






ICLR 2019 《Large Scale GAN Training For High Fidelity Natural Imge Synthesis》

BigGAN实现了对之前所有有关生成高分辨率的GAN变体的超越,生成的图像真的是太真实了,太秀了!

文章中虽然没有太多的数学公式和方法的改变,但是借助强大的计算力,把生成的结果质量提高了一个很高的层次,512块TPU啊,我连块GPU都么得!!默默的留下了穷人的眼泪,人家做科研靠头脑加设备,我们做科研全靠吹水,?
文章大部分的内容都是在阐释作者的思路,具体的可以参考:
-
论文的主要内容
https://cloud.tencent.com/developer/article/1375746
https://blog.youkuaiyun.com/c9Yv2cf9I06K2A9E/article/details/83026880
https://blog.youkuaiyun.com/qq_14845119/article/details/85619705
-
有关BigGAN的报道
https://www.jianshu.com/p/b36c20df2586
http://www.sohu.com/a/273780404_473283
http://www.sohu.com/a/275014717_129720
http://www.sohu.com/a/257335499_473283
http://www.chainske.com/a/show.php?itemid=5028
https://www.sohu.com/a/257110847_610300
下面主要记录一下其中不太理解的一些做法,主要包括谱归一化(Spectral Normalization)、截断技巧(Truncation Trick)和正交正则化(orthogonal regularization)
Spectral Normalization
https://blog.youkuaiyun.com/c9Yv2cf9I06K2A9E/article/details/87220341
https://www.jiqizhixin.com/articles/2018-10-16-19
https://www.jianshu.com/p/d6224fee3365
https://blog.youkuaiyun.com/StreamRock/article/details/83590347
https://blog.youkuaiyun.com/songbinxu/article/details/84581248
在《Spectral Normalization for Generative Adversarial Networks》(https://arxiv.org/pdf/1802.05957.pdf) 这篇文章中,作者对于谱归一化做了详细介绍,等读完后再记录。
Truncation Trick
之前GAN的生成的输入噪声采样自某个先验分布 z z z,一般情况下都是选用标准正态分布 N ( 0 , I ) N(0,I) N(0,I) 或者均匀分布 U [ − 1 , 1 ] U[−1,1] U[−1,1]。所谓的“截断技巧”就是通过对从先验分布 z z z 采样,通过设置阈值的方式来截断 z 的采样,其中超出范围的值被重新采样以落入该范围内。这个阈值可以根据生成质量指标 IS 和 FID 决定。
我们可以根据实验的结果好坏来对阈值进行设定,当阈值的下降时,生成的质量会越来越好,但是由于阈值的下降、采样的范围变窄,就会造成生成上取向单一化,造成生成的多样性不足的问题。往往 IS 可以反应图像的生成质量,FID 则会更假注重生成的多样性。
例如在文中作者也给出了使用截断技巧的实验结果图,其中从左到右,阈值=2,1.5,1,0.5,0.04

从结果可以看出,随着截断的阈值下降,生成的质量在提高,但是生成也趋近于单一化。所以根据实验的生成要求,权衡生成质量和生成多样性是一个抉择,往往阈值的下降会带来 IS 的一路上涨,但是 FID 会先变好后一路变差。
orthogonal regularization
同时作者还发现,在一些较大的模型中嵌入截断噪声会产生饱和伪影,如下所示

