




 本文介绍如何使用Hadoop的MapReduce实现简单的词频统计应用,包括代码解析、打包及在集群上的运行步骤。
本文介绍如何使用Hadoop的MapReduce实现简单的词频统计应用,包括代码解析、打包及在集群上的运行步骤。
前言:
MapReduce作为hadoop中和HDFS YARN 三大组件之一
还是很有必要去掌握其中原理 并进行代码编写
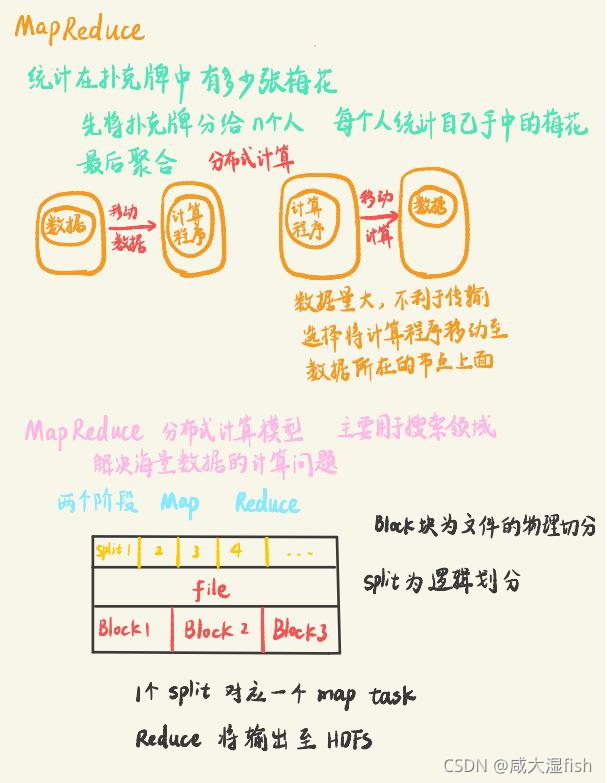


在这部分导包内容 是基于后续写代码的过程中 进行导入的(可跳过)
package com.xkh.mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* hdfs中的hello.txt
* 文件中内容
* hello you
* hello me
* hello word and you
* 最终形式
* hello 3
* you 2
* me 1
* word 1
* and 1
*/
先整体看代码
public class wordcount {
//<k1,v1> <k2,v2> k1为偏移量 k2 为文本
public static class MyMapper extends Mapper<LongWritable,Text,Text,LongWritable>{
@Override
protected void map(LongWritable k1, Text v1, Ma 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 496
496

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









