




 这篇博客介绍了Python的基础概念,包括栈的操作如入栈、出栈、获取栈顶元素和判断栈是否为空,zip和enumerate函数的使用,以及tuple、count和index的方法。还探讨了list和set的区别,集合的交集和并集,以及dict字典的特性如通过key查找值、删除操作和统计数字重复次数的应用。
这篇博客介绍了Python的基础概念,包括栈的操作如入栈、出栈、获取栈顶元素和判断栈是否为空,zip和enumerate函数的使用,以及tuple、count和index的方法。还探讨了list和set的区别,集合的交集和并集,以及dict字典的特性如通过key查找值、删除操作和统计数字重复次数的应用。
栈的工作原理
入栈 append
出栈 pop
栈顶元素
栈的长度 len
栈是否为空 len == 0
zip&enumerate

zip函数将两个字符串元素一一对应拆分合并成键值对
enumerate函数将一个字符串拆开并按照顺序从0开始对元素编号形成一个对象
tuple

例;
Users = ('root','westos','redhat')
Passwds = ('123','456','789')
#index slide
print(Users[0])
print(Users[-1])
print(Users[1:])
print(Users[::-1])
#repeat
print(Passwds * 3)
#link
print(Users + ('linux','python'))
#in /not in
print('westos' in Users)
print('westos' not in Users)
#for
for user in Users:
print(user)
for index,user in enumerate(Users):
print(index,user)
for user,passwd in zip(Users,Passwds):
print(user,':',passwd)
输出
/root/PycharmProjects/westos/venv/bin/python /root/PycharmProjects/westos/test/test1.py
root
redhat
('westos', 'redhat')
('redhat', 'westos', 'root')
('123', '456', '789', '123', '456', '789', '123', '456', '789')
('root', 'westos', 'redhat', 'linux', 'python')
True
False
root
westos
redhat
(0, 'root')
(1, 'westos')
(2, 'redhat')
('root', ':', '123')
('westos', ':', '456')
('redhat', ':', '789')Process finished with exit code 0
