




 本文深入探讨Flink/Blink的容错机制,包括检查点(checkpoint)的原理及实现过程,介绍了增量检查点(Incremental checkpoint)如何解决大规模流处理任务中的状态增长问题。
本文深入探讨Flink/Blink的容错机制,包括检查点(checkpoint)的原理及实现过程,介绍了增量检查点(Incremental checkpoint)如何解决大规模流处理任务中的状态增长问题。
系列文章目录
Flink/Blink 原理漫谈(一)时间,watermark详解
Flink/Blink 原理漫谈(二)流表对偶性和distinct详解
Flink/Blink 原理漫谈(三)state 有状态计算机制 详解
Flink/Blink 原理漫谈(五)流式计算的持续查询实现 详解
Flink/Blink 原理漫谈(六)容错机制(fault tolerance)详解
Flink 容错机制
Flink 检查点的核心作用是确保状态正确,即使遇到程序中断,也要正确。流计算Fault Tolerance的一个很大的挑战是低延迟,很多Blink任务都是7 x 24小时不间断,端到端的秒级延迟,要想在遇上网络闪断,机器坏掉等非预期的问题时候快速恢复正常,并且不影响计算结果正确性是一件极其困难的事情。在Blink中以checkpointing的机制进行容错,checkpointing会产生类似binlog一样的可以用来恢复的任务状态数据。花费的成本有低到高,如下:
• at-least-once
• exactly-once
检查点checkpoint
检查点像普通数据记录一样在算子之间流动。检查点分割线和普通数据记录类似。它们由算子处理,但并不参与计算,而是会触发与检查点相关的行为。
Checkpoint是故障修复机制的核心,是在某个时间点的一份拷贝。这个时间点是所有任务都恰好处理完一个相同的输入数据的时候。
从checkpoint恢复状态的步骤:
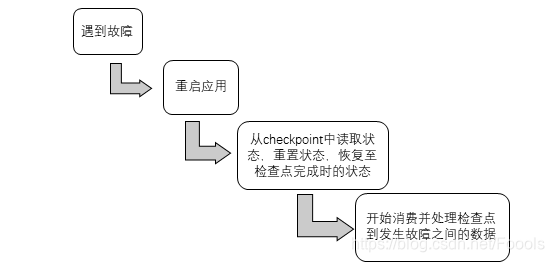
全局状态一致性的问题:
因为是流式计算,所以如何保证恢复的时候的全局一致性是一个棘手的问题。checkpoint使用的是分布式快照的方法,这种方法举例来说就是全学校的人需要拍一张毕业照,但是flink任务场景下,每个结点处理任务都是进度不同的,所以很难将全学校的人都在毕业的这一时刻叫到一起,拍一张照片;所以,我们就让学校中每一个同学各自拍一张自己毕业时候的照片,然后p图拼接在一起,这样就实现了在毕业的这一时刻得到一张全学校同学的毕业照。
Checkpoint的实现过程
Chekpoint用的就是这种分布式快照的方式,首先,JobManager向每个source任务发送一条带有检查点id的信息,启动检查点,source将他们的状态写入检查点,并发出一个检查点barrier,这个barrier信息就和正常的流式数据一样流动,当某个分区收到barrier信息之后,就会将当前状态保存到后端检查点中,接下来向后转发barrier,这个节点也急需处理数据,这个barrier被传递很多次之后,到达了最后的sink任务,sink也将状态保存,这时候所有的分区都已经将自己的状态发入检查点后端,一个checkpoint就完成了。
有些核心的点:
• barrier 由source节点发出;
• barrier会将流上event切分到不同的checkpoint中;
• barrier对齐之后会进行Checkpointing,生成snapshot;
• 完成snapshot之后向下游发出barrier,继续直到Sink节点;
这里引申出一个问题,这解决的是exactly-once还是at-least-once呢?这是分情况的,首先,为了满足exactly-once,我们使用的是BarrierBuffer,汇聚到当前节点的多流的barrier要对齐,Barrier提前到达,再有新的数据来,会被缓存;barrier尚未到达,数据被正常处理。如果是为了满足at-least-once,要使用的是BarrierTracker:BarrierTracker会对各个输入接收到的检查点的barrier进行跟踪。一旦它观察到某个检查点的所有barrier都已经到达,它将会通知监听器检查点已完成。
Incremental checkpoint
对于一个流计算的任务,数据会源源不断的流入,比如要进行双流join(Blink 漫谈系列 - Join 篇会详细介绍),由于两边的流event的到来有先后顺序问题,我们必须将left和right的数据都会在state中进行存储,Left event流入会在Right的State进行join数据,Right event流入会在LState中join数据。
由于流上数据源源不断,随着时间的增加,每次checkpoint产生的snapshot的文件(RocksDB的sst文件)会变的非常庞大,增加网络IO,拉长checkpoint时间,最终导无法完成checkpoint,Blink失去failover的能力。为了解决checkpoint不断变大的问题,Blink内部实现了Incremental checkpoint,这种增量进行checkpoint的机制,会大大减少checkpoint时间,并且如果业务数据稳定的情况下每次checkpoint的时间是相对稳定的,根据不同的业务需求设定checkpoint的interval,稳定快速的进行checkpointing,保障Blink任务在遇到故障时候可以顺利的进行failover。Incremental checkpoint的优化对于Blink成百上千的任务节点带来的利好不言而喻。
另外,为了实现端到端的一致性,我们仍然需要另外的一些机制,具体在state章节有详细的介绍。


















 1713
1713

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









