



【笔记】关键词提取算法
参考:https://zhuanlan.zhihu.com/p/126733456
重点是基于图的算法;
TF-IDF和TextRank是自然语言处理当中比比较经典的关键词提取算法;
1)TF-IDF
1. 概念
TF-IDF(Term Frequency - Inverse Document Frequency)
TF(词频)表示词(关键字)在文档中出现的频率。公式为:
T
F
w
=
文档中词w出现的次数
文档中词条总数目
TF_w = \frac{\text{文档中词w出现的次数}}{\text{文档中词条总数目}}
TFw=文档中词条总数目文档中词w出现的次数
IDF(逆文档频率)反映词的普遍程度;当一个词很普遍,即有大量的文档中都包含这个词,其IDF值越低;IDF值计算定义如下:
I
D
F
w
=
l
o
g
(
语料库的文档总数
包含词条w的文档数 + 1
)
IDF_w= log(\frac{\text{语料库的文档总数}}{\text{包含词条w的文档数 + 1}})
IDFw=log(包含词条w的文档数 + 1语料库的文档总数)
可见TF和IDF两者的计算对象不同,TF是当前文档中进行词频统计,IDF是文档在语料库中进行文档频率统计;前者反映当前文档中词的分布概率,属于局部采样,后者是词的全局概率;
TF-IDF的计算实际的是两部分概率相乘;
T
F
−
I
D
F
=
T
F
∗
I
D
F
TF-IDF = TF * IDF
TF−IDF=TF∗IDF
从上述定义可以看出:
- 当一个词在文档频率越高并且新鲜度高(即普遍度低),其TF-IDF值越高。
- TF-IDF兼顾词频与新鲜度,过滤一些常见词,保留能提供更多信息的重要词。
优点:
- 实现起来很简单,能够适应大多数状况,应用广泛;
缺点:
- 结构简单而没有考虑语义信息,无法处理一词多义现象;
2. Python中实现
NLTK中的实现
from nltk.text import TextCollection
# 构建语料库corpus
docs = ['this is sentence one', 'this is sentence two', 'this is sentence three']
# 对每一个句子进行分词
tokens = [doc.split(' ') for doc in docs]
print(tokens)
corpus = TextCollection(tokens) # 构建语料库
print(corpus)
# 计算语料库中"one"的tf值
tf = corpus.tf('one', corpus) # 1/12
print('TF:',tf)
# 计算语料库中"one"的idf值
idf = corpus.idf('one') # log(3/1)
print('IDF:',idf)
# 计算语料库中"one"的tf-idf值
tf_idf = corpus.tf_idf('one', corpus)
print('TF-IDF:',tf_idf)
jieba中实现的基于TF-IDF实现的关键词提取算法;
import jieba.analyse
text = '关键词是能够表达文档中心内容的词语,' \
'常用于计算机系统标引论文内容特征、信息检索、系统汇集以供读者检阅。' \
'关键词提取是文本挖掘领域的一个分支,是文本检索、文档比较、摘要生成、文档分类和聚类等文本挖掘研究的基础性工作'
keywords = jieba.analyse.extract_tags(text, topK=5, withWeight=False, allowPOS=())
print(keywords)
2)TextRank
1. PageRank
参考: textrank
TextRank的思想是:通过词和词之间的相邻关系构建图, 然后用PageRank迭代计算每一个结点的分数,根据分数排序来计算得到关键词;
这里说到了PageRank算法,实际上,TextRank是在PageRank算法基础上发展而来;pageRank算法的目的是为了度量网页的重要程度,该算法基于图,每一个网页看做做中的一个“结点”, 结点之间以“边”相连;如果网页A能够跳转到网页B,那么则有一条A指向B的有向边。这样,我们就可以构造出一个图模型。如下图所示。
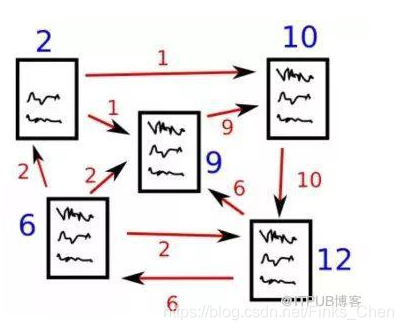
对于每一个结点来说,它包含一个入度列表和一个出度的列表,分别表示,能够跳转到该网页的结点和该网页能够跳转到的页面。