count&index
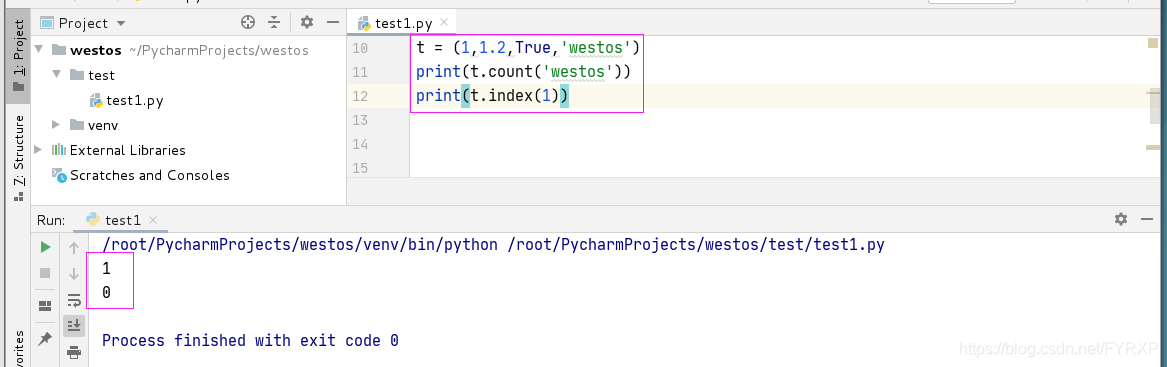
count统计出现的次数
index返回索引
练习
去除最高最低分,求平均分
scores = (100,89,45,78,65)
scoreli = list(scores)
scoreli.sort()
t = tuple(scoreli)
print(t)
minscore,*middlescore,maxscore = t
print(minscore)
print(middlescore)
print(maxscore)
print(sum(middlescore) / len(middlescore))
list和set的区别
s = {1,2,3,1,2,3,4,5}
print(s)
print(type(s))
s1 = {1}
print(s1)
print(type(s1))
s2 = {}
print(type(s2))
s3 = set([])
print(type(s3))
li = [1,2,3,1,2,3]
print(list(set(li)))
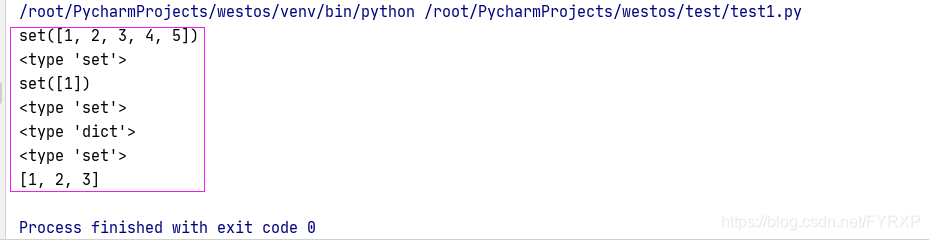
list可以有重复,而set重复值会忽略,list转换为set时只保留不重复的值(对象)
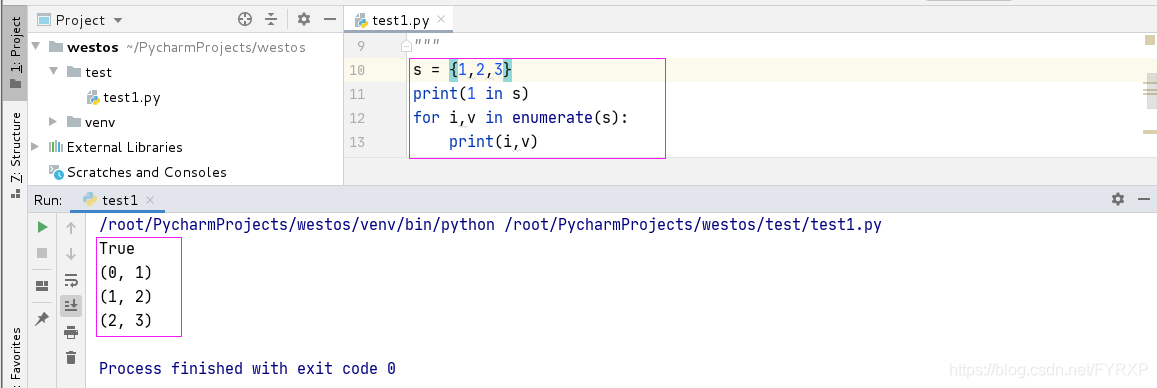
set 不能通过索引获取值
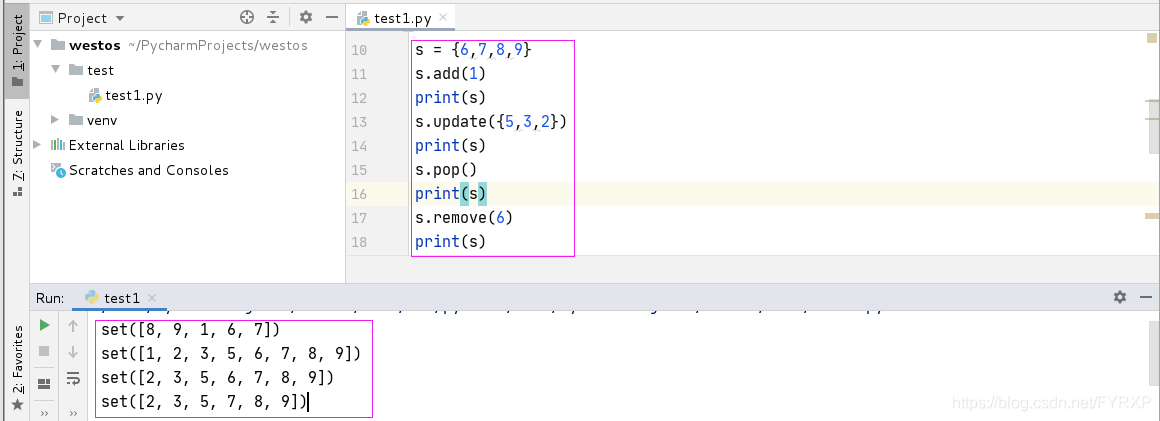
集合的交集,并集等
# 交集,并集,差集
s1 = {1,2,3}
s2 = {2,3,4}
# # 并集
print('并集:',s1.union(s2))
print('并集:',s1 | s2)
# # 交集
print('交集:',s1.intersection(s2))
print('交集:',s1 & s2)
# # 差集
print('差集:',s1.difference(s2)) # s1-(s1&s2)
print('差集:',s2.difference(s1)) # s2-(s1&s2)
# # 对等差分:并集-差集
print('对等差分:',s1.symmetric_difference(s2))
print('对等差分:',s1^s2)
s3 = {1,2}
s4 = {1,2,3}
print(s3.issuperset(s4))
print(s3.issubset(s4))
print(s3.isdisjoint(s4))
输出
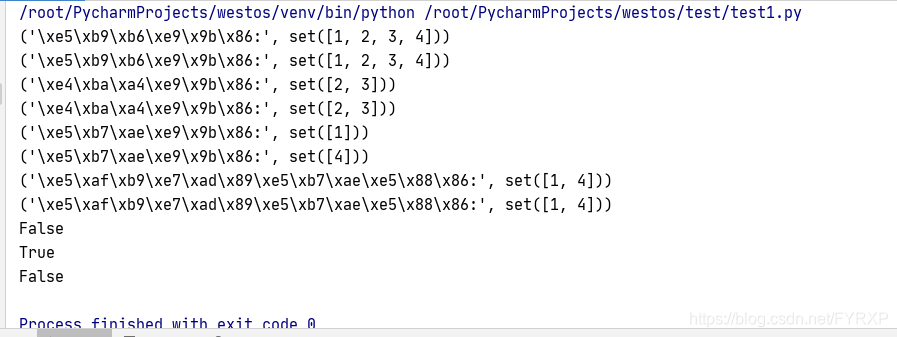
练习
明明想在学校中请一些同学一起做一项问卷调查,为了实验的客观性
他先用计算机生成了N个1~1000之间的随机整数(N<=1000),N是用户输入的,
对于
其中重复的数字,只保留一个,把其余相同的数字去掉,不同的数对应着不>同的学生的学号,然后再把这些
数从小到大排序,按照排好的顺序去找同学做调查,请你协助明明完成“去重
”与排序工作

