







CSDI: Conditional Score-based Diffusion Models for Probabilistic Time Series Imputation(基于得分扩散模型的条件时间序列插补)
近期在研究DDPM,一直在考虑其实际应用,后来偶然就发现了这篇用于时间序列插补的文章。在此简要讲解一下自己的学习。(会附上代码讲解)
为了方便大家,这里是
回顾扩散模型
首先,我们知道DDPM的流程如下: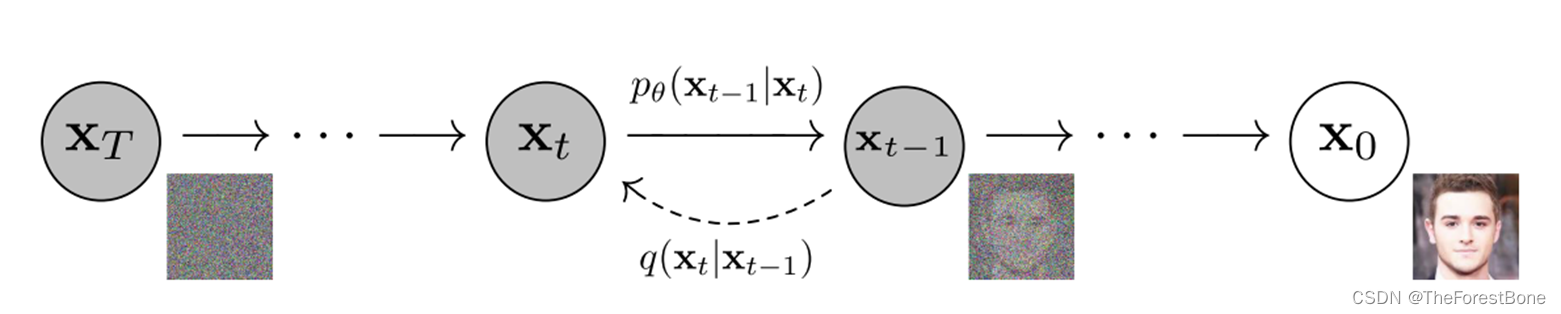
从一个图片集开始,对每一张图片一直添加随机噪声,直到T步,然后我们再逐步去噪,从而生成一些新的图片。
如何用于时间序列?
DDPM用于时间序列有很多方面,例如插补和预测。
插补的应用场景就是我们的缺失数据集,在这里我以文中的physio数据集为例,形式大概如下(整理好后的):
| 某位病人 | 病理特征1 | 病理特征2 | 病理特征3 |
|---|---|---|---|
| 凌晨1点 | 2 | ||
| 凌晨2点 | 3 | 5 | |
| 凌晨3点 | 3 | 2 | 1 |
原数据集有大约10134个病人,每位病人对应着35个病理特征和48个时间点。具体处理细节我会在后面的代码讲解中详细介绍,No rush。
我们的目的就是根据整体的特征去试图填补里面空缺的部分。
那么如果要用于预测呢?
那还不简单,我们只要把要预测的值认为是空缺的不就行了,比如下面:
| 某位病人 | 病理特征1 | 病理特征2 | 病理特征3 |
|---|---|---|---|
| 凌晨1点 | 2 | 2 | 3 |
| 凌晨2点 | 3 | 4 | 5 |
| 凌晨3点 |
Good,到现在我们已经清楚其应用场景了,接下来就是搞清楚其架构了。
CSDI的基础架构
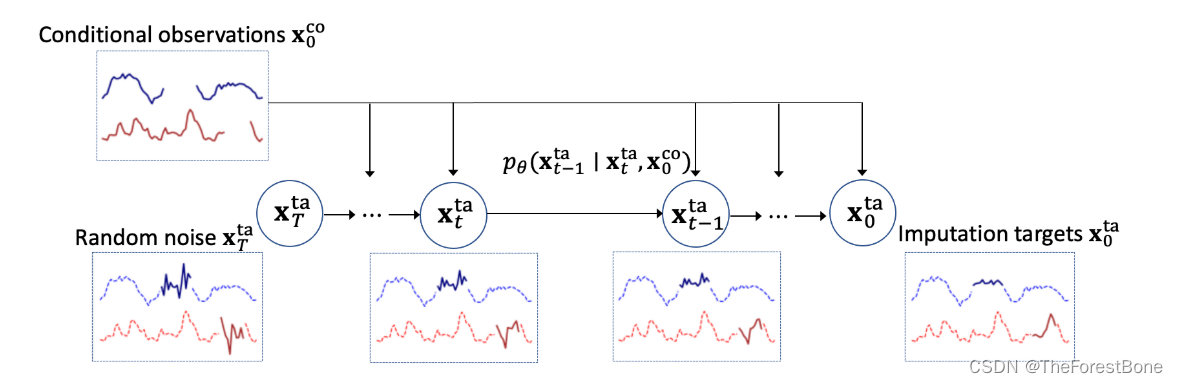
图中我们已有的就是左上角的蓝色线和红色线信息(文中称为条件观测值
x
0
c
o
x_0^{co}
x0co),中间空着的线段,那段空白就是要插值的部分,然后我们只针对于这部分空白进行加噪去噪。加噪到T时刻就是我们左下角的图片,然后进行去噪得到我们右下角的图片。
如此就完成了插值过程。
需要注意的是,我们在对该部分空白进行处理时,一般会给其填补一个初始的随机噪声开始。如下:
