




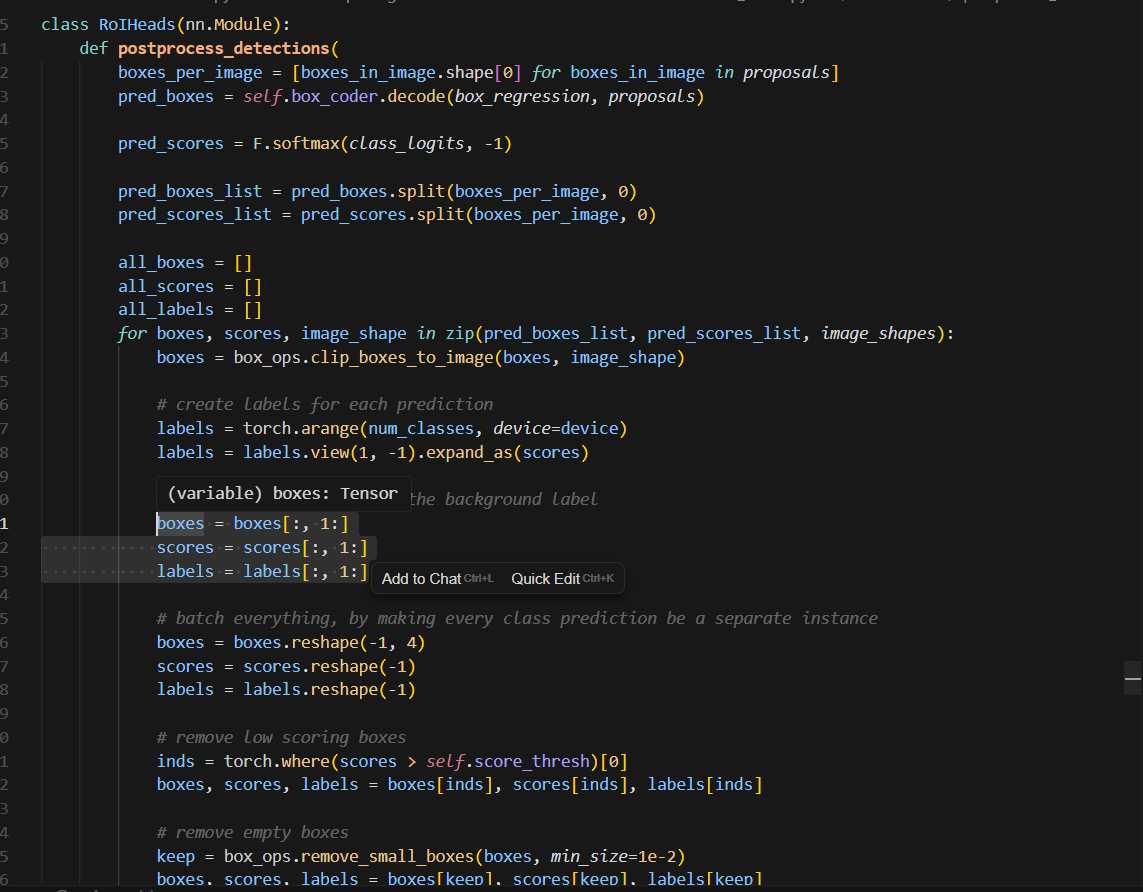
我在使用自定义数据集训练torchvision模型的时候注意到一个奇怪的事情,就是类别编号为0的类别,检测精度始终是0. 经过检查以后发现,新版本的torchvision官方库里的RoIHeads分类器把第0个输出通道对应到背景类。在进行检测推理时,后处理阶段会忽略第0个通道的输出值。
源代码:
class RoIHeads(nn.Module):
__annotations__ = {
"box_coder": det_utils.BoxCoder,
"proposal_matcher": det_utils.Matcher,
"fg_bg_sampler": det_utils.BalancedPositiveNegativeSampler,
}
def __init__(
self,
box_roi_pool,
box_head,
box_predictor,
# Faster R-CNN training
fg_iou_thresh,
bg_iou_thresh,
batch_size_per_image,
positive_fraction,
bbox_reg_weights,
# Faster R-CNN inference
score_thresh,
nms_thresh,
detections_per_img,
# Mask
mask_roi_pool=None,
mask_head=None,
mask_predictor=None,
keypoint_roi_pool=None,
keypoint_head=None,
keypoint_predictor=None,
):
super().__init__()
self.box_similarity = box_ops.box_iou
# assign ground-truth boxes for each proposal
self.proposal_matcher = det_utils.Matcher(fg_iou_thresh, bg_iou_thresh, allow_low_quality_matches=False)
self.fg_bg_sampler = det_utils.BalancedPositiveNegativeSampler(batch_size_per_image, positive_fraction)
if bbox_reg_weights is None:
bbox_reg_weights = (10.0, 10.0, 5.0, 5.0)
self.box_coder = det_utils.BoxCoder(bbox_reg_weights)
self.box_roi_pool = box_roi_pool
self.box_head = box_head
self.box_predictor = box_predictor
self.score_thresh = score_thresh
self.nms_thresh = nms_thresh
self.detections_per_img = detections_per_img
self.mask_roi_pool = mask_roi_pool
self.mask_head = mask_head
self.mask_predictor = mask_predictor
self.keypoint_roi_pool = keypoint_roi_pool
self.keypoint_head = keypoint_head
self.keypoint_predictor = keypoint_predictor
def has_mask(self):
if self.mask_roi_pool is None:
return False
if self.mask_head is None:
return False
if self.mask_predictor is None:
return False
return True
def has_keypoint(self):
if self.keypoint_roi_pool is None:
return False
if self.keypoint_head is None:
return False
if self.keypoint_predictor is None:
return False
return True
def assign_targets_to_proposals(self, proposals, gt_boxes, gt_labels):
# type: (list[Tensor], list[Tensor], list[Tensor]) -> tuple[list[Tensor], list[Tensor]]
matched_idxs = []
labels = []
for proposals_in_image, gt_boxes_in_image, gt_labels_in_image in zip(proposals, gt_boxes, gt_labels):
if gt_boxes_in_image.numel() == 0:
# Background image
device = proposals_in_image.device
clamped_matched_idxs_in_image = torch.zeros(
(proposals_in_image.shape[0],), dtype=torch.int64, device=device
)
labels_in_image = torch.zeros((proposals_in_image.shape[0],), dtype=torch.int64, device=device)
else:
# set to self.box_similarity when https://github.com/pytorch/pytorch/issues/27495 lands
match_quality_matrix = box_ops.box_iou(gt_boxes_in_image, proposals_in_image)
matched_idxs_in_image = self.proposal_matcher(match_quality_matrix)
clamped_matched_idxs_in_image = matched_idxs_in_image.clamp(min=0)
labels_in_image = gt_labels_in_image[clamped_matched_idxs_in_image]
labels_in_image = labels_in_image.to(dtype=torch.int64)
# Label background (below the low threshold)
bg_inds = matched_idxs_in_image == self.proposal_matcher.BELOW_LOW_THRESHOLD
labels_in_image[bg_inds] = 0
# Label ignore proposals (between low and high thresholds)
ignore_inds = matched_idxs_in_image == self.proposal_matcher.BETWEEN_THRESHOLDS
