




RDD介绍
因为RDD的实现原理和IO的实现原理差不多,我们先来说一下IO的实现原理:
其实真正进行读取数据的还是FileInputStream
IO实现原理图解:

RDD的工作流程:
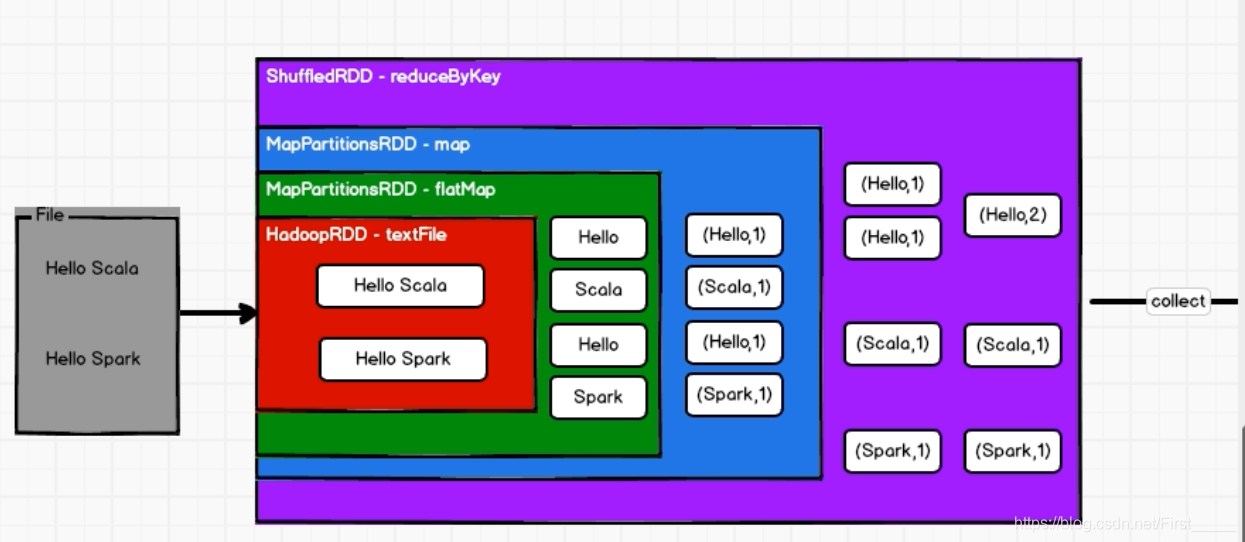
- RDD不会存储数据,但是可以存储依赖关系和血缘关系;
- RDD也有装饰者模式;
- RDD只有调用collect方法,才会真正执行业务逻辑代码,封装操作都是对RDD的功能扩展
分区和并行度:
概念:
分区 & 并行的概念: 分区和并行度是可以不一样的, 当有2个分区和1个executor的时候,就还不是并行,只能并发执行
并行度执行解析:
对数据进行分区, 然后每个分区内必须一个一个执行,多个分区可以并行执行,做到执行区内有序,区外无序
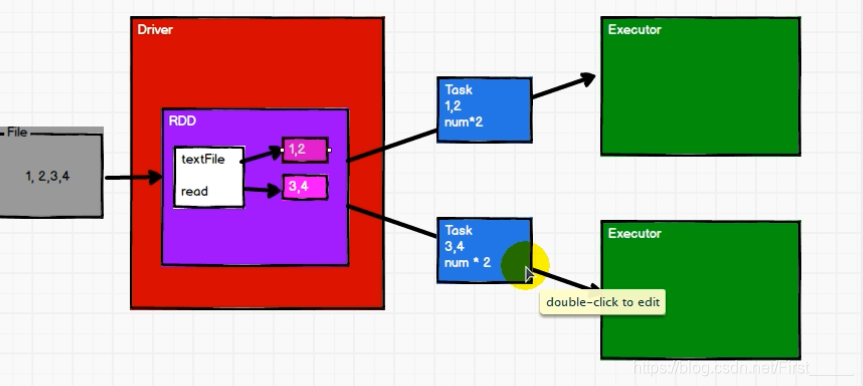
例: 对数据 List(1,2,3,4), 两个分区
计算流程:
- 先进行分配,
0号分区 => 1 ,2
1号分区 => 3,4 - 如果再执行两次map的话, 就会先将每个分区的第一个数据的全部计算完成之后,才会进行执行第二个, 做到区内数据执行有序
RDD的特点:
介绍:RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据处理模型。
➢ 弹性
⚫ 存储的弹性:内存与磁盘的自动切换(效率高);
⚫ 容错的弹性:数据丢失可以自动恢复;
⚫ 计算的弹性:计算出错重试机制;
⚫ 分片的弹性:可根据需要重新分片(其实就是分区)。
➢ 分布式:数据存储在大数据集群不同节点上
➢ 数据集:RDD 封装了计算逻辑,并不保存数据(数据计算完成之后,就进行销毁了)
➢ 数据抽象:RDD 是一个抽象类,需要子类具体实现
➢ 不可变:RDD 封装了计算逻辑,是不可以改变的,想要改变,只能产生新的 RDD,在新的 RDD 里面封装计算逻辑
➢ 可分区、并行计算
算子介绍:
- 对象所执行的方法,都是在一个节点中执行的
- RDD的方法内部计算逻辑代码,都是发送到executor上来执行的
- 为了区分不同的效果,将RDD的方法称为算子
RDD依赖(血缘)关系介绍:
概念介绍:
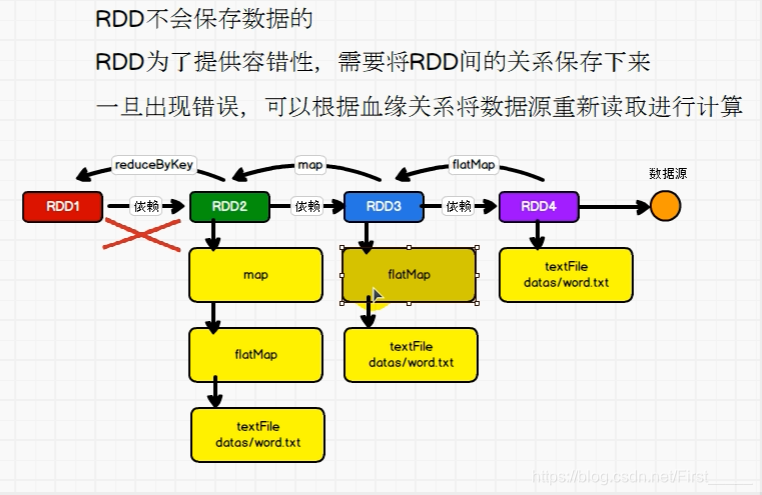
- 血缘关系: 就是我们的RDD的整个之间的依赖关系,就叫血缘关系,而maven中叫间接依赖
- 一个上游的RDD的partition最多只被一个下游的partition使用,叫做OneToOne(窄依赖)
- 一个上游的RDD的partition被多个下游的partition使用,叫做shuffle(宽依赖)