因此,为了解决这个问题,作者通过将
G
G
G调节为平滑来强制执行截断的适应性,以便让
z
z
z 的整个空间将映射到良好的输入样本。为此,文中引入了正交正则化,直接强制执行正交性条件
R
β
(
W
)
=
β
∥
W
⊤
W
−
I
∥
F
2
R_{\beta}(W)=\beta\left\|W^{\top} W-I\right\|_{\mathrm{F}}^{2}
Rβ(W)=β∥∥W⊤W−I∥∥F2
其中
W
W
W是权重矩阵,
β
\beta
β是超参数。文中为了放松约束同时实现所需的平滑度,从正则化中删除了对角项,旨在最小化滤波器之间的成对余弦相似性,但不限制它们的范数
R
β
(
W
)
=
β
∥
W
T
W
⊙
(
1
−
I
)
∥
F
2
R_{\beta}(W)=\beta\left\|W^{T} W \odot(1-I)\right\|_{F}^{2}
Rβ(W)=β∥∥WTW⊙(1−I)∥∥F2
其中
1
1
1表示一个矩阵,所有元素都设置为 1
Tips
- 增加网络深度会使得精度降低,后续在bigGAN-deep中使用不同的残差快解决了这个问题
- 在判别器上使用共享嵌入参数的方法,对参数的选择非常敏感,刚开始有助于训练,后续则很难优化
- 使用WeightNorm 替换BatchNorm 会使得训练难以收敛,去掉BatchNorm 只有Spectral Normalization 也会使得难以收敛
- 判别器中增加BatchNorm 会使得训练难以收敛
- 在 128 × 128 128 \times128 128×128的输入情况下,改变attention block对精度没提升,在 256 × 256 256 \times 256 256×256输入的情况下,将attention block上移一级,会对精度有提升
- 相比采用 3 × 3 3 \times 3 3×3的滤波器,采用 5 × 5 5\times5 5×5的滤波器会使精度有略微提升,而 7 × 7 7\times7 7×7则不会
- 使用扩张卷积会降低精度
- 将生成器中的最近邻插值换为双线性插值会使得精度降低
- 在共享嵌入中使用权值衰减(weight decay),当该衰减值较大(10-6 )会损失精度,较小(10-8 )会起不到作用,不能阻止梯度爆
- 在类别嵌入中,使用多层感知机(MLP)并不比线性投影(linear projections)好。
- 梯度归一化截断会使得训练不平稳。
模型架构
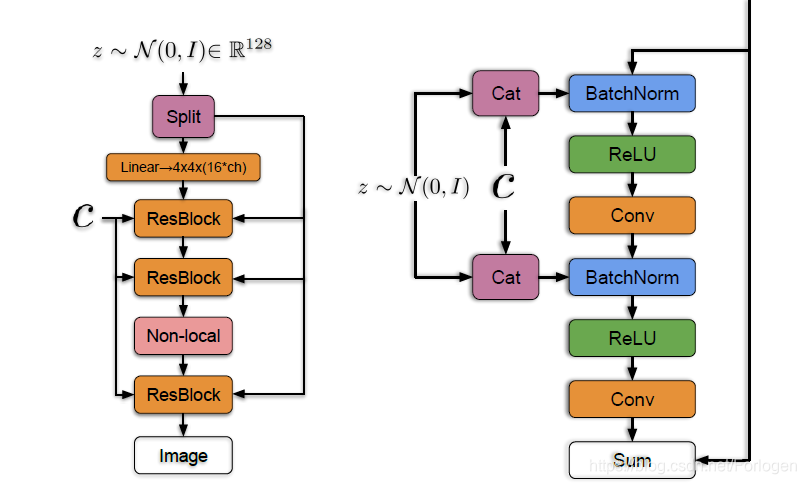
bigGAN的生成器架构如下所示,主要使用了ResNet做为基本的块,但是修改了D中的通道模式,使得每一块的第一个卷积层中的滤波器数量等于输出滤波器的数量。此外在G中使用共享类嵌入(shared class embedding),它为BN层产生每个样本的增益(以1为中心)和偏置(以0为中心)。而且 z z z并非只是作为第一层的输入,而是沿着通道的维数被分割成大小相等的块,每个块分别与类嵌入的副本进行连接,然后传到给定的残差块中。
总结
bigGAN以及后续的改进版本bigGAN-deep大幅的提高了生成图像的质量,但是这还是大公司之间的游戏呀,作为普通的研究者或爱好人员,真是可望不可及。但文中使用的梯度截断、正交正则化等训练技巧,以及对于问题的分析方式和实验的设置仍然有很多可以借鉴的地方,隔一段时间重读都会有新的体会~


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