例如,Vi数据结构如下:
Vi :
{
In: [ V2, V3 ,V5]
Out: [V2,V6,V8,V9]
}
则其结点链接情况为:
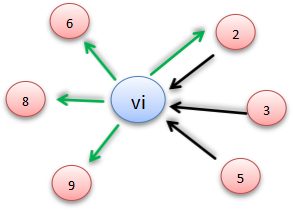
网页的重要度则和链接到的网页的数量有关,就是说在图中,结点的权值和边有关。为了给这些页面做一个重要度排名,我们需要计算一个称之为PageRank的分数,这个分数的设计公式为:
S
(
V
i
)
=
(
1
−
d
)
+
d
∗
∑
j
∈
I
n
(
V
i
)
1
∣
O
u
t
(
V
j
)
∣
S
(
V
j
)
S(V_i) = (1-d) + d * \sum_{j ∈ In(V_i)} \frac{1}{|Out(V_j)|}S(Vj)
S(Vi)=(1−d)+d∗j∈In(Vi)∑∣Out(Vj)∣1S(Vj)
上式子中,
S ( V i ) S(V_i) S(Vi):网页 V i V_i Vi的重要程度,初始化值可设为1;
d:阻尼系数,一般为0.85
I n ( V i ) In(V_i) In(Vi) :能跳转到网页 V i V_i Vi的页面, 在图中对应入度的点;
O u t ( V j ) Out(V_j) Out(Vj):网页 V j V_j Vj能够跳转到的页面,即出度的点;
算法的步骤为:
- 初始化权重
- 遍历图中所有结点,计算结点权重;
- 迭代更新权重;
我们假设网页以等概率(1/n)跳转到任何网页,再按照阻尼系数d,对这个等概率(1/n)与存在链接的网页的转移概率进行线性组合,那么马尔科夫链一定存在平稳分布,一定可以得到网页的PageRank值。所以PageRank的定义意味着网页浏览者按照以下方式在网上随机游走:以概率d按照存在的超链接随机跳转,以等概率从超链接跳转到下一个页面;或以概率(1-d)进行完全随机跳转,这时以等概率(1/n)跳转到任意网页。
PageRank的计算是一个迭代过程,先假设一个初始的PageRank分布,通过迭代,不断计算所有网页的PageRank值,直到收敛为止,也就是:PageRank向量最终会收敛于结点的状态转移概率矩阵;
2. TextRank
网页之间的链接关系可以用图表示,那么怎么把一个句子(可以看作词的序列)构建成图呢?TextRank认为某一个词与其前面的N个词、以及后面的N个词均具有图相邻关系(类似于N-gram语法模型)。具体实现:设置一个长度为N的滑动窗口,所有在这个窗口之内的词都视作词结点的相邻结点;则TextRank构建的词图为无向图。下图给出了由一个文档构建的词图(去掉了停用词并按词性做了筛选):
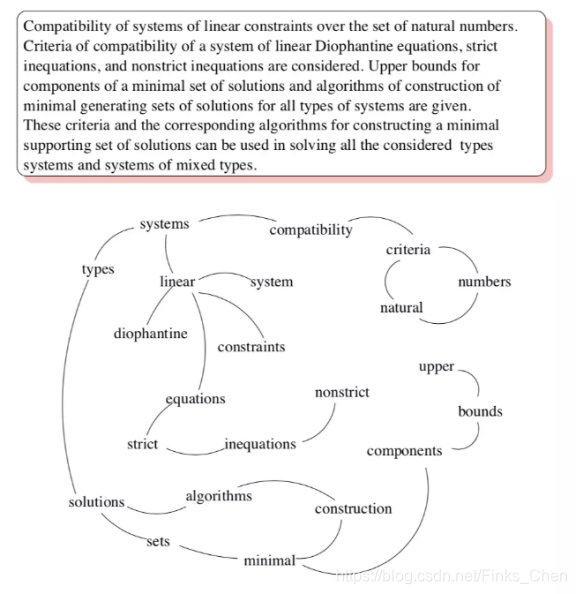
所以TextRank的迭代公式定义如下
S
(
V
i
)
=
(
1
−
d
)
+
d
∗
∑
j
∈
I
n
(
V
i
)
w
j
i
∑
V
k
∈
O
u
t
(
V
j
)
w
j
i
S
(
V
j
)
S(V_i) = (1-d) + d * \sum_{j ∈ In(V_i)} \frac{w_{ji}}{\sum_{V_k ∈Out(V_j)} w_{ji}}S(Vj)
S(Vi)=(1−d)+d∗j∈In(Vi)∑∑Vk∈Out(Vj)wjiwjiS(Vj)
这个公式多了一个权重;用来表示两个节点之间边的重要程度;一般用两个节点的相似度来表示权重;相似度预告,表示权重要大;
让我们理解TextRank算法。我列举了以下两种算法的相似之处:
- 用句子代替网页
- 任意两个句子的相似性等价于网页转换概率
- 相似性得分存储在一个方形矩阵中,类似于PageRank的矩阵M
TextRank算法是一种抽取式的无监督的文本摘要方法。让我们看一下我们将遵循的TextRank算法的流程:
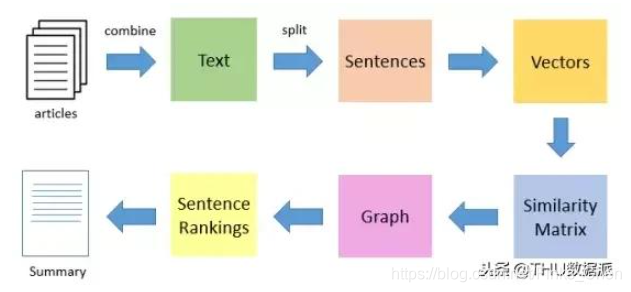
使用TextRank提取摘要的算法流程:
1)把文章整合分割成单个句子
2)计算句子向量间的相似性并存放在矩阵中(计算相似度可以用词频也可用向量计算)
3)然后将相似矩阵转换为以句子为节点、相似性得分为边的图结构,用于句子TextRank计算
4)最后,一定数量的排名最高的句子构成最后的摘要。

















 3132
3132

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









