




 本文详细介绍了seq2seq模型的工作原理,包括Encoder和Decoder的职责,以及在长序列处理上的局限性。随后,文章阐述了Attention机制的引入原因、作用和流程,强调了其在处理输入序列差异化的重要性。Attention机制在多个领域的广泛应用,如自然语言处理和图像识别,以及其不同变体如Soft、Hard、Global和Local Attention的解释,使得模型能够更加聚焦于关键信息。
本文详细介绍了seq2seq模型的工作原理,包括Encoder和Decoder的职责,以及在长序列处理上的局限性。随后,文章阐述了Attention机制的引入原因、作用和流程,强调了其在处理输入序列差异化的重要性。Attention机制在多个领域的广泛应用,如自然语言处理和图像识别,以及其不同变体如Soft、Hard、Global和Local Attention的解释,使得模型能够更加聚焦于关键信息。
【面筋】关于Attention
一、seq2seq 篇
1.1 seq2seq (Encoder-Decoder)是什么?
- 介绍:seq2seq (Encoder-Decoder)将一个句子(图片)利用一个 Encoder 编码为一个 context,然后在利用一个 Decoder 将 context 解码为 另一个句子(图片)的过程 ;
- 应用:
- 在 Image Caption 的应用中 Encoder-Decoder 就是 CNN-RNN 的编码 - 解码框架;
- 在神经网络机器翻译中 Encoder-Decoder 往往就是 LSTM-LSTM 的编码 - 解码框架,在机器翻译中也被叫做 Sequence to Sequence learning。
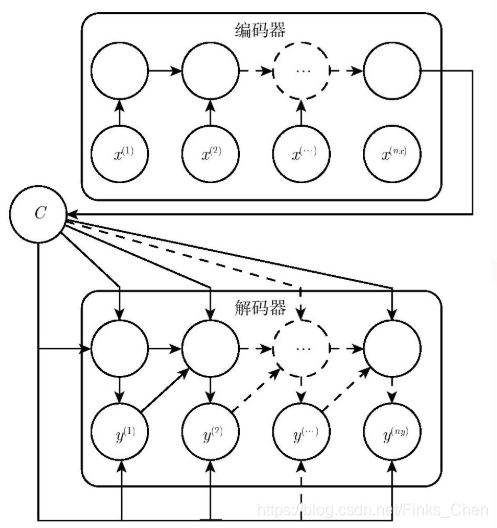
1.2 seq2seq 中 的 Encoder 怎么样?
- 目标:将 input 编码成一个固定长度 语义编码 context
- context 作用:
- 1、做为初始向量初始化 Decoder 的模型,做为 decoder 模型预测y1的初始向量;
- 2、做为背景向量,指导y序列中每一个step的y的产出;
- 步骤:
-
- 遍历输入的每一个Token(词),每个时刻的输入是上一个时刻的隐状态和输入
-
- 会有一个输出和新的隐状态。这个新的隐状态会作为下一个时刻的输入隐状态。每个时刻都有一个输出;
-
- 保留最后一个时刻的隐状态,认为它编码了整个句子的 语义编码 context,并把最后一个时刻的隐状态作为Decoder的初始隐状态;
-
1.3 seq2seq 中 的 Decoder 怎么样?
- 目标:将 语义编码 context 解码 为 一个 新的 output;
- 步骤:
-
- 一开始的隐状态是Encoder最后时刻的隐状态,输入是特殊的;
-
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 307
307

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









