




 SSD是一种目标检测技术,采用单阶段方法实现快速检测。通过在不同特征图上使用多种默认框,结合硬负例挖掘等策略提升检测精度,尤其适用于小物体检测。
SSD是一种目标检测技术,采用单阶段方法实现快速检测。通过在不同特征图上使用多种默认框,结合硬负例挖掘等策略提升检测精度,尤其适用于小物体检测。
一、简介
SSD提出于2016年三月20日,比YOLO v1早两个月,但是它其中提到了YOLO,所以应该是比YOLO晚的。SSD也是一个one stage方法,它其中的改进包括:
1.使用小卷积及取预测类别和定位偏差,
2.使用不同的filter去对于不同宽高比(aspect ratio)进行判断,
3.在多个feature map上进行判断。
二、基本思想
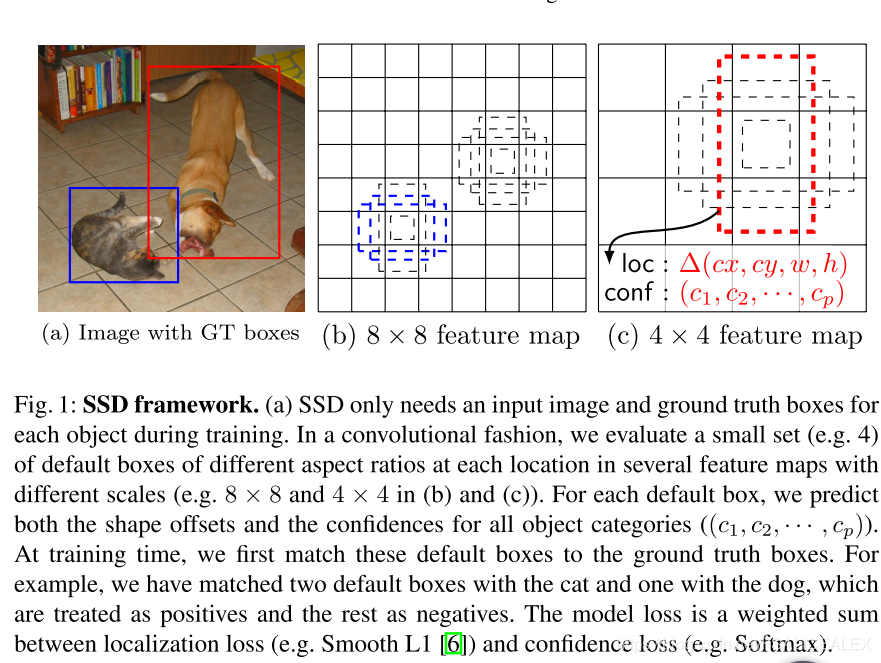
对于每个feature map,我们在每个位置上都设置几个默认b-box,我们的目标是对于这些b-box预测偏移(off-set)以纠正偏差,兵器预测其中含有物体的可能性。最终使用NMS来获得b-box。
三、模型
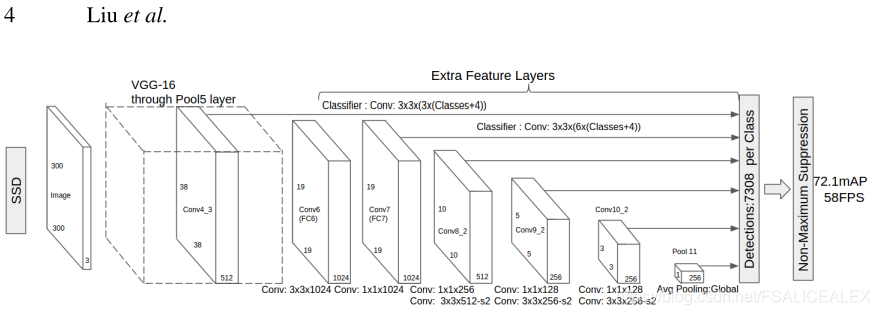
对于一个m*n的feature map,每个feature map cell上有k个默认的b-box(假设的,在结构上只体现为输出的参数),它们或者是高宽比不同,或者是大小不同。每个b-box需要预测出4个位置参数,c个类别参数。由于使用的是卷积去对这些参数统一处理,所以总共有m*n*k*(c+4)个参数,对于每个map。ssd与其他方法的关键不同是GT信息需要分配给固定数量的输出b-box中的特定b-box。
四、训练
1.匹配策略
使用multibox的策略,对每一个GT b-box匹配一个default box(最大IOU,而且不重复),之后,对每一个default box,匹配一个GT,选择IOU大于阈值的那个。所以,对于一个GT,我们至少能够匹配两个gt b-box(如果这两个匹配不重复的话)。
2.训练目标
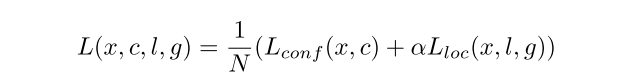