dict字典
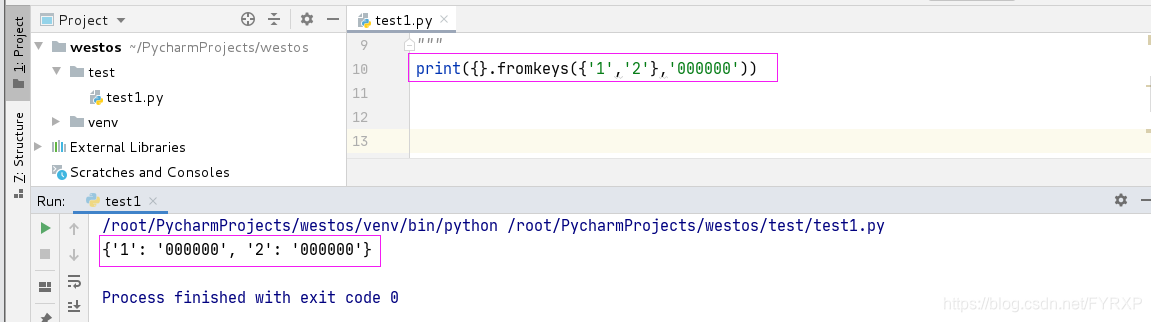

字典没有索引,可以通过key查找对应值
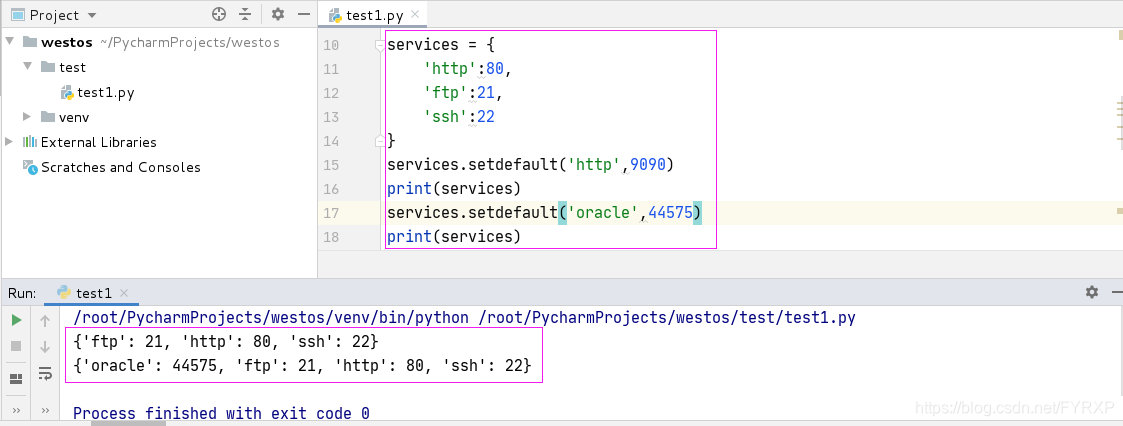
字典中通过setdefault函数无法覆盖修改已经存在的key对应值,可以添加新的键值对
字典中的del(删除) pop(出栈) popitem
services = {
'http':80,
'ftp':21,
'ssh':22
}
del services['http']
print(services)
item = services.pop('ftp')
print(item)
print(services)
item = services.popitem()
print('The last key-value is:',item)
print(services)
services.clear()
print(services)
输出

clear清空所有 pop和del删除指定 pop不能删除最后一个元素,可以通过popitem删除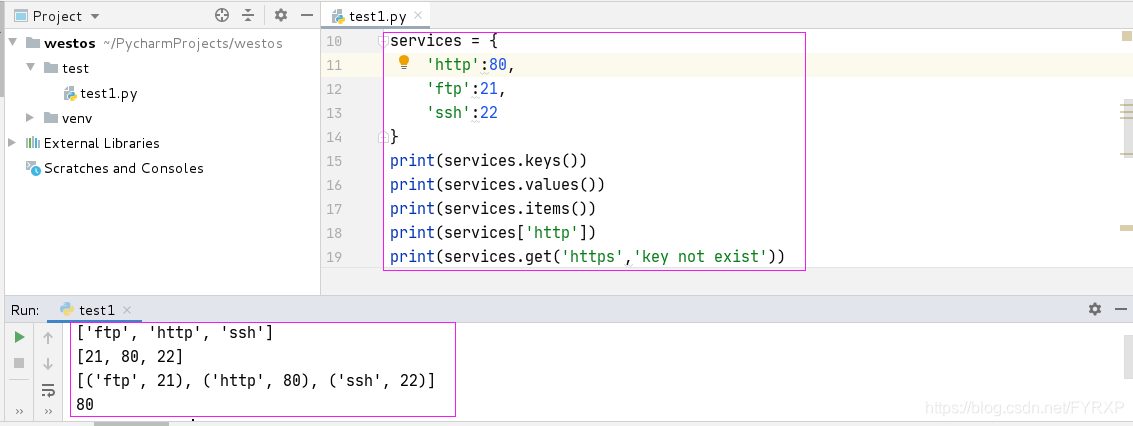
get函数时在找不到对应key时候打印后面的参数“key not exist” 如果没有该参数则默认不打印
练习
数字重复统计:
1). 随机生成1000个整数;
2). 数字的范围[20, 100],
3). 升序输出所有不同的数字及其每个数字重复的次数;
import random
all_nums = []
for item in range(1000):
all_nums.append(random.randint(20,100))
# print(all_nums)
sorted_nums = sorted(all_nums)
num_dict = {}
for num in sorted_nums:
if num in num_dict:
num_dict[num] += 1
else:
num_dict[num] = 1
print(num_dict)

利用字典,实现次数统计
# 1. 随机生成100个卡号;
# 卡号以6102009开头, 后面3位依次是 (001, 002, 003, 100),
# 2. 生成关于银行卡号的字典, 默认每个卡号的初始密码为"redhat";# 3. 输出卡号和密码信息, 格式如下:
卡号 密码
6102009001 000000
import random
account_num = []
for i in range(100):
account_num.append('6102009%.3d' %(i+1))
account_info = {}.fromkeys(account_num,'redhat')
print('卡号\t\t\t\t 密码')
for k,v in account_info.items():
print(k,'\t\t',v)


















 1529
1529

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









