






 本文介绍了数据编码的概念,包括像素任务、自测题,并探讨了音频和视频编码格式。同时,详细讲解了字符编码,如ASCII、EBCDIC、ANSI、Unicode,特别是UTF-8编码的规则和意义。最后,讨论了数据编码在实时流媒体服务器中的应用及解码中的校验问题。
本文介绍了数据编码的概念,包括像素任务、自测题,并探讨了音频和视频编码格式。同时,详细讲解了字符编码,如ASCII、EBCDIC、ANSI、Unicode,特别是UTF-8编码的规则和意义。最后,讨论了数据编码在实时流媒体服务器中的应用及解码中的校验问题。
数据编码
像素任务
前16bits表示画布的长和高,然后根据输入的0或1分别表示黑或白,以此来设计自己想要显示的图案。

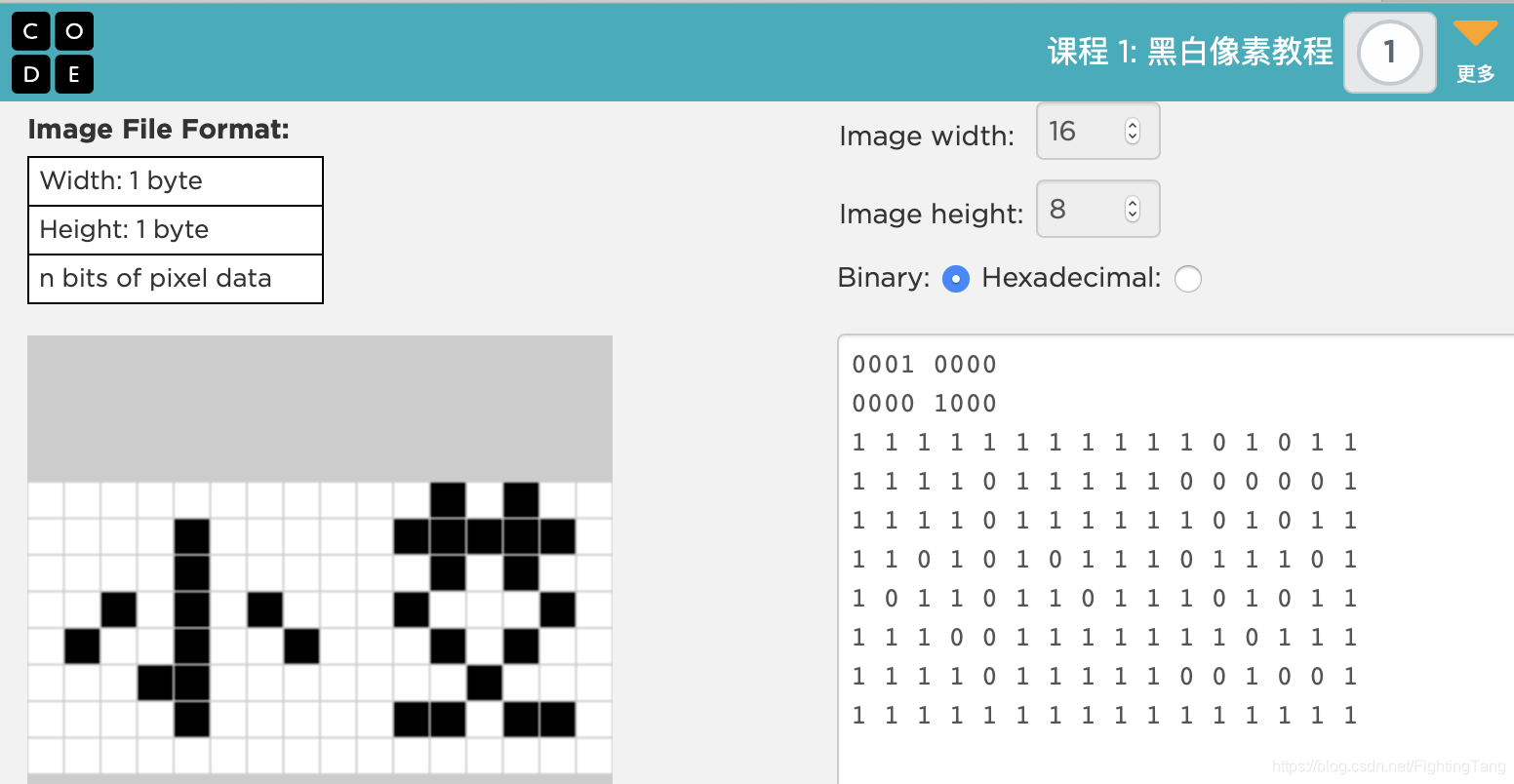
自测题
1) 110101010001转十六进制是多少?有什么最快的计算方法能得到结果?
答:(110101010001)B = (D51)H,快速计算,将二进制数从右往左每4个成有一组,每四位得到一个16进制数,就可以快速转换成16进制。本题,1101 0101 0001,对应16进制分别是,D 5 1,故得到答案。
2) 101011.101011对应的十进制是多少?
答:二进制转十进制,每个位上的数乘以相应的位权求和就得到对应的十进制数。
1*25+0*24+1*23+0*22+1*21+1*20+1*2-1+0*2-2+1*2-3+0*2-4+1*2-5+1*2-6=43.671875
3)常见的音频编码格式有哪些?
PCM、WAV、MP3、OGG、MPC、mp3PRO、WMA
4)常见的视频编码格式有哪些?
AVI、DV-AVI、MPEG、MOV、WMV
5) 一个尺寸8X8大小的png全黑图片前四个字节的十六进制值是什么?
答:前四个字节为(HEX)89 50 4E 47,对应编码为内容为.PNG。
6)UTF-8三字节的编码方式为:1110xxxx 10xxxxxx 10xxxxxx,汉字【中】的unicode编码十六进制是0x4e2d,unicode编码按三字节编码转换十六进制的utf编码的计算过程是什么?
答:(4e2d)16 -> (100111000101101)2,将二进制结果从右往左填充到3字节编码方式的x占位符中,不足补0。结果为11100100 10111000 10101101,转换成16进制结果为e4 b8 ad。
7)如果要提供一个实时的流媒体服务器,除了ffmpeg,还需要哪个组件?
答:ffserver,ffplay,ffprobe,负责响应客户端的流媒体请求,把流媒体数据发送给客户端。【本题答案不确定】 参考 参考2
拓展
数据编码
为了便于使用,容易记忆,常常要对计算机加工处理的对象进行编码,用一个编码符号代表一条信息或一串数据,这就是数据编码。
编码的主要目的是减少信息量,提高数据影响处理效率和精度。
我的粗略理解:数据编码是将数字信息与电信号等挂钩,将数字信息转化为电信号发送,尽可能的将电信号准确地转换为数字信息(能抗干扰)。