x, c, l, g分别是为输入图片,confidence,预测b-box,GT b-box。定位误差Lloc使用Smooth L1 loss ,confidence损失使用softmax损失,alpha取1。
Lloc当然是只有匹配上的b-box才会计算损失。也就是只有FP才进行损失传递。
其中Lconf是对于confidence的预测,与负样本有关,对于一张图像,只有匹配上的b-box具有匹配物体种类的正confidence,而其余的b-box作为负样本,对于该物体种类的confidence应该为0,但这样会出现正负样本十分不均衡的现象,因此作者将如果产生loss较大的那些样本挑出来作为负样本,进行训练。可以详见下面的文章:
https://blog.youkuaiyun.com/tomxiaodai/article/details/82354720
3.尺度和宽高比的选择。
简而言之,越后面的feature map,其尺度越大(对应于原图中的尺度)。
4.负样本平衡(Hard negative mining)
在计算损失(confidence损失)的时候,大部分是负样本,因此正负样本不平衡,因此,文中只对那些loss较大的作为负样本,进行损失传递。大概是1:3,正:负
5.数据增强
采用了两种增强数据的方法,一种是采样部分,使得对于物体的最小IOU为0.1,0.3,0.5,0.7,0.9。
另一种是随机取patch。
五、实验现象
大多数的confident检测都是对的,召回率为85%-90%。和RCNN比,更少的定位错误,但是分类的错误多一些。对b-box的尺寸敏感,当b-box小的时候普遍会下降很多Ap,也就是说对小物体的检测尤为不好,这可能是由于尽管使用了较浅的feature map,小物体的信息依然被丢弃了,但是其实对于中型物体的判断也是不太好。同时,它对于物体的纵横比适应的比较好。如下图
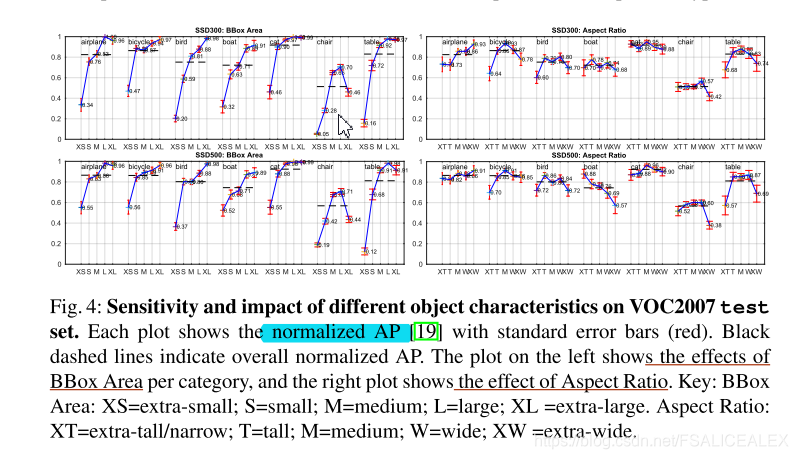
文中还对模型进行了分析,对各个变量影响进行了分析,结果显示都使用的话会提高不少,值得一提的是这个东西 : DeepLab-LargeFOV 。还有下面的分析:
