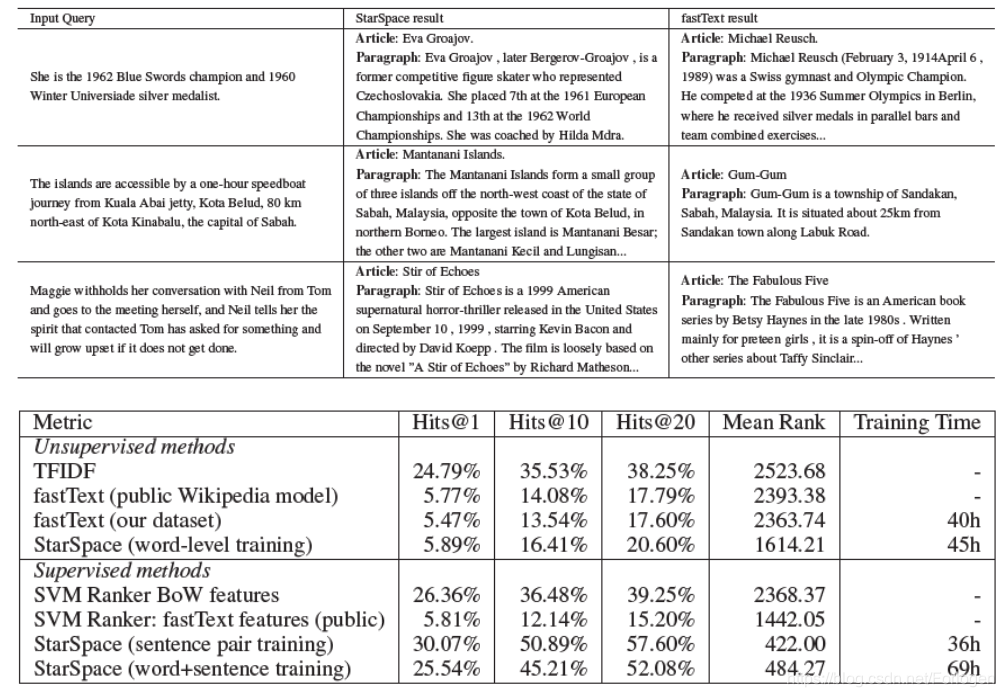
实验证明StarSpace的查询更加精准,效果更好。
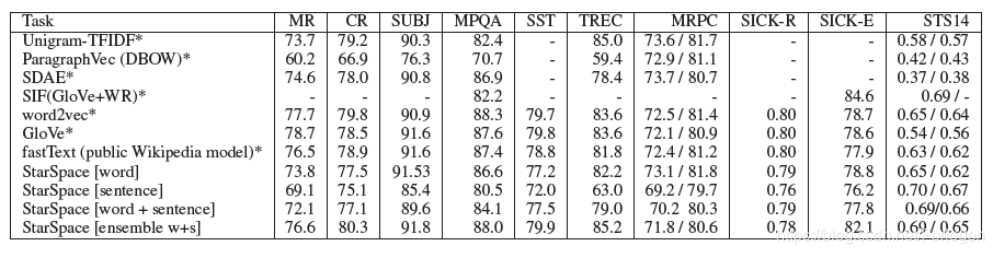
学习句子嵌入(Learning Sentence Embeddings)
任务使用Facebook research的工具SentEval,比较了句子嵌入模型在14个转换任务上的有效性,这些任务包括二进制分类、多类分类、隐含、检测、释义关联和语义文本相似性,实验结果如下所示:

















 724
724

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









