






 LAPGAN是一种在拉普拉斯金字塔框架下使用级联卷积网络,从粗略到精细逐步生成高质量自然图像的GAN变体。它放弃了全局保真度的概念,专注于每一步的生成结果,逐步生成清晰的图像。LAPGAN在CIFAR10、STL、LSUN数据集上的表现优于其他方法。
LAPGAN是一种在拉普拉斯金字塔框架下使用级联卷积网络,从粗略到精细逐步生成高质量自然图像的GAN变体。它放弃了全局保真度的概念,专注于每一步的生成结果,逐步生成清晰的图像。LAPGAN在CIFAR10、STL、LSUN数据集上的表现优于其他方法。
《Deep Generative Image Models using a Laplacian Pyramid of Adversarial Networks》

本文关注的是如何生成较高分辨率的图像这个传统的GAN无法解决的问题。相关的GAN的变体也有很多,像BigGAN、StackGAN、PGGAN、SRGAN等,而本文作者提出的是一种在拉普拉斯金字塔框架下使用级联卷积网络,从粗略到精细逐步生成高质量的自然图像的GAN的变体,称为LAPGAN。在金字塔的每一层都是使用GAN的方法训练单独的生成卷积网络模型,经过实验证明了LAPGAN的效果优于在它之前的其他相关的方法。
LAPGAN的关键之处在于它放弃了全局保真度的概念,即它不是专注于一次生成一张清晰的图像,而是专注于每一步的结果,让每次的生成结果都合理,逐步的生成清晰的结果。此外使用金字塔这样的结构,使得模型难以简单的记住训练实例来达到较好的效果。
整个LAPGAN的架构可以简单的看成是CGAN和拉普拉斯金字塔的一种结合,金字塔的每一层都是学习与相邻层之间的残差,也就是说,高分辨率图像的生成是以低分辨率图像作为条件去生成残差,然后低分辨率图上采样再跟残差求和得到高分辨率图,这种低分辨率图向高分辨率图生成的过程其实就是一个CGAN,通过不断堆叠 CGAN 得到我们想要的分辨率。
拉普拉斯金字塔
有关拉普拉斯金字塔和高斯金字塔的基本理解可参考:
https://zhuanlan.zhihu.com/p/32815143
简单的可以理解为:
- 高斯金字塔用于图像的下采样,相当于减小图像的尺寸,顺序是从底层到顶层
- 拉普拉斯金字塔用于图像的上采样,相当于扩大图像的尺寸,顺序是从顶层到底层,它需要配合高斯金字塔一起使用
下面看一下文章中对于拉普拉斯金字塔的介绍。它是线性可逆的图像表示,由一组带通图像组成,在空间上相隔一个八度,另加上低频残差。其中
- d ( . ) d(.) d(.):下采样,它可以模糊和抽取 j × j j \times j j×j的图像 I I I,生成 j 2 × j 2 \frac{j}{2} \times \frac{j}{2} 2j×2j的新图像 d ( I ) d(I) d(I)
- u ( . ) u(.) u(.):上采样,它平滑和扩展图像为原图像 I I I的两倍,即 u ( I ) u(I) u(I)表示 2 j × 2 j 2j \times 2j 2j×2j的新图像
但是要使用拉普拉斯金字塔,首先要建立一个高斯金字塔
G
(
I
)
=
[
I
0
,
I
1
,
…
,
I
K
]
\mathcal{G}(I)=\left[I_{0}, I_{1}, \ldots, I_{K}\right]
G(I)=[I0,I1,…,IK],其中