labels_in_image[ignore_inds] = -1 # -1 is ignored by sampler
matched_idxs.append(clamped_matched_idxs_in_image)
labels.append(labels_in_image)
return matched_idxs, labels
def subsample(self, labels):
# type: (list[Tensor]) -> list[Tensor]
sampled_pos_inds, sampled_neg_inds = self.fg_bg_sampler(labels)
sampled_inds = []
for img_idx, (pos_inds_img, neg_inds_img) in enumerate(zip(sampled_pos_inds, sampled_neg_inds)):
img_sampled_inds = torch.where(pos_inds_img | neg_inds_img)[0]
sampled_inds.append(img_sampled_inds)
return sampled_inds
def add_gt_proposals(self, proposals, gt_boxes):
# type: (list[Tensor], list[Tensor]) -> list[Tensor]
proposals = [torch.cat((proposal, gt_box)) for proposal, gt_box in zip(proposals, gt_boxes)]
return proposals
def check_targets(self, targets):
# type: (Optional[list[dict[str, Tensor]]]) -> None
if targets is None:
raise ValueError("targets should not be None")
if not all(["boxes" in t for t in targets]):
raise ValueError("Every element of targets should have a boxes key")
if not all(["labels" in t for t in targets]):
raise ValueError("Every element of targets should have a labels key")
if self.has_mask():
if not all(["masks" in t for t in targets]):
raise ValueError("Every element of targets should have a masks key")
def select_training_samples(
self,
proposals, # type: list[Tensor]
targets, # type: Optional[list[dict[str, Tensor]]]
):
# type: (...) -> tuple[list[Tensor], list[Tensor], list[Tensor], list[Tensor]]
self.check_targets(targets)
if targets is None:
raise ValueError("targets should not be None")
dtype = proposals[0].dtype
device = proposals[0].device
gt_boxes = [t["boxes"].to(dtype) for t in targets]
gt_labels = [t["labels"] for t in targets]
# append ground-truth bboxes to propos
proposals = self.add_gt_proposals(proposals, gt_boxes)
# get matching gt indices for each proposal
matched_idxs, labels = self.assign_targets_to_proposals(proposals, gt_boxes, gt_labels)
# sample a fixed proportion of positive-negative proposals
sampled_inds = self.subsample(labels)
matched_gt_boxes = []
num_images = len(proposals)
for img_id in range(num_images):
img_sampled_inds = sampled_inds[img_id]
proposals[img_id] = proposals[img_id][img_sampled_inds]
labels[img_id] = labels[img_id][img_sampled_inds]
matched_idxs[img_id] = matched_idxs[img_id][img_sampled_inds]
gt_boxes_in_image = gt_boxes[img_id]
if gt_boxes_in_image.numel() == 0:
gt_boxes_in_image = torch.zeros((1, 4), dtype=dtype, device=device)
matched_gt_boxes.append(gt_boxes_in_image[matched_idxs[img_id]])
regression_targets = self.box_coder.encode(matched_gt_boxes, proposals)
return proposals, matched_idxs, labels, regression_targets
def postprocess_detections(
self,
class_logits, # type: Tensor
box_regression, # type: Tensor
proposals, # type: list[Tensor]
image_shapes, # type: list[tuple[int, int]]
):
# type: (...) -> tuple[list[Tensor], list[Tensor], list[Tensor]]
device = class_logits.device
num_classes = class_logits.shape[-1]
boxes_per_image = [boxes_in_image.shape[0] for boxes_in_image in proposals]
pred_boxes = self.box_coder.decode(box_regression, proposals)
pred_scores = F.softmax(class_logits, -1)
pred_boxes_list = pred_boxes.split(boxes_per_image, 0)
