






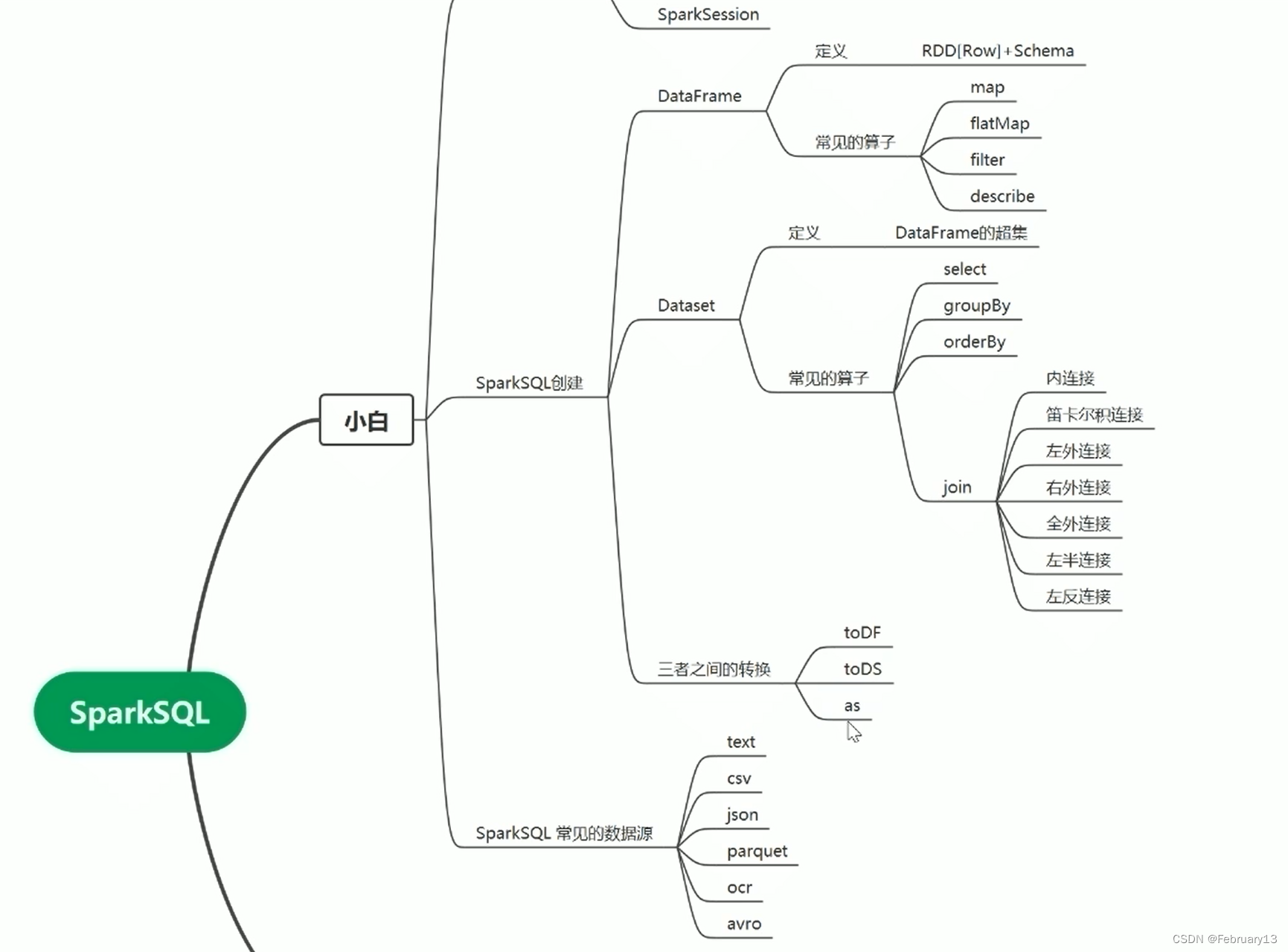
 RDD是Spark的基本数据处理单元,面向函数式编程,但大型数据集处理时可能因GC和IO操作导致资源消耗大。DataFrame在RDD上添加了schema,优化了序列化过程,适合使用SparkSQL。DataSet进一步优化,支持按需访问数据并提供类型安全。Encoder用于减少数据加载,提高效率。优化策略包括剪枝和谓词下推。
RDD是Spark的基本数据处理单元,面向函数式编程,但大型数据集处理时可能因GC和IO操作导致资源消耗大。DataFrame在RDD上添加了schema,优化了序列化过程,适合使用SparkSQL。DataSet进一步优化,支持按需访问数据并提供类型安全。Encoder用于减少数据加载,提高效率。优化策略包括剪枝和谓词下推。
RDD是弹性分布式数据集,基本数据处理单位,分布式的JAVA对象集合,RDD面向对象,对RDD的操作是面向函数式编程。RDD当数据量大的时候,频繁GC,IO序列反序列,资源消耗大。