字符编码
字符编码(英语:Character encoding)也称字集码,是把字符集中的字符编码为指定集合中某一对象(例如:比特模式、自然数序列、8位组或者电脉冲),以便文本在计算机中存储和通过通信网络的传递。
ASCII和EBCDIC->ANSI编码->Unicode字符集
ASCII和EBCDIC:1字节,ASCII用低7bits存储,可表示128个字符;EBCDIC用8bits来存储,可表示256个字符。
ANSI 编码:2 个字节来代表一个字符。不同的国家和地区有不同的标准,例如:简体中文系统下,ANSI 编码代表 GB2312 编码,在日文操作系统下,ANSI 编码代表 JIS 编码。
Unicode字符集:将世界上所有的符号都纳入其中,现在的规模可以容纳100多万个符号。其字符集编码实现有UTF-8、UTF-16等。
MBCS(Muilti-Bytes Character Set,多字节字符集):用多个字节来表示一个字符的成为多字节字符集。
UTF-8
UTF-8:是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。编码规则:
(1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的。
(2)对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode码。
1字节 0xxxxxxx
2字节 110xxxxx 10xxxxxx
3字节 1110xxxx 10xxxxxx 10xxxxxx
4字节 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
5字节 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
6字节 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
例:
// "严"的Unicode编码是\u4e25【16进制】,即 100 1110 0010 0101
// 用UTF-8编码,"严"字需要三字节表示,则为1110xxxx 10xxxxxx 10xxxxxx 即"严"字->1110 0100 1011 1000 1010 0101,将unicode的二进制数串,从右往左填充x位,不足补0
// 所以得到UTF-8编码的结果为E4 B8 A5
// 前三个字节“EF BB BF”是表示UTF-8编码,Unicode编码的BOM头,UTF-8的BOM头可有可无
疑问:多字节表示时,为什么后面的字节要以10开头,如果不用10标识不是更节省空间吗?
思考:为了校正?因为这里解码时,以10开头是不符合任意字节的解析,所以容错性高?

















 314
314

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









