




 本文深入探讨Hive中的内部表、外部表、分区表及分桶表的概念与操作,解析不同类型的表在HDFS存储上的特性,以及如何通过分区和分桶优化查询效率。
本文深入探讨Hive中的内部表、外部表、分区表及分桶表的概念与操作,解析不同类型的表在HDFS存储上的特性,以及如何通过分区和分桶优化查询效率。
一、内部表和外部表
- 概念
- 内部表:在Hive中手动添加数据的表
- 外部表:HDFS中已经存在的数据被hive 中的表来管理;
如何建立外部表?
create external table score(name string ,chinese int …) row format delimited fields terminated by ‘,’ location ‘/score’;(Hdfs的相对路径)
删除操作
- 对于内部表删除的话会将HDFS上对应的目录删除
- 外部表不会删除Hdfs存储的目录
二、分区表
- 实际上可以认为对数据的分类
- 用来分区的字段的值在原始数据不存在,分区的字段值是手动添加的(
 );
); - 添加成功会在HDFS中西添加一个目录结构
- (
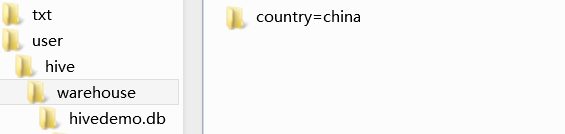
并且添加这么一个文件
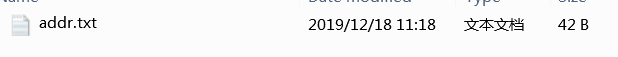 )
) - **msck repair table addrs :**命令主要是用来解决通过hdfs dfs -put或者hdfs api写入hive分区表的数据在hive中无法被查询到的问题。hive会去检测这个表在hdfs上的文件,把没有写入metastore的分区信息写入metastore。
- 指定的分区字段要与创建表时的分区字段一致否则报错(
 );
); - 添加分区的造作


-
向分区中插入几条数据,在原表的基础之上进行修改(效率低 ----一条数据10多秒)
 可以添加limit 限制添加的条数,否则满足条件的全部插入;
可以添加limit 限制添加的条数,否则满足条件的全部插入;
双字段分区 - 会多一级目录
- 会多一级目录
- 动态添加分区
- set hive.exec.dynamic.partition.mode=nonstrict; 设置非严格分区

- insert into table city partition(country) select id, name, country from tmp distribute by country; //指明按照那个字段进行动态分区添加;
- 分区的意义:
- 将表内的数据进一步进行细分
- 可以减少数据的冗余
- 提高指定分区的查询分析效率;也意味着跨区查处效率反而减低;
分桶表
- 分桶是将数据集分解成为更容易管理的若干部分的另一种技术;
- 分桶原理是按照分桶字段的hash值去除以分桶的个数;(与MapReduce中地HashPartitioner计算RT相似)
- 用于进行数据的抽样的;
- 基本操作:
- create table person (id int ,name string ,age int )clustered by(name) into 4 buckets row format delimiterd fields terminated by ’ ’ ; 不同与分区分桶中的字段在原始表中是存在的;
- 分桶表只有从另一个表中查询数据向分桶表中放的时候才会分桶;Why? 插入的数据需要一次hash,直接导入没有进行MapReduce过程 也就没有进行Hash计算;
- 开启分桶机制 set hive.enforce.bucketing = true;
- 将数据导入临时表
- 再将临时表中查询数据直接插入原表;
- 最后查询一下吧;select * from person tablesample(buckets x out of y name)
- x–抽样的起始桶的编号
- y–可以理解为步长,注意 y必须是桶的因子(整数倍);抽样的个数是桶数/y


很nice的一条帖子:
https://blog.youkuaiyun.com/u010003835/article/details/80911215

















 3781
3781

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









