




 探讨了变分自编码器(VAE)在文本生成任务中的应用,包括无条件和条件文本生成,以及如何改进VAE以更好地捕获文本语义信息,避免posterior collapse现象。介绍了两篇最新研究,一篇是NAACL2019的Topic-Guided VAE,通过主题引导提升生成文本的相关性和丰富性;另一篇是ACL2019的多级潜变量模型,旨在生成更长、连贯的文本。
探讨了变分自编码器(VAE)在文本生成任务中的应用,包括无条件和条件文本生成,以及如何改进VAE以更好地捕获文本语义信息,避免posterior collapse现象。介绍了两篇最新研究,一篇是NAACL2019的Topic-Guided VAE,通过主题引导提升生成文本的相关性和丰富性;另一篇是ACL2019的多级潜变量模型,旨在生成更长、连贯的文本。
金秋十月注定是忙碌的,最近在总结自己的想法并进行代码实现,毕竟毕业才是大事呀,所以也没有时间总结自己看过的文章,结过就攒了一大堆,时间长了细节部分就记不清了,希望在这个月末将其总结出来,同时也希望为下一阶段的工作打好基础。

Text Generation based Variational Autoencoders
在前面介绍的关于文本摘要生成的文章中,绝大多是的模型仍然是基于RNN的Seq2Seq模型,以及最近大热的预训练模型,当然还有就是基于生成对抗网络(GAN)的方法。VAE作为一种强大的生成模型在视觉领域取得了不菲的成绩,那么它同样可以用于自然语言处理的各种文本生成任务中,下面就介绍两篇今年ACL和NAACL上两篇关于VAE用于文本生成的文章,它们虽然切中点有所不同,但仍能从中找到相通的地方,希望可以带来启发。
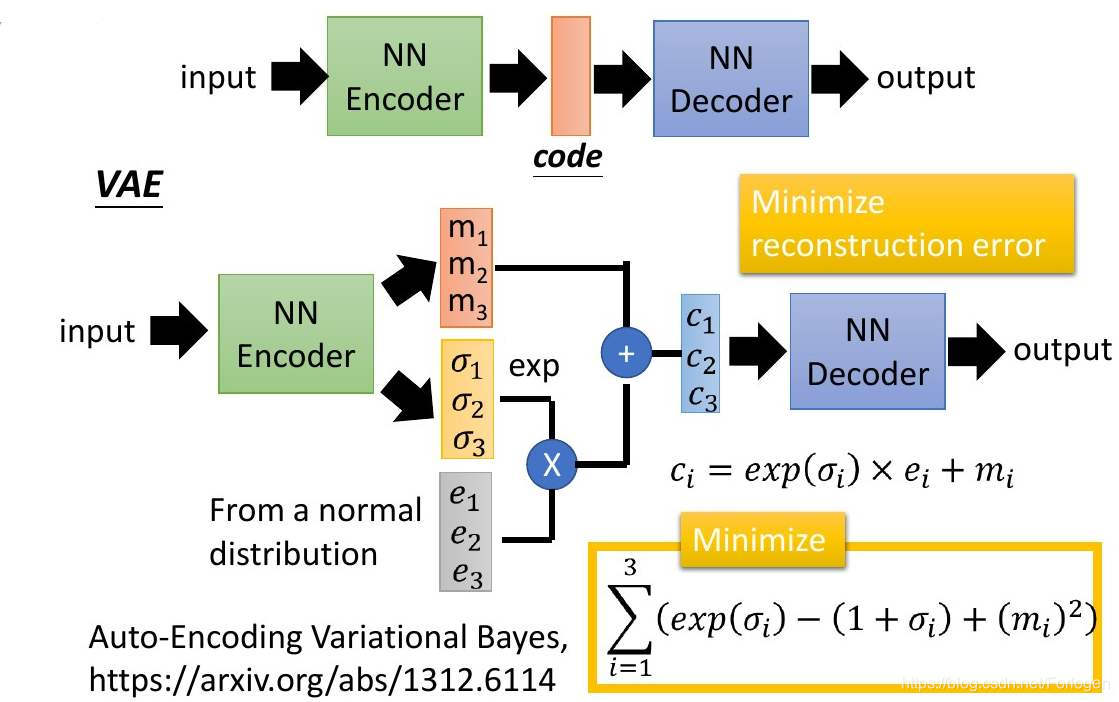
source: 李宏毅机器学习-2017-Deep Generative Model
有关VAE的理论介绍和代码实现可见我之前的一篇博文:VAE以及tensorflow-2.0实现
我看到过得最早的一片关于VAE做文本生成的文章是EMNLP2017 的《Deep Recurrent Generative Decoder for Abstractive Text Summarization》,同样在另一篇博文Development of Neural Network Models in Text Summarization - 1也有相应的解读。在此基础上,我们来看一下下面的这两篇文章的主要内容。
在标准的VAE中,模型往往是从标准正态中采样分布来逼近后验分布 p ( z ) p(z) p(z),这样一方面会使得VAE无法充分的捕获所处理文本丰富的语义信息,另一方面由于RNN的自回归的训练方式,Decoder极大可能会忽略 z z z所表示的信息,从而引发posterior collapse现象的发生。
因此如何改变 z z z采样的分布族,以及如何将所处理文本中丰富的信息传递给Decoder变得十分关键。以下的两篇文章都在这两方面做了一定的工作,将自己的想法融入了问题的解决过程中,而且均取得了不错的效果。
NAACL 2019 Topic-Guided Variational Autoencoders for Text Generation
在条件文本生成任务中,如果我们想要定制化生成文本的某些方面如情感、主题等,模型就需要接收一些表示这些条件的信息,那么如果将表示主题等信息的向量融入到文本的生成过程中,那么得到的结果应该就可以得到一定程度上的控制。
