




 本文总结了机器学习课程中的关键原则,如奥卡姆剃刀原则、抽样偏差及避免数据偷窥的重要性。强调了选择简单模型、确保数据独立同分布及避免过度依赖数据进行模型选择的必要性。并概述了数据挖掘、人工智能、统计分析等领域的关联,以及Hoeffding、Multi-Bin Hoeffding、VC等理论保证。
本文总结了机器学习课程中的关键原则,如奥卡姆剃刀原则、抽样偏差及避免数据偷窥的重要性。强调了选择简单模型、确保数据独立同分布及避免过度依赖数据进行模型选择的必要性。并概述了数据挖掘、人工智能、统计分析等领域的关联,以及Hoeffding、Multi-Bin Hoeffding、VC等理论保证。
上一讲学习了通过验证的方法来避免过拟合现象的发生,这一讲来学习几个在学习过程中重要的几个原则,并对这门课做一个简单的总结和对后面的学习做一个展望

第一个就是奥卡姆剃刀原则:在能解释清楚某个东西的基础上,能用简单的话就不要用复杂的

它反映到机器学习上是个什么意思呢?它指的是在所有可能选择的模型中,我们应该选择能够很好地解释已知数据并且十分简单的模型。比如之前的例子中,我们能用低阶的模型取得比较好的效果,就不要用更加复杂的模型
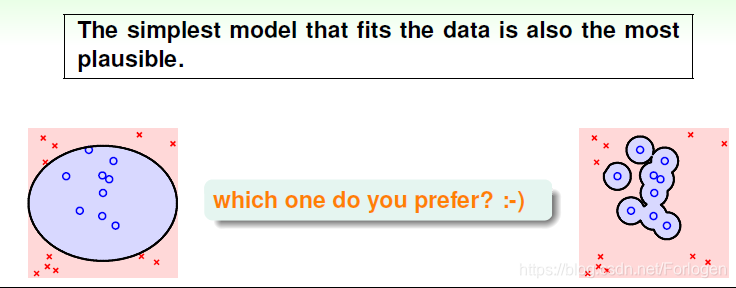
简单的模型一方面指的是简单的假设h,简单的假设就是指模型使用的特征比较少,例如多项式阶数比较少。简单模型指的是模型H包含的假设h数目有限,不会太多。其实,simple hypothesis h和simple model H是紧密联系的。如果假设的特征个数是l,那么H中包含的假设个数就是2^l,也就是说,假设中的特征数目越少,模型中假设数目也就越少。所以,为了让模型简单化,我们可以一开始就选择简单的模型,或者用正则化,让假设中参数个数减少,都能降低模型复杂度

另一个就是,如果抽样有偏差的话,那么学习的结果也产生了偏差,这种情形称之为抽样偏差Sampling Bias。从技术上来说,就是训练数据和验证数据要服从同一个分布,最好都是独立同分布的,这样训练得到的模型才能更好地具有代表性

再就是不要人工的偷窥数据,来自以为的减小模型的复杂度

在机器学习过程中,避免“偷窥数据”非常重要,但实际上,完全避免也很困难。实际操作中,有一些方法可以帮助我们尽量避免偷窥数据。第一个方法是“看不见”数据。就是说当我们在选择模型的时候,尽量用我们的经验和知识来做判断选择,而不是通过数据来选择。先选模型,再看数据。第二个方法是保持怀疑。就是说时刻保持对别人的论文或者研究成果保持警惕与怀疑,要通过自己的研究与测试来进行模型选择,这样才能得到比较正确的结论

最后对于这门课总了一个简单的总结,首先是和机器学习有关的三个领域:数据挖掘、人工智能和统计分析
• Data Mining
• Artificial Intelligence
• Statistics

三个理论保证
• Hoeffding
• Multi-Bin Hoeffding
• VC

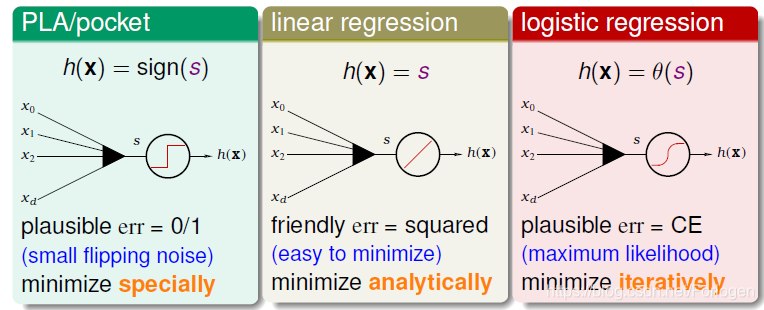
三种线性模型:
• PLA/pocket
• linear regression
• logistic regression
三种重要的工具:
• Feature Transform
• Regularization
• Validation

三个锦囊妙计:
• Occam’s Razer
• Sampling Bias
• Data Snooping

接下来学习的相关方面的知识:
• More Transform
• More Regularization
• Less Label

总体来看这一讲干货不多,更多是一个印象的加深

终于在开学前把拖了很久的这门课学习完了,也按时做了总结,开心呀,完成了一个小目标,啦啦啦啦啦~~~

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