I
0
=
I
I_{0}=I
I0=I,
I
K
I_{K}
IK是重复应用
d
(
.
)
d(.)
d(.)到图像
I
I
I上的运算结果。例如,
I
2
=
d
(
d
(
I
)
)
I_{2}=d(d(I))
I2=d(d(I)),
k
k
k是所选择的的金字塔的级别数。拉普拉斯金字塔
L
(
I
)
\mathcal{L}(I)
L(I)的每个级别
k
k
k处的参数
h
k
h_{k}
hk通过取高斯金字塔中的相邻级别之间的差异来构造,用
u
(
.
)
u(.)
u(.)对较小的级别进行上采样,使得它们在大小上是兼容的:
h
k
=
L
k
(
I
)
=
G
k
(
I
)
−
u
(
G
k
+
1
(
I
)
)
=
I
k
−
u
(
I
k
+
1
)
h_{k}=\mathcal{L}_{k}(I)=\mathcal{G}_{k}(I)-u\left(\mathcal{G}_{k+1}(I)\right)=I_{k}-u\left(I_{k+1}\right)
hk=Lk(I)=Gk(I)−u(Gk+1(I))=Ik−u(Ik+1)
直观地说,每个级别捕获以特定比例呈现的图像结构。最后的拉普拉斯金字塔
h
k
h_{k}
hk不是差异图像,而是等于最终高斯金字塔层级之间的低频残差,即
h
k
=
I
k
h_{k}=I_{k}
hk=Ik。从拉普拉斯金字塔系数
[
h
1
,
.
.
.
,
h
k
]
[h_1,... ,h_k]
[h1,...,hk]重建图像的方式是由后向前的进行如下迭代:
I
k
=
u
(
I
k
+
1
)
+
h
k
I_{k}=u\left(I_{k+1}\right)+h_{k}
Ik=u(Ik+1)+hk
以
I
k
=
h
k
I_{k}=h_{k}
Ik=hk开始,重建图像为
I
=
I
0
I=I_{0}
I=I0。换言之,从最粗糙的级别开始进行重复上采样,并将差异图像
h
h
h 添加到下一个更精细的级别,直到能够重建全分辨率的原始图像
LAPGAN
我们可以从样本生成的过程理解LAPGAN,如下所示
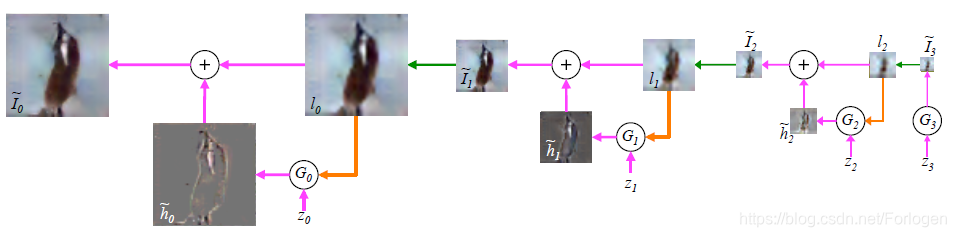
拉普拉斯金字塔的每一层都是由GANs组成,在顶层的生成器的输入只有噪声 z z z,而后像素更高的图像被用来训练CGAN,输入不光有噪声,还有同级的高斯金字塔的图像经过上采样得到的图像。每一层的GANs都用来捕获图像系数 h k h_{k} hk的分布,这个过程类似于上面 I k = u ( I k + 1 ) + h k I_{k}=u\left(I_{k+1}\right)+h_{k} Ik=u(Ik+1)+hk,只不过生成模型被用来生成 h k h_{k} hk:
I ~ k = u ( I ~ k + 1 ) + h ~ k = u ( I ~ k + 1 ) + G k ( z k , u ( I ~ k + 1 ) ) \tilde{I}_{k}=u\left(\tilde{I}_{k+1}\right)+\tilde{h}_{k}=u\left(\tilde{I}_{k+1}\right)+G_{k}\left(z_{k}, u\left(\tilde{I}_{k+1}\right)\right) I~k=u(I~k+1)+h~k=u(I~k+1)+Gk(zk,u(I~k+1))