pred_scores_list = pred_scores.split(boxes_per_image, 0)
all_boxes = []
all_scores = []
all_labels = []
for boxes, scores, image_shape in zip(pred_boxes_list, pred_scores_list, image_shapes):
boxes = box_ops.clip_boxes_to_image(boxes, image_shape)
# create labels for each prediction
labels = torch.arange(num_classes, device=device)
labels = labels.view(1, -1).expand_as(scores)
# remove predictions with the background label
boxes = boxes[:, 1:]
scores = scores[:, 1:]
labels = labels[:, 1:]
# batch everything, by making every class prediction be a separate instance
boxes = boxes.reshape(-1, 4)
scores = scores.reshape(-1)
labels = labels.reshape(-1)
# remove low scoring boxes
inds = torch.where(scores > self.score_thresh)[0]
boxes, scores, labels = boxes[inds], scores[inds], labels[inds]
# remove empty boxes
keep = box_ops.remove_small_boxes(boxes, min_size=1e-2)
boxes, scores, labels = boxes[keep], scores[keep], labels[keep]
# non-maximum suppression, independently done per class
keep = box_ops.batched_nms(boxes, scores, labels, self.nms_thresh)
# keep only topk scoring predictions
keep = keep[: self.detections_per_img]
boxes, scores, labels = boxes[keep], scores[keep], labels[keep]
all_boxes.append(boxes)
all_scores.append(scores)
all_labels.append(labels)
return all_boxes, all_scores, all_labels
def forward(
self,
features: dict[str, torch.Tensor],
proposals: list[torch.Tensor],
image_shapes: list[tuple[int, int]],
targets: Optional[list[dict[str, torch.Tensor]]] = None,
) -> tuple[list[dict[str, torch.Tensor]], dict[str, torch.Tensor]]:
"""
Args:
features (List[Tensor])
proposals (List[Tensor[N, 4]])
image_shapes (List[Tuple[H, W]])
targets (List[Dict])
"""
if targets is not None:
for t in targets:
# TODO: https://github.com/pytorch/pytorch/issues/26731
floating_point_types = (torch.float, torch.double, torch.half)
if t["boxes"].dtype not in floating_point_types:
raise TypeError(f"target boxes must of float type, instead got {t['boxes'].dtype}")
if not t["labels"].dtype == torch.int64:
raise TypeError(f"target labels must of int64 type, instead got {t['labels'].dtype}")
if self.has_keypoint():
if not t["keypoints"].dtype == torch.float32:
raise TypeError(f"target keypoints must of float type, instead got {t['keypoints'].dtype}")
if self.training:
proposals, matched_idxs, labels, regression_targets = self.select_training_samples(proposals, targets)
else:
labels = None
regression_targets = None
matched_idxs = None
box_features = self.box_roi_pool(features, proposals, image_shapes)
box_features = self.box_head(box_features)
class_logits, box_regression = self.box_predictor(box_features)
result: list[dict[str, torch.Tensor]] = []
losses = {}
if self.training:
if labels is None:
raise ValueError("labels cannot be None")
if regression_targets is None:
raise ValueError("regression_targets cannot be None")
loss_classifier, loss_box_reg = fastrcnn_loss(class_logits, box_regression, labels, regression_targets)
losses = {"loss_classifier": loss_classifier, "loss_box_reg": loss_box_reg}
else:
boxes, scores, labels = self.postprocess_detections(class_logits, box_regression, proposals, image_shapes)
num_images = len(boxes)
for i in range(num_images):
result.append(
{
"boxes": boxes[i],