DataFrame是在RDD的基础上包装一层schema(反射推断或代码定义【反射是通过检测已知数据样本的类型或数据结构自动推断和创建出对象的一种机制】),即描述它的结构,是分布式的Row对象的集合,每一行都是一样的结构,因此它在序列化和反序列化时省去了对结构的ser、deser;面向对象,可以使用sparksql;使用offheap即对外内存(默认是使用堆内存)可以提高对内存的利用率。
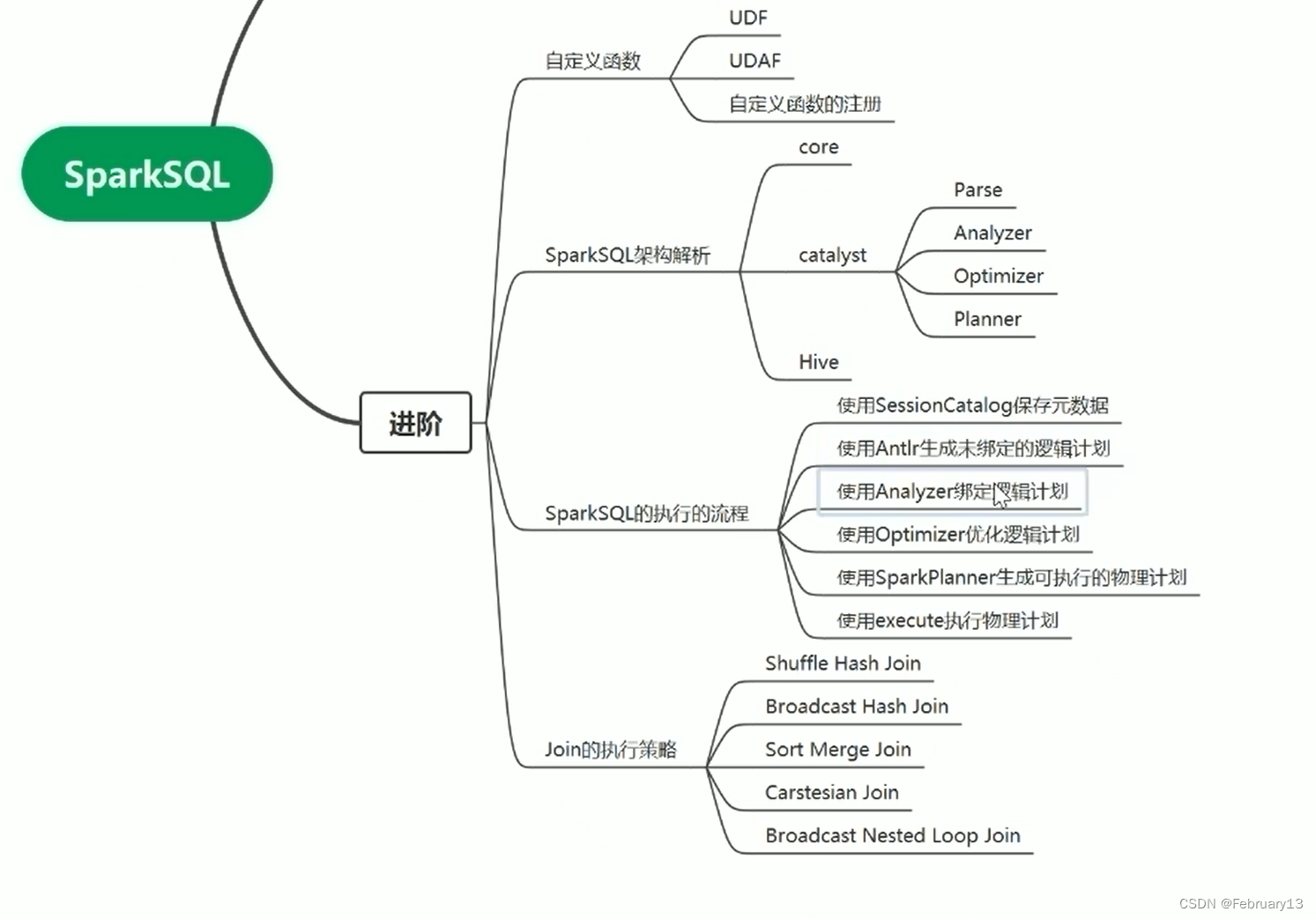
优化:剪枝,最好的运行优化就是不运行。即在执行计划树中将不必要运行的部分除去,谓词下推,依据是统计信息。
DataSet是在DF的基础上再包装一层,支持准确的访问到达路径,即无须反序列化全部对象,只反序列化需要的部分。
结合了RDD和DataFrame的优点,
引入了encoder,功能是将对象转换为二进制,以只加载和反序列化必要的部分数据,而不是全部数据,即根据过滤、聚合条件按需访问数据。此外,dataset在dataframe的基础上还增加了类型安全的特性。
dataset转换成dataframe .toDF()
DataFrame转换成DataSet .as[elementType]

















 689
689

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









