




 本文讨论了中文NER与英文的区别,指出中文ner基于字的缺点及词汇增强的改进策略,包括自适应embedding和格子LSTM。词汇增强通过引入词汇信息提升模型识别效果。介绍了实体识别的三种主要方法:基于规则和字典、统计模型如HMM和CRF,以及基于深度学习的BiLSTM-CRF等。此外,还详细探讨了嵌套实体识别及其解决方案,包括多标签任务、修改标注方式和使用seq2seq模型。
本文讨论了中文NER与英文的区别,指出中文ner基于字的缺点及词汇增强的改进策略,包括自适应embedding和格子LSTM。词汇增强通过引入词汇信息提升模型识别效果。介绍了实体识别的三种主要方法:基于规则和字典、统计模型如HMM和CRF,以及基于深度学习的BiLSTM-CRF等。此外,还详细探讨了嵌套实体识别及其解决方案,包括多标签任务、修改标注方式和使用seq2seq模型。
【面筋】关于实体识别
文章目录
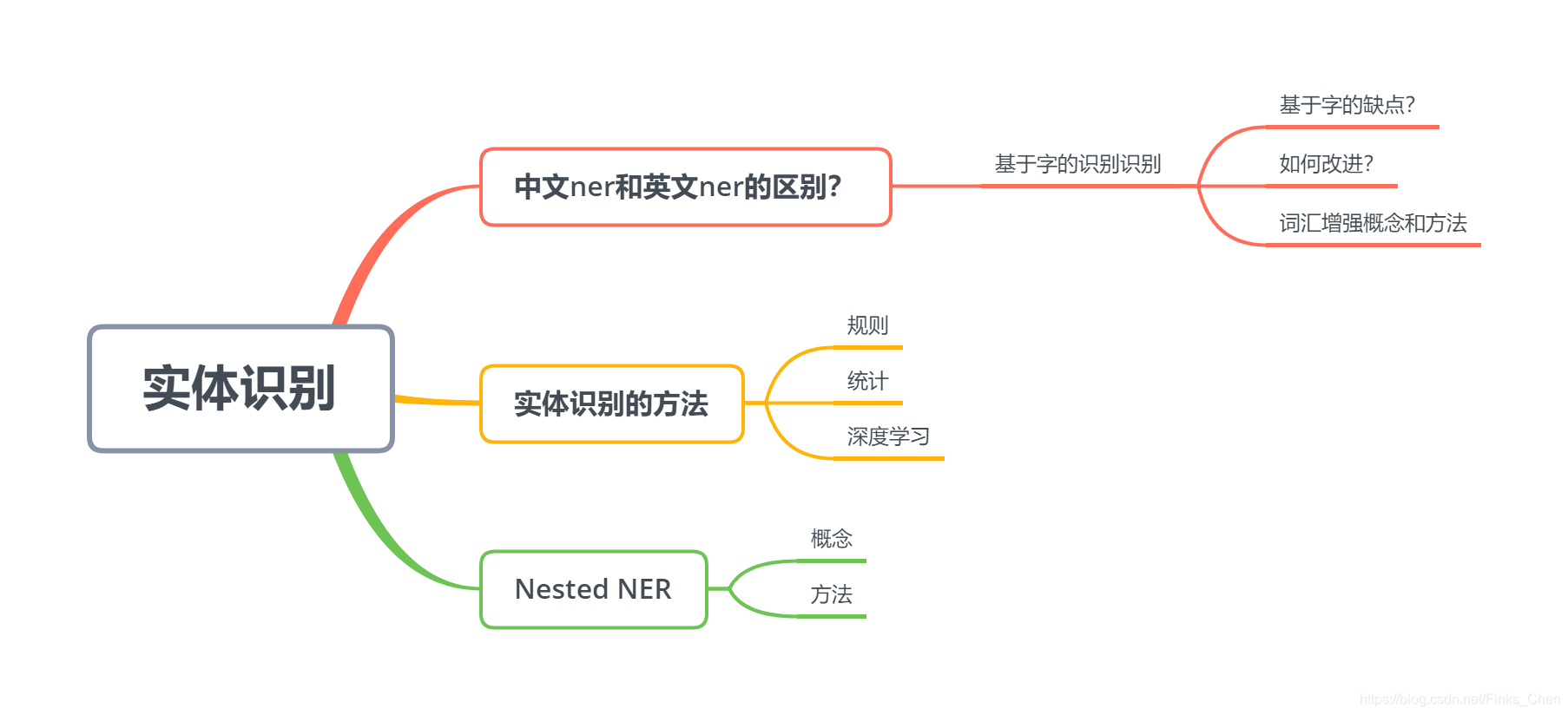
1)中文ner和英文ner的区别?
分词方式不同,英文使用空格可以准确分词,但中文分词有别去其他语言的分词方式,更复杂。分词的准确性对实体识别有影响,因此中文通常基于字;
2)中文基于字的实体识别有什么缺点?怎么改进?
中文ner通常视作一个序列标注任务,基于字的识别是必要条件,能够避免分词误差导致的错误;但是没有利用到词的边界信息;
改进方法则可以做词汇增强;
词汇增强:输入序列依旧是基于字的序列,但是可以在序列上引入分词后的信息做信息融合,关于这部分工作有很多的研究,
比如说:
1)自适应embedding,基于词汇信息,构建自适应Embedding;
2)设计一个动态框架,能够兼容词汇输入;如:Lattice LSTM(格子LSTM);
可参考,我这里说一个简单容易实现的方法,单独的预训练词向量,对序列分词后将其与字序列对其,拼接到字向量后面,完成融合;
3)什么是词汇增强?
引入词汇信息(词汇增强)来增强 模型 识别 句子中实体的方法;该实体识别任务还是基于字的序列标注,词汇信息只是增强作用;
4)为什么词汇增强对中文ner有效?
1)引入词汇的边界信息,边界信息对于文本语义有重要作用;
2)词汇增强可以看做一种特征增强的手段,专业领域的分词效果可以作为一种指导信息;</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 327
327

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









