MapReduce 思想
MapReduce 最大的亮点在于通过抽象模型和计算框架把需要做什么(what
. MapReduce 框架结构
MapReduce 编程规范及示例编写
定义一个 mapper
//首先要定义四个泛型的类型
//keyin: LongWritable valuein: Text
//keyout: Text valueout:IntWritable
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
//map 方法的生命周期: 框架每传一行数据就被调用一次
//key : 这一行的起始点在文件中的偏移量
//value: 这一行的内容
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException
{
//拿到一行数据转换为 string
String line = value.toString();
北京市昌平区建材城西路金燕龙办公楼一层 电话:400-618-9090
//将这一行切分出各个单词
String[] words = line.split(" ");
//遍历数组,输出<单词,1>
for(String word:words){
context.write(new Text(word), new IntWritable(1));
}
}
}
定义一个 reducer
//生命周期:框架每传递进来一个 kv 组,reduce 方法被调用一次
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException,
InterruptedException {
//定义一个计数器
int count = 0;
//遍历这一组 kv 的所有 v,累加到 count 中
for(IntWritable value:values){
count += value.get();
}
context.write(key, new IntWritable(count));
}
}
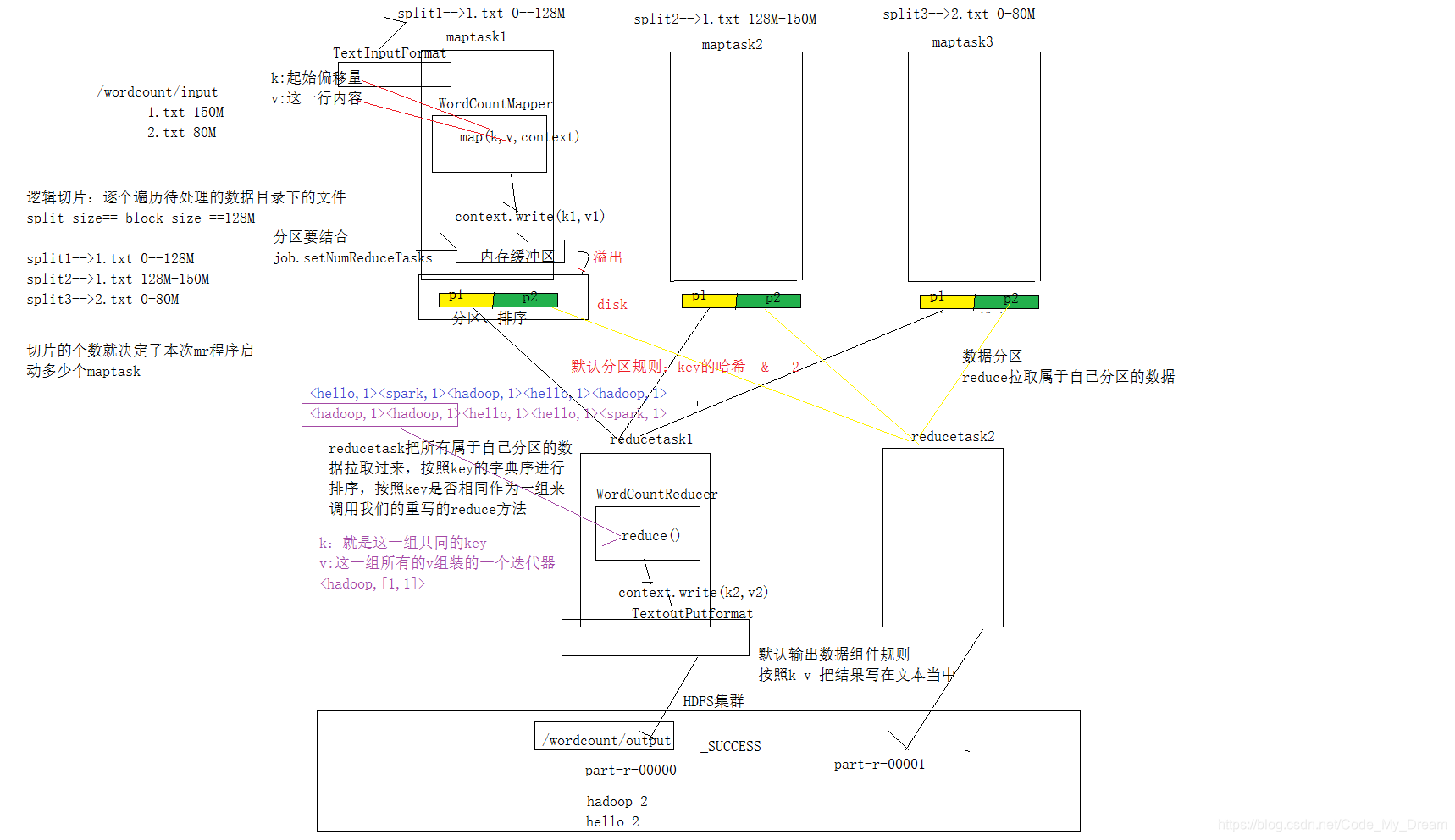
Mapper 任务 任务 执行过程详解
第一阶段是把输入目录下文件按照一定的标准逐个进行逻辑切片,形成切
第二阶段是对切片中的数据按照一定的规则解析成<key,value>对。默认规
第三阶段是调用 Mapper 类中的 map 方法。上阶段中每解析出来的一个
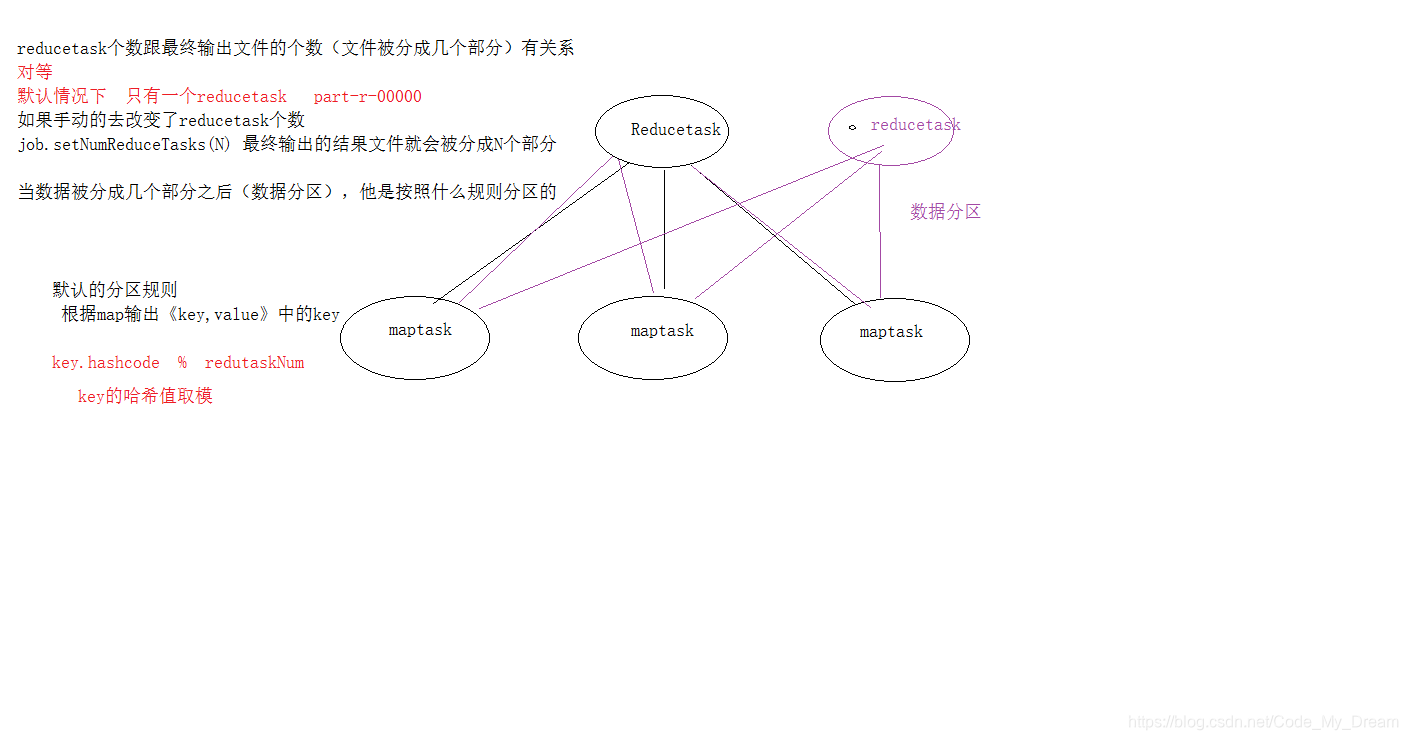
第四阶段是按照一定的规则对第三阶段输出的键值对进行分区。默认是只
第五阶段是对每个分区中的键值对进行排序。首先,按照键进行排序,对
第六阶段是对数据进行局部聚合处理,也就是 combiner 处理。键相等的键
Reducer 任务 任务 执行过程详解





 MapReduce是一种分布式计算框架,核心理念是“分而治之”。它将复杂任务拆分为Map和Reduce两个阶段,Map负责数据的拆分与处理,Reduce则负责结果的汇总。程序员只需关注应用逻辑,而系统会处理并行计算的细节。MapReduce程序包含Mapper、Reducer和Driver三个部分,分别处理数据映射、数据聚合以及任务提交。执行过程中涉及MapTask和ReduceTask,分别处理map阶段和reduce阶段的数据处理流程。
MapReduce是一种分布式计算框架,核心理念是“分而治之”。它将复杂任务拆分为Map和Reduce两个阶段,Map负责数据的拆分与处理,Reduce则负责结果的汇总。程序员只需关注应用逻辑,而系统会处理并行计算的细节。MapReduce程序包含Mapper、Reducer和Driver三个部分,分别处理数据映射、数据聚合以及任务提交。执行过程中涉及MapTask和ReduceTask,分别处理map阶段和reduce阶段的数据处理流程。

















 374
374

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