| 某位病人 | 病理特征1 | 病理特征2 | 病理特征3 |
|---|---|---|---|
| 凌晨1点 | 2 | Random Noise | 3 |
| 凌晨2点 | 3 | Random Noise | Random Noise |
| 凌晨3点 | 3 | Random Noise | 4 |
训练过程
在训练时,我们的数据集就已经是缺失的了。(是的,不是那种拿完整的数据集训练,然后在空缺的数据集填补)
所以,在训练过程中,我们根本没有空白部分的完整版样本,只能通过其他已知的部分来填补空白。
事实上,我们在训练过程并没有用到空白部分,原文提出的自监督训练过程如下:
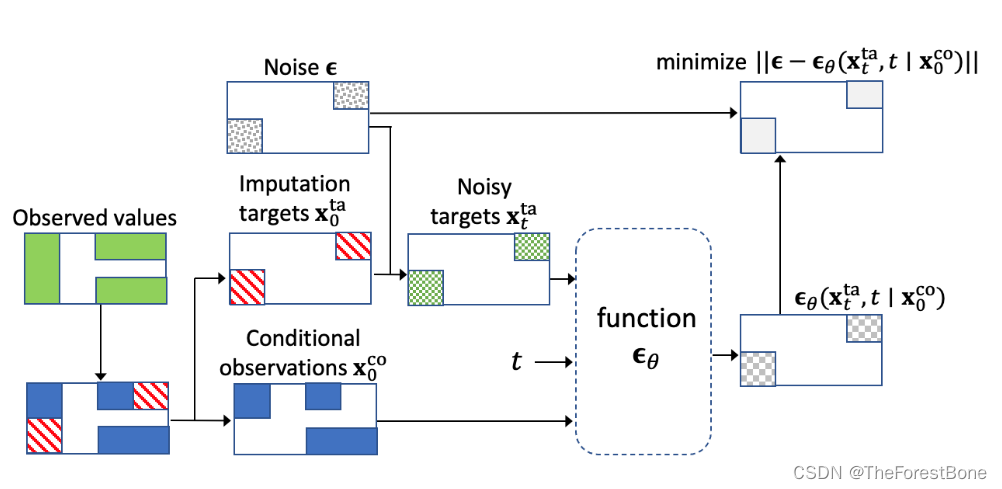
图中绿色部分指的是我们的已观测值,比如我们有一个样本如下:
| 某位病人 | 病理特征1 | 病理特征2 | 病理特征3 |
|---|---|---|---|
| 凌晨1点 | 2 | 2 | |
| 凌晨2点 | 3 | ||
| 凌晨3点 | 3 | 1 |
然后我们根据一定的策略去随机选择一部分给他人为遮住,作为我们要插补的目标:
| 某位病人 | 病理特征1 | 病理特征2 | 病理特征3 |
|---|---|---|---|
| 凌晨1点 | 2 | 遮住啦 | |
| 凌晨2点 | 3 | ||
| 凌晨3点 | 遮住啦 | 1 |
⚠️注意!!!
我们之后的任务就是用我们现在已知的信息(比如上面的数值2,3,1)去预测我们这些遮住的数值。
等我们这一个任务完成的较好的时候,就可以把预测<遮住啦>的模型用在预测空白上。
我们在实际代码运行中,是对这些遮住的噪声进行传统的DDPM扩散过程。并把预测值与其原有值进行对比来计算损失函数(这里要用上周围已知的信息,比如2,3,1。具体用的方式在下面会介绍)试图还原这些遮住数值,等这套体系训练好了,再把这套模型运用在空白部分。
在预测空白部分的时候是先给其赋予一些随机噪声作为起始。
(这部分如果不懂的话,后续出的代码详解可能会帮助你)
😆
我们看上面的图,可以知道除去遮掩部分的其他信息在我们的 x 0 c o x_0^{co} x0co里(2,3,1)。我们是肯定要用这部分信息的,不然得不到篮球和练习室的关系,没有任何意义。
- 可是问题就出在这里,我们的条件信息(就是已知信息 x 0 c o x_0^{co} x0co)应该如何用呢?