本文提出了一种基于主题指导的VAE模型(topic-guided variational autoencoder, TGVAE),它不再是从标准高斯分布中进行采样,而是将每一个主题模块都看作是一个高斯混合模型,即每一个混合成分都表示了一个对应的latent topic。那么直接从中进行采样,decoder在 解码的过程中过程中就会利用到latent code所表示的主题信息。另外,作者还采用了Householder Transformation 操作,使得latent code的近似后验具有较高的灵活性。实验证明TGVAE在无条件文本生成和条件文本生成任务中都可以取得更好的效果,并且模型可以生成不同主题下语义更加丰富的句子。而且通过主题信息的指导,使得模型在文本生成阶段所依赖的词汇表变小,从而减少解码过程的计算量。
模型整体的架构如下所示:
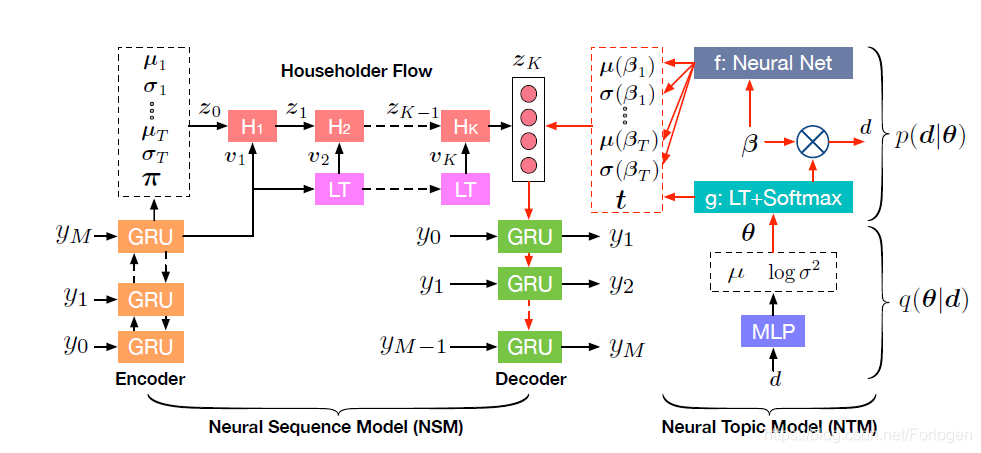
模型整体上可以分为两部分:
- 神经主题模型(Neural topic model,NTM): 负责捕获文本中长程的语义信息
- 序列生成模型(Neural Sequence model,NSM):在主题信息的指导下生成句子
假设
d
∈
Z
+
D
d \in Z_{+}^{D}
d∈Z+D是文本的表示,其中
D
D
D代表词汇表大小,
d
d
d中每一个元素表示了词在文本中出现的次数。
a
n
a_{n}
an表示
w
n
w_{n}
wn所对应的主题。这里采用已有的方法:将一个随机的高斯向量通过softmax函数来参数化多维的主题分布:
θ
∼
N
(
0
,
I
)
,
t
=
g
(
θ
)
\theta \sim N(0,I), t = g(\theta)
θ∼N(0,I),t=g(θ)
a
n
∼
D
i
s
c
r
e
t
e
(
t
)
,
w
n
∼
D
i
s
c
r
e
t
e
(
β
a
n
)
a_{n} \sim Discrete(t), w_{n} \sim Discrete(\beta_{a_{n}})
an∼Discrete(t),wn∼Discrete(βan)
首先从标准多维高斯分布中采样得到向量
θ
\theta
θ,
θ
\theta
θ通过转换函数
g
(
⋅
)
g(\cdot)
g(⋅)得到关于主题的嵌入表示
t
t
t。然后通过
D
i
s
c
r
e
t
e
(
⋅
)
Discrete(\cdot)
Discrete(⋅)来得到词
w
n
w_{n}
wn所对应的主题
a
n
a_{n}
an,而且可以通过
D
i
s
c
r
e
t
e
(
⋅
)
Discrete(\cdot)
Discrete(⋅)得到满足主题
a
n
a_{n}
an的词的分布。那么
d
d
d对应的边缘似然为:
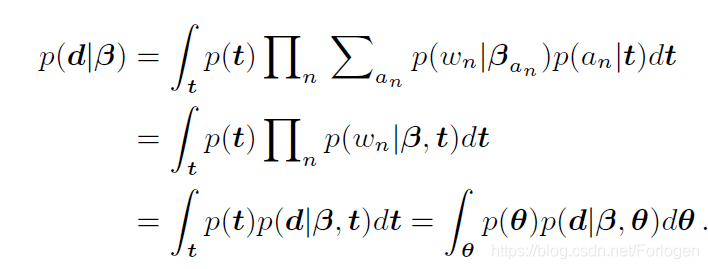
在得到了关于词的主题分布后,通过 μ ( β i ) = f μ ( β i ) , σ 2 ( β i ) = diag ( exp ( f σ ( β i ) ) ) \mu(\beta_{i}) = f_{\mu}(\beta_{i}),\sigma^{2}(\beta_{i}) = \text{diag}(\exp (f_{\sigma} (\beta_{i}))) μ(βi)=fμ(βi),σ2(βi)=diag(exp(fσ(βi)))来得到满足 μ \mu μ和 σ 2 \sigma^2 σ2的包含主题信息的高斯分布族,然后通过 p ( z ∣ β , t ) = ∑ i = 1 t t i N ( μ ( β i ) , σ 2 ( β i ) ) p(z|\beta,t)=\sum_{i=1}^t t_{i} N(\mu(\beta_{i}) ,\sigma^{2}(\beta_{i}) ) p(z∣β,t)=i=1∑ttiN(μ(βi),σ2(βi))得到 z z z用于后续的生成过程。