toDebugString(): 获取RDD的血缘关系dependencies():获取依赖关系
任务和阶段的划分:
- 阶段的划分(stage): 每进行一次shuffle都要增加一个阶段,最后还有创建一个resultStage阶段,所以,
阶段的数量= shuffle的次数+1 - 任务的划分(task):
任务的数量=每个stage最后的分区数量
数据重复使用
-
原因: 因为RDD不能存储数据,所以不能进行重复使用
-
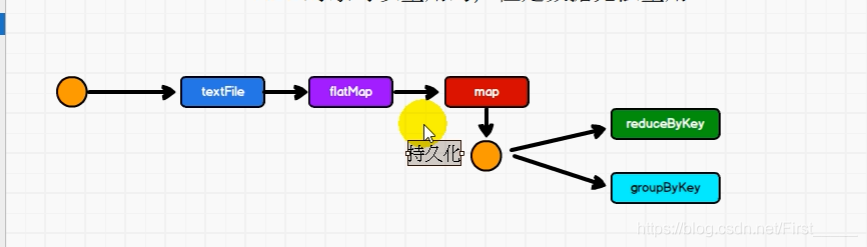
如果要想达到重复使用的目的,就在想到重复使用的RDD地方,进行数据持久化(内存中,磁盘上)
-
不一定非要重复时,才进行持久化, 如果进行了持久化,当数据发生错误时,就不会进行从头读取,浪费时间资源,提高效率
-
保存到磁盘的时候,是临时文件,当程序执行完是会删除的, 所以并不需要填写路径
-
也可以使用检查点checkpoint的方式,进行保存数据到磁盘
图解:
具体操作:
- 调用
cache()或者persist()方法进行持久化 cache()方法默认是保存到内存中, 如果要更改保存级别, 可以使用 persist()方法,进行更改checkpoint()检查点,是需要填写路径的(默认当前路径),保存到磁盘当中,当程序执行完,不会进行删除,一般情况下,保存到分布式文件系统当中(hdfs)
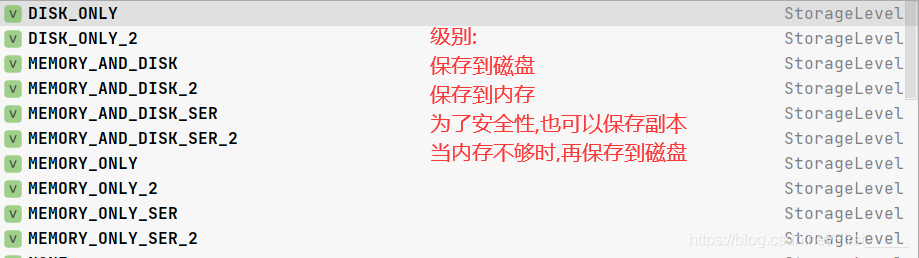
三者的效率对比:

分区源码实现
def main(args: Array[String]): Unit = {
//准备环境
val conf = new SparkConf().setAppName("RDD_Partition").setMaster("local[*]")
conf.set("spark.default.parallelism","3")
val sc = new SparkContext(conf)
/**
*
*/
//指定并行度 : 第一个参数:数据 第二个参数: 分区的数量, 默认为当前运行环境的机器的最大核数,也可以通过下面配置参数进行配置
// defaultParallelism: scheduler.conf.getInt("spark.default.parallelism", totalCores) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3067
3067

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