🐱🐱🐱
Yang Song的原始DDPM中其实也对这种条件模型用于插补做了一些设想,其架构大致如下:
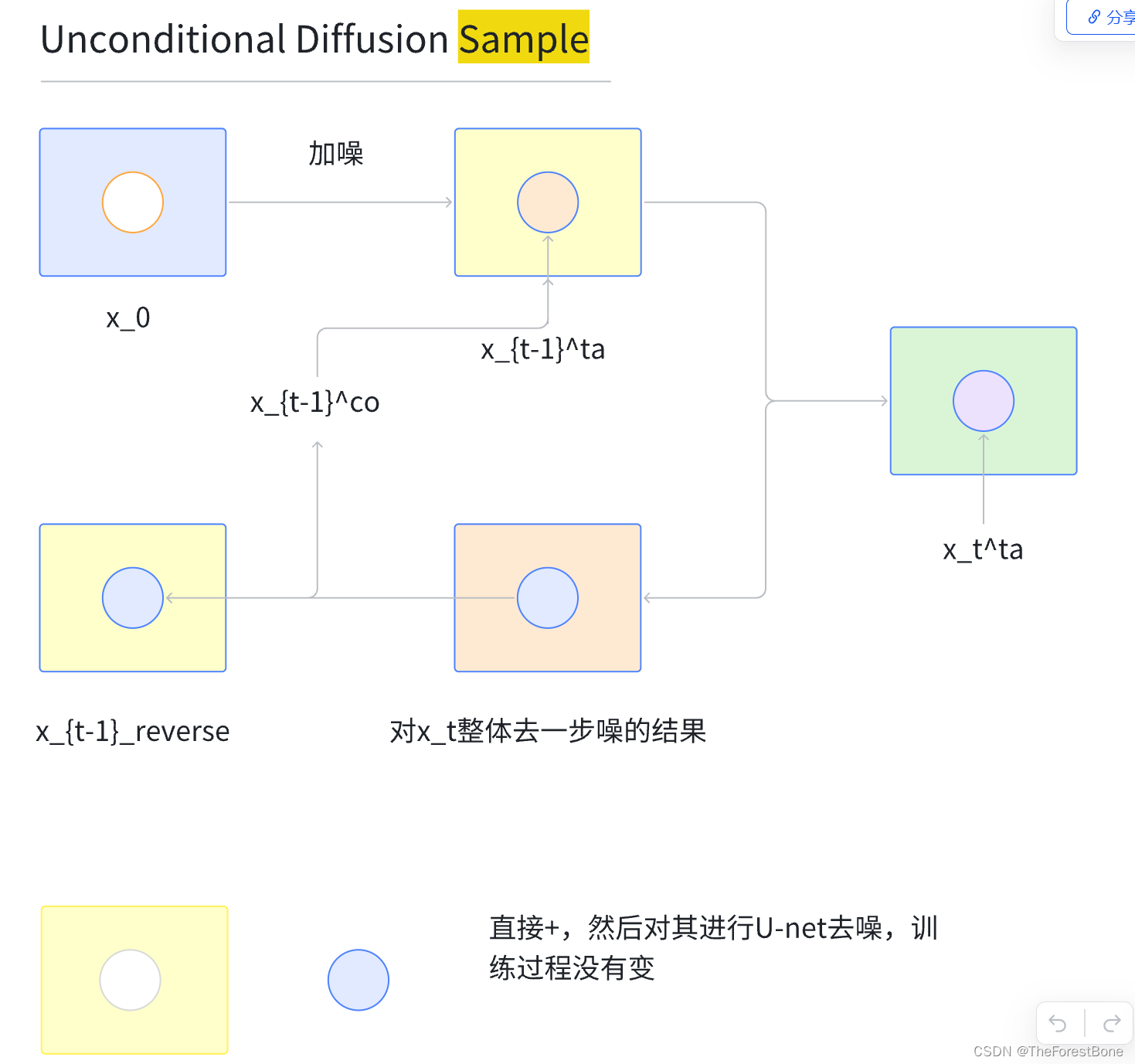
让我慢慢讲解,首先我们的目标是要插补出来中间白色空白的部分(为了方便理解,你可以认为那就是个图像,周围是练习室 x t c o x_{t}^{co} xtco表示condition,空白部分我们要填补出一个🏀篮球 x t t a x_{t}^{ta} xtta表示target)。
理所当然的,第一张图的蓝色部分就是我们的条件了,我们要根据这个条件去试图还原篮球,我们是怎么做的呢?其实还是跟原始DDPM一样,我们对整体图片进行加噪(是的,包括空白部分,在这里我们用随机噪声填补了空白)。
最后我们一直加到T步,它变成了一堆噪声。
重点就在我们的去噪过程,我们倒着来,从T步到T-1步,是对 x T x_T xT整体进行去噪的,然后我们单独把中间那一块 x T − 1 t a x_{T-1}^{ta} xT−1ta(target)拿出来。
然后呢,我们把这个核(下面的蓝色核)再和正向过程的T-1步的条件部分(黄色外壳)拼起来,作为下一步去噪的起始点。如此,我们就合理的用到了我们的条件。
这是Yang Song的原始DDPM提出的思想,但是这里还有个小问题❓就是:

- 划红线部分,我们的去噪过程中用到的条件 x t c o x_{t}^{co} xtco都是加了噪声之后的(因为我们是对整体加噪的嘛),所以会产生很多的信息损失,怎么办呢?