因为采样分布表示了文本的主题信息,那么 z z z就会指导decoder生成符合主题的结果。
假设生成的词序列记为 y y y,那么decoder的生成过程为: p ( y ∣ z ) = p ( y 1 ∣ z ) ∏ m = 2 M p ( y m ∣ y 1 : m − 1 , z ) = p ( y 1 ∣ z ) ∏ m = 2 M p ( y m ∣ h m ) p(y|z) = p(y_{1}|z) \prod_{m=2}^M p(y_{m}|y_{1:m-1},z) = p(y_{1}|z) \prod_{m=2}^M p(y_{m}|h_{m}) p(y∣z)=p(y1∣z)m=2∏Mp(ym∣y1:m−1,z)=p(y1∣z)m=2∏Mp(ym∣hm)其中 h m = f ( h m − 1 , y m − 1 , z ) h_{m}=f(h_{m-1},y_{m-1},z) hm=f(hm−1,ym−1,z), f f f这里表示GRU单元。
在推断阶段,将所处理的文本输入到模型中首先得到主题向量 ,然后decoder需要根据主题向量重构输入文本。经过不断地训练,模型就得到了关于词的主题分布。然后从中采样就可以生成表示不同主题的文本。
文中另外占较大篇幅的的是介绍了Householder Transformation在文中的应用,这也是我第一次见到这个知识点,这里就无法给出哪怕简单的介绍,有兴趣的可以自行查阅相关资料。
最后作者将模型的应用延伸到了文本摘要任务
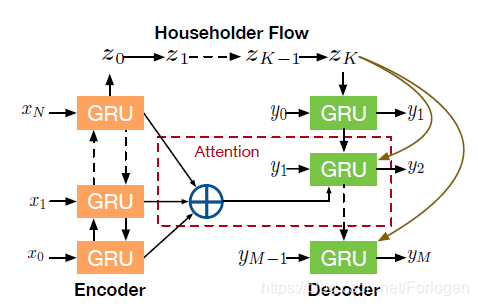
对于给定的文本和摘要配对数据,我们希望建模分布 p ( y , d ∣ x ) = ∫ θ ∫ z p ( θ ) p ( d ∣ β , θ ) p ( z ∣ β , θ ) p ( y ∣ x , z ) d θ d z p(y,d|x) = \int_{\theta} \int_{z} p_(\theta) p(d|\beta, \theta) p(z|\beta,\theta)p(y|x,z) d \theta d z p(y,d∣x)=∫θ∫zp(θ)p(d∣β,θ)p(z∣β,θ)p(y∣x,z)dθdz
那么此时摘要的生成不仅依赖于 基于注意力机制的Seq2Seq模型,还是受到 z z z所表示的主题信息的指导。
实验结果可见原文。
ACL 2019 Towards Generation Long and Coherent Text with Multi-Level Latent Variable Models
下面两篇解读都很好,这里就不重复了。
文本生成1:Towards Generating Long and Coherent Text
《Towards Generating Long and Coherent Text…》阅读笔记


















 433
433

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