例如, I 2 ~ \tilde {I_{2}} I2~ 经过上采样得到 l 1 l_{1} l1 ,和随机噪声 z 1 z_{1} z1一起输入到 G 1 G_{1} G1中生成 h 1 ~ \tilde{h_{1}} h1~,然后 h 1 ~ \tilde{h_{1}} h1~和 l 1 l_{1} l1相加得到 I 1 ~ \tilde{I_{1}} I1~ ,整个过程可以表示为 I 1 ~ = u ( I 2 ~ ) + G 1 ( z 1 , u ( I ~ 2 ) ) \tilde{I_{1}}=u(\tilde{I_{2}})+G_{1}(z_{1},u(\tilde{I}_{2})) I1~=u(I2~)+G1(z1,u(I~2))。
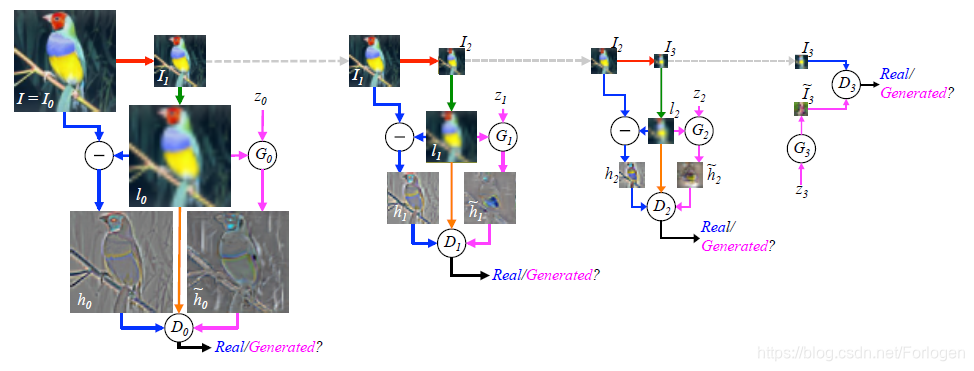
其中每一层的生成模型 G k G_{k} Gk 均使用CGAN的方法进行训练, G k G_{k} Gk是粗尺度图像,输入为 I k ~ \tilde{I_{k}} Ik~和 z k z_{k} zk,而 D k D_{k} Dk将 h k ~ \tilde{h_{k}} hk~或 h k h_{k} hk与低通图像 l k l_{k} lk一起作为输入,并预测图像是真实样本还是生成样本。在金字塔的最后一层,低频残差足够小,可以用标准GAN直接建模 h K ~ = G K ( z K ) \tilde{h_{K}}=G_{K}(z_{K}) hK~=GK(zK), D K D_{K} DK也只有 h k ~ \tilde{h_{k}} hk~或 h k h_{k} hk作为输入,整个过程如下所示
实验
作者在CIFAR10、STL、LSUN三个数据集上分别做了三中实验,验证LAPGAN的效果。
对数似然的估计
作者使用Gaussian Parzen窗口估计器来计算对数似然,从下图中可以看出,本文的方法的效果比GAN略微增加。LAPGAN模型的多尺度结构可以改进基础估算技术。这种新方法计算拉普拉斯金字塔每个尺度的概率,并将它们组合起来以得出整体图像的概率。
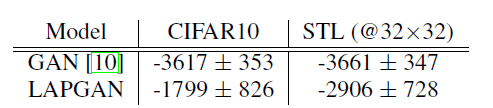
模型生成的样本
在CIFAR10,STL和LSUN数据集上训练的模型的生成样本依次如下所示



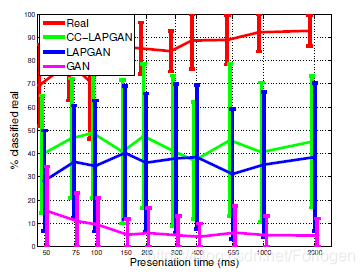
人类对样本的评价
为了获得样品质量的定量测量,作者邀请了15名志愿者参与实验,看看他们是否可以将样本与真实图像区分开来。结果显示LAPGAN模型产生的样本比标准GAN 更真实。
总结
作者提出了一种概念上简单的生成模型,能够生成高质量的样本图像,其质量优于其他深度生成建模方法。虽然它们表现出合理的多样性,但本文中无法确定它们是否涵盖了完整的数据分布。因此,本文的模型可能会在自然图像上为流形的某些部分分配低概率。量化这一点很困难,但可能通过人类主观的实验来完成。本工作的一个关键点是放弃任何“全局”保真度的概念,而是将其打破成合理的连续改进。注意到许多其他信号模型具有多尺度结构,可以从类似的方法中受益。

















 1660
1660

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