于是我们的CSDI就提出了一种新的架构(就是之前提到的图),可以不用加噪后的条件,直接用最原始的条件来还原我们的篮球🏀(坤坤狂喜)。
简洁版如下:
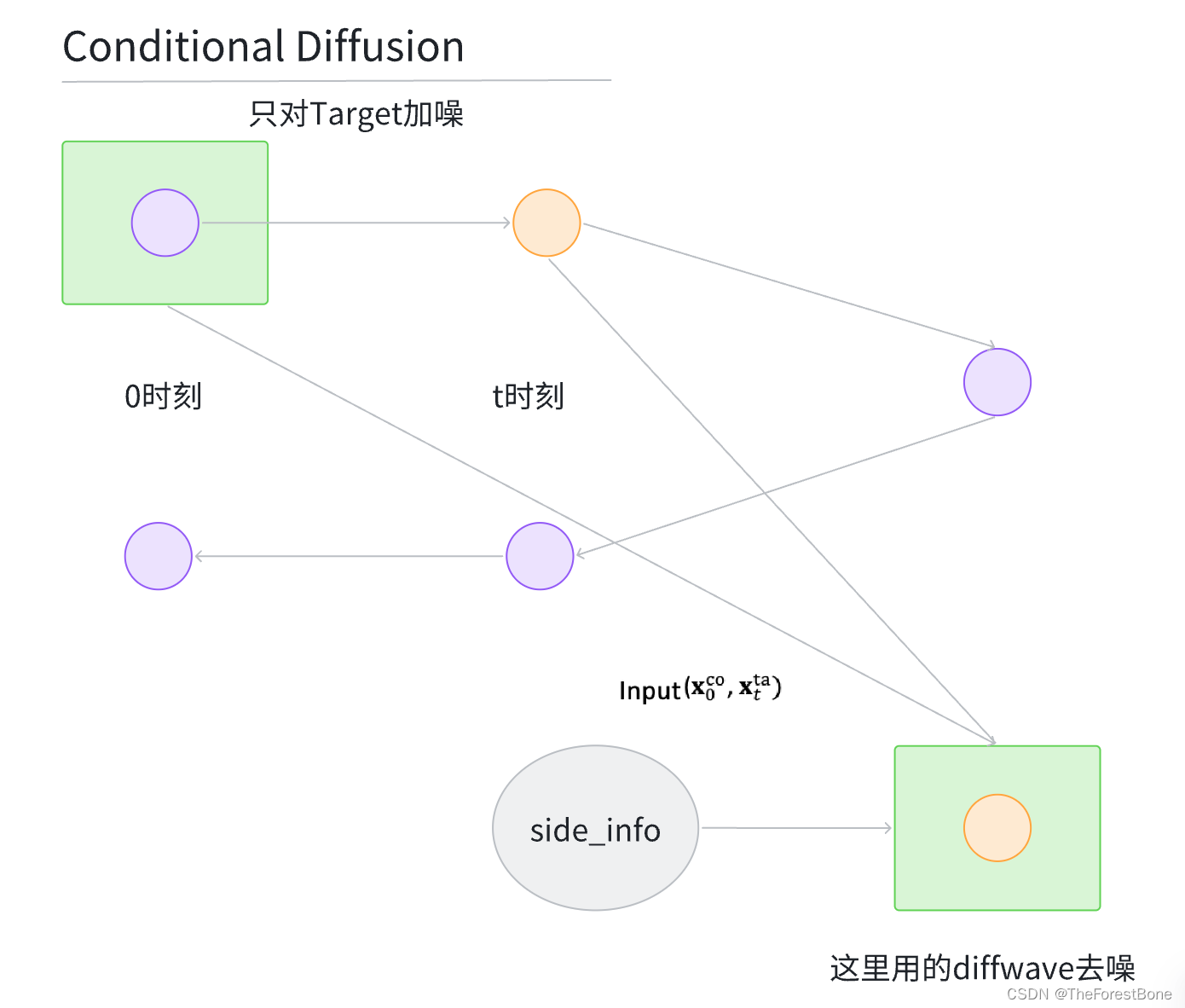
跟上面一对比你就可以清晰看出,相比于DDPM使用的U-net架构进行去噪,CSDI直接改用了diffwave架构,可以直接吸收我们的 x 0 c o x_0^{co} x0co作为输入从而进行去噪过程。
其中Diffwave架构由来已久,最早是用于处理音频数据的,这里CSDI拿来改了一下:
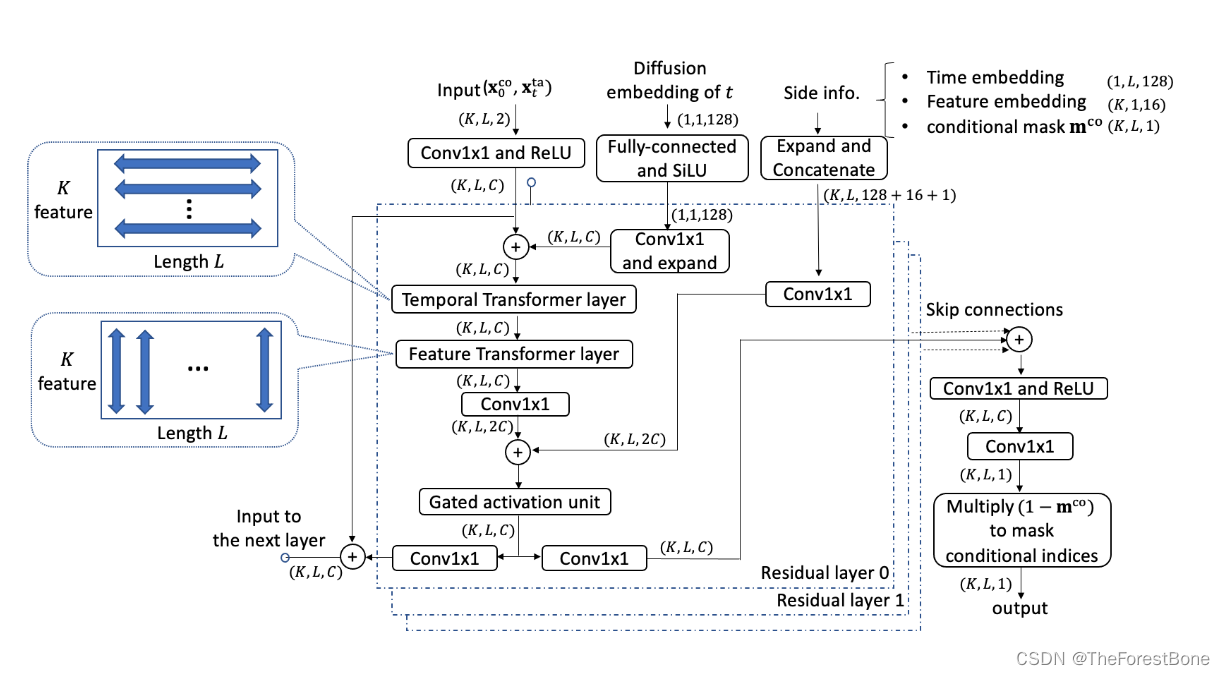
我们可以看到最上方input中,我们输入的是
x
0
c
o
x_0^{co}
x0co和
x
t
t
a
x_t^{ta}
xtta,这样就直接用了最原始的条件,其他两个分别是
- 时间嵌入矩阵(Diffusion embedding of t)
- 边缘信息(Side info)
到此为止,CSDI的基本架构和思路就差不多over了,原文附有很完整的代码实现,如果这期点赞收藏率高的话,我会把代码部分好好整理一下写出来。毕竟代码实现才是真正落地。
下课!😊


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









