



 本文详细指导如何在Windows上通过XFTP传输JDK和Hadoop压缩包,然后在Linux中解压、配置环境变量,确保Java和Hadoop成功安装。
本文详细指导如何在Windows上通过XFTP传输JDK和Hadoop压缩包,然后在Linux中解压、配置环境变量,确保Java和Hadoop成功安装。
一.在windows系统下载好xftp,jdk和hadoop
链接:https://pan.baidu.com/s/1bta9huc7d3mKDjOs1zbtNA
提取码:1kse

二.在windows系统安装xftp
在windows系统双击exe文件傻瓜式安装即可
xftp是windows系统往linux系统传输文件用的软件,使用xftp将jdk和hadoop压缩包从window系统传输到linux系统

linux主机ip可以在linux的终端里面使用进行查询
ifconfig -a

找到主机号填进去,就可以进行文件拖拽传输了,如下:
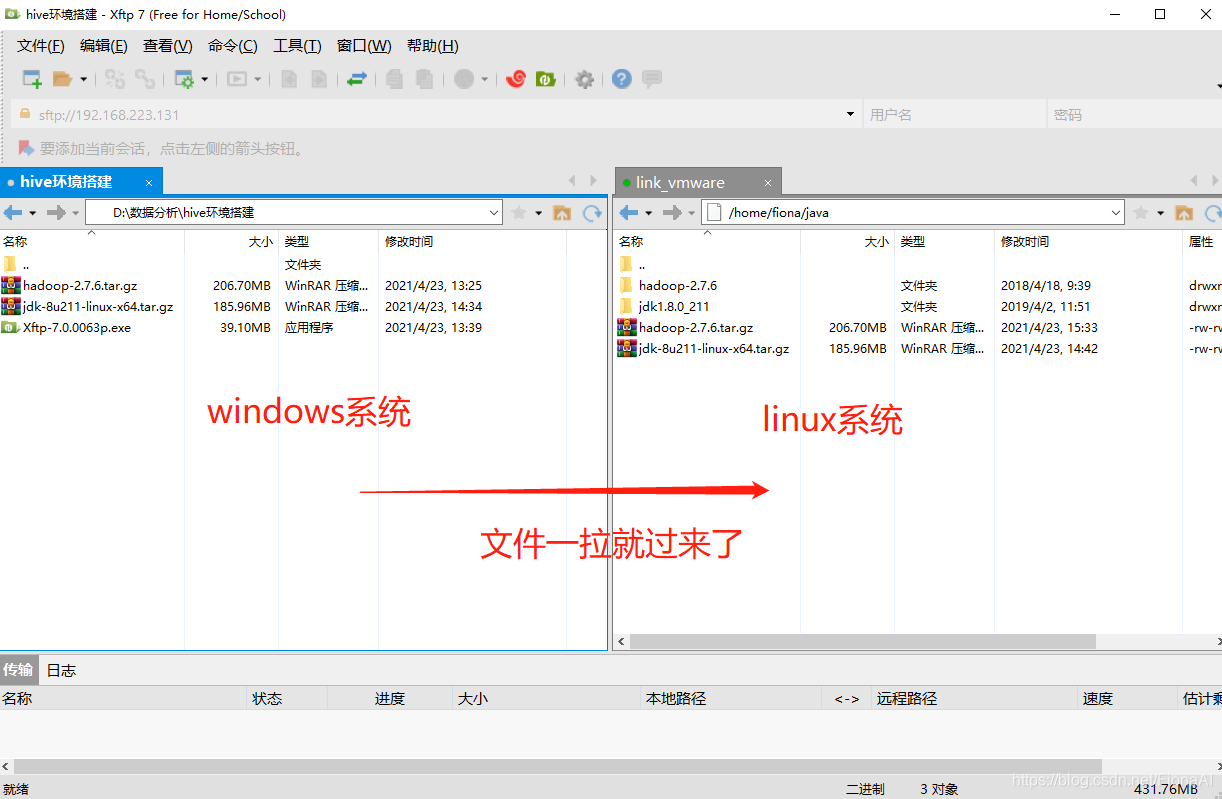
(以下全都在linux系统进行)
三.在linux系统安装jdk
1.解压文件:tar -zxvf +需要解压的包名
fiona@ubuntu:~/java$ tar -zxvf jdk-8u211-linux-x64.tar.gz
2.文件配置
fiona@ubuntu:~/java/jdk1.8.0_211$ sudo gedit /etc/profile
输入密码,弹出profile,在profile最后面插入
export JAVA_HOME=/home/fiona/java/jdk1.8.0_211 (注意:你的路径可能和我的不一样)
export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH

注意:你的路径可能和我的不一样
查询你的jdk1.8.0_211文件路径的方法:
点击jdk1.8.0_211文件,右键,属性。
如下就可以看到

保存profile文件,
之后再输入source /etc/profile,重启一下配置文件
fiona@ubuntu:~/java/jdk1.8.0_211$ source /etc/profile
3.查询是否配置成功,在终端
java -version
出来结果:
fiona@ubuntu:~/java/jdk1.8.0_211$ java -version
java version "1.8.0_211"
Java(TM) SE Runtime Environment (build 1.8.0_211-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.211-b12, mixed mode)
即代表安装jdk成功,也可以在终端输入java、javac查询是否成功
四.在linux系统安装hadoop
1.解压文件:tar -zxvf +需要解压的包名
fiona@ubuntu:~/java$ tar -zxvf hadoop-2.7.6.tar.gz
2.文件配置
fiona@ubuntu:~/java/hadoop-2.7.6$ sudo gedit /etc/profile

输入密码,弹出profile,在profile最后面插入
export HADOOP_HOME=/home/fiona/java/hadoop-2.7.6(注意:你的路径可能和我的不一样)
export PATH=$PATH:${HADOOP_HOME}/bin
export PATH=$PATH:${HADOOP_HOME}/sbin
重启一下配置文件:
fiona@ubuntu:~/java/hadoop-2.7.6$ source /etc/profile
3.查询是否配置成功,在终端输入
fiona@ubuntu:~/java$ hadoop version
出来结果:
Hadoop 2.7.6
Subversion https://shv@git-wip-us.apache.org/repos/asf/hadoop.git -r 085099c66cf28be31604560c376fa282e69282b8
Compiled by kshvachk on 2018-04-18T01:33Z
Compiled with protoc 2.5.0
From source with checksum 71e2695531cb3360ab74598755d036
This command was run using /home/fiona/java/hadoop-2.7.6/share/hadoop/common/hadoop-common-2.7.6.jar
fiona@ubuntu:~/java$
到此,已经在linuxwan安装jdk和hadoop完成。
觉得有用的,点个赞再走呀~
欢迎转载收藏~

















 562
562

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









