




方法
目标是解决单域泛化问题:模型仅在一个源域SSS中训练,但要求在许多未见过的目标域TTT上泛化良好。受到许多最近成就的启发[36,56,24],这个具有挑战性的问题的一个有希望的解决方案是利用对抗训练[11,49]。关键思想是学习一个抗分布外扰动的鲁棒模型。更具体地说,我们可以通过解决最坏情况问题来学习模型[44]:
minθsupT:D(S,T)≤ρE[Ltask(θ;T)],(1) \min_{\theta}\sup_{\mathcal{T}:D(\mathcal{S},\mathcal{T})\leq\rho}\mathbb{E}[\mathcal{L}_{\mathrm{task}}(\theta;\mathcal{T})], (1) θminT:D(S,T)≤ρsupE[Ltask(θ;T)],(1)其中DDD是测量域距离的相似性度量,ρρρ表示SSS和TTT之间的最大域差异。θ是根据任务特定目标函数LtaskL_{task}Ltask优化的模型参数。理解:(minθ\min_{\theta}minθ) 表示我们要最小化的是关于参数 (θ\thetaθ) 的某个函数。(supT:D(S,T)≤ρ\sup_{\mathcal{T}:D(\mathcal{S},\mathcal{T})\leq\rho}supT:D(S,T)≤ρ) 表示在所有满足某个条件的训练集 (T\mathcal{T}T) 上取最大值。这里的(D(S,T)D(\mathcal{S},\mathcal{T})D(S,T)) 表示两个数据分布之间的距离,而 (ρ\rhoρ) 是一个给定的阈值。(E[Ltask(θ;T)]\mathbb{E}[\mathcal{L}_{\mathrm{task}}(\theta;\mathcal{T})]E[Ltask(θ;T)]) 表示在训练集 (T\mathcal{T}T) 上关于参数 (θ\thetaθ) 的某个损失函数的期望值。总的来说这个公式的意义是:要找到能够最小化在所有满足某种数据分布距离约束条件下的训练集上的某个损失函数的期望值的参数 (θ\thetaθ)。这种形式的优化问题在对抗性训练或者用于泛化保证时可能会经常出现。在这里,我们关注使用交叉熵损失的分类问题:
Ltask(y,y^)=−∑iyilog(y^i),(2) \mathcal{L}_{\mathrm{task}}(\mathbf{y},\hat{\mathbf{y}})=-\sum_{i}y_{i}\log(\hat{y}_{i}), (2) Ltask(y,y^)=−i∑yilog(y^i),(2)其中y^\mathbf{\hat{y}}y^为模型的softmax输出;y\mathbf{y}y是表示真类的one-hot向量;yiy_iyi和y^i\hat{y}_iy^i分别表示yyy和y^\hat{y}y^的第iii维。
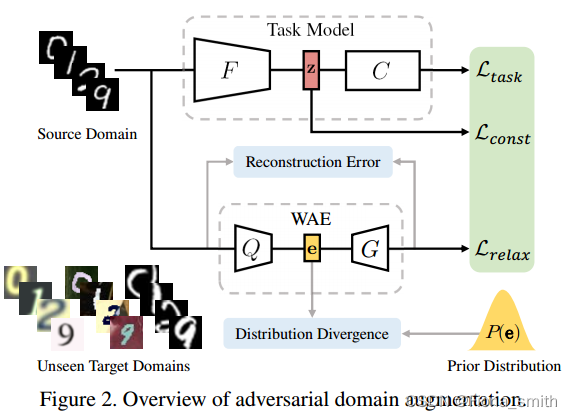
根据最坏情况公式(1),我们提出了一种新的方法,基于元学习的对抗域增强(M-ADA),用于单域泛化。图2概述了我们的方法。在第3.1节中,我们通过利用对抗性训练来增强源域,创建了“虚构”但“具有挑战性”的域。在Wasserstein自动编码器(WAE)的帮助下,任务模型从域增强中学习,这放宽了第3.2节中的最坏情况约束。我们在如3.3节所述的学会学习的框架下组织任务模型和WAE的联合训练,以及领域增强过程。最后,在第四节给出了最坏情况保证的理论证明。
对抗性域增强
我们的目标是从源域创建读个增强域。增强域要求与源域在分布上不同,以模拟不可见的域。此外,为避免增强域发散,还应满足式(1)中定义的最坏情况保证。为了实现这一目标,我们提出了对抗性域增强。
为了实现这一目标,我们提出了对抗性域增强。我们的模型由任务模型和WAE组成,如图2所示。在图2中,任务模型由特征提取器F:X→ZF: X →ZF:X→Z映射图像从输入空间到嵌入空间,和一个分类器C:Z→YC: Z →YC:Z→Y用于从嵌入空间预测标签。设zzz表示由z=F(x)z = F(x)z=F(x)得到的xxx的潜在表示。总体损失函数的表达式为:
LADA=Ltask(θ;x)⏟Classification−αLconst(θ;z)⏟Constraint+βLrelax(ψ;x)⏟Relaxation,(3) \mathcal{L}_{\mathrm{ADA}}=\underbrace{\mathcal{L}_{\mathrm{task}}(\theta;\mathbf{x})}_{\text{Classification}}-\alpha\underbrace{\mathcal{L}_{\mathrm{const}}(\theta;\mathbf{z})}_{\text{Constraint}}+\beta\underbrace{\mathcal{L}_{\mathrm{relax}}(\psi;\mathbf{x})}_{\text{Relaxation}}, (3) LADA=Classification
Ltask(θ;x)−αConstraint
Lconst(θ;z)+βRelaxation
L
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1728
1728




 到【灌水乐园】发言
到【灌水乐园】发言