"labels": labels[i],
"scores": scores[i],
}
)
if self.has_mask():
mask_proposals = [p["boxes"] for p in result]
if self.training:
if matched_idxs is None:
raise ValueError("if in training, matched_idxs should not be None")
# during training, only focus on positive boxes
num_images = len(proposals)
mask_proposals = []
pos_matched_idxs = []
for img_id in range(num_images):
pos = torch.where(labels[img_id] > 0)[0]
mask_proposals.append(proposals[img_id][pos])
pos_matched_idxs.append(matched_idxs[img_id][pos])
else:
pos_matched_idxs = None
if self.mask_roi_pool is not None:
mask_features = self.mask_roi_pool(features, mask_proposals, image_shapes)
mask_features = self.mask_head(mask_features)
mask_logits = self.mask_predictor(mask_features)
else:
raise Exception("Expected mask_roi_pool to be not None")
loss_mask = {}
if self.training:
if targets is None or pos_matched_idxs is None or mask_logits is None:
raise ValueError("targets, pos_matched_idxs, mask_logits cannot be None when training")
gt_masks = [t["masks"] for t in targets]
gt_labels = [t["labels"] for t in targets]
rcnn_loss_mask = maskrcnn_loss(mask_logits, mask_proposals, gt_masks, gt_labels, pos_matched_idxs)
loss_mask = {"loss_mask": rcnn_loss_mask}
else:
labels = [r["labels"] for r in result]
masks_probs = maskrcnn_inference(mask_logits, labels)
for mask_prob, r in zip(masks_probs, result):
r["masks"] = mask_prob
losses.update(loss_mask)
# keep none checks in if conditional so torchscript will conditionally
# compile each branch
if (
self.keypoint_roi_pool is not None
and self.keypoint_head is not None
and self.keypoint_predictor is not None
):
keypoint_proposals = [p["boxes"] for p in result]
if self.training:
# during training, only focus on positive boxes
num_images = len(proposals)
keypoint_proposals = []
pos_matched_idxs = []
if matched_idxs is None:
raise ValueError("if in trainning, matched_idxs should not be None")
for img_id in range(num_images):
pos = torch.where(labels[img_id] > 0)[0]
keypoint_proposals.append(proposals[img_id][pos])
pos_matched_idxs.append(matched_idxs[img_id][pos])
else:
pos_matched_idxs = None
keypoint_features = self.keypoint_roi_pool(features, keypoint_proposals, image_shapes)
keypoint_features = self.keypoint_head(keypoint_features)
keypoint_logits = self.keypoint_predictor(keypoint_features)
loss_keypoint = {}
if self.training:
if targets is None or pos_matched_idxs is None:
raise ValueError("both targets and pos_matched_idxs should not be None when in training mode")
gt_keypoints = [t["keypoints"] for t in targets]
rcnn_loss_keypoint = keypointrcnn_loss(
keypoint_logits, keypoint_proposals, gt_keypoints, pos_matched_idxs
)
loss_keypoint = {"loss_keypoint": rcnn_loss_keypoint}
else:
if keypoint_logits is None or keypoint_proposals is None:
raise ValueError(
"both keypoint_logits and keypoint_proposals should not be None when not in training mode"
)
keypoints_probs, kp_scores = keypointrcnn_inference(keypoint_logits, keypoint_proposals)
for keypoint_prob, kps, r in zip(keypoints_probs, kp_scores, result):
r["keypoints"] = keypoint_prob
r["keypoints_scores"] = kps
losses.update(loss_keypoint)
return result, losses


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









