



 博主解析前端查询查询失败(101, 100)的异常,推测是由于与定时任务SQL冲突。通过暂停定时任务、前端处理异常和提出改进策略,如Redis锁或预加载数据,揭示了并发问题。文章探讨了可能的解决办法和权衡考虑。
博主解析前端查询查询失败(101, 100)的异常,推测是由于与定时任务SQL冲突。通过暂停定时任务、前端处理异常和提出改进策略,如Redis锁或预加载数据,揭示了并发问题。文章探讨了可能的解决办法和权衡考虑。
前端和测试反馈某个功能查询时间特别长,还偶尔会有查询失败返回500的情况,查询时间长比较正常,后续也在优化这个查询流程,但查询失败需要找找原因,于是找运维拿了日志看看具体报错的情况。
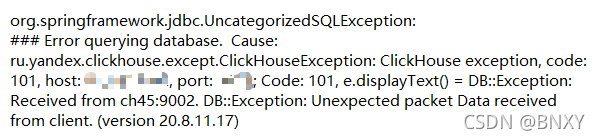
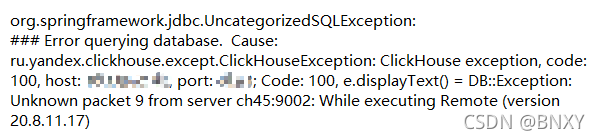
错误码是101和100。
对应的查询语句都是没问题的,而且Code101对应的查询语句并不固定,上一次报101的语句和下一次报101的语句并不是同一个。
拿着报错信息瞎百度了一通,网上也没有找到有人说这两个错误码的相关内。最后根据报错提示“Unexpected packet Data received from client”和“While executing Remote”自己做了些猜想:报错的sql语句虽然不固定,但来源只有两个地方,一个是这个查询过慢的请求,一个是每隔一小会就会执行的定时任务,请求查询过慢是因为这个请求要不断地递归查数据并按算式解析,sql查询的频率很高,有没有可能是请求获取的sql数据和定时任务获取的sql数据同时返回,而clickhouse不能把二者区分开导致报错。
于是把定时任务暂时停止,又打包给了运维和测试让他们再试试。之后经过一段时间的测试,确定问题并没有复现,判定猜测成立。
但定时任务肯定是要跑的,只是发现了问题,并没有解决。最后采取的方案是后端什么都不做,如果有报错就前端处理一下,提示用户重新查询。这个BUG的成因如果我并没有理解错,那不止这个请求,任何请求查的sql都有概率和定时任务的查的sql撞车,只是在这之前的其它请求都没有查sql查得这么频繁,所以偶尔出现失败的情况也没被重视,如果要根除这种现象得把项目所有的sql查询都处理一遍。但这个项目临近交接,大改底层有风险没时间,BUG也只是偶发性出现,还是稳妥点比较合适,所以还是选择前端处理
当然解决的办法还是可以纸上谈兵讨论讨论的。
给数据库加锁应该行不通,请求和定时任务查的都不是同一张表。
自己想到的一种思路是或许可以用消息队列来防止撞车,不过消息队列我也只是了解一点,具体能不能实现其实不太确定。
另一种是网上看到的一个不错的思路,给一个Reids键变量来模拟悲观锁,查询sql之前先查询这个Redis变量的值,为false就等一等,为true就更改为false并执行查询,接收到sql数据后再给Redis变量赋true。
具体到项目的话,还有就是把可能要查询的数据先整块查出来放集合里,后续再查询的时候直接查集合数据,这个优化方案也是预定的优化思路,不过交接前没搞完,留给接手的开发来弄了。
最后最治标治本的解决思路,就是等clickhouse官方修复这个BUG了,如果不是BUG而是我操作的问题的话,也请路过的大佬指教一下。

















 962
962

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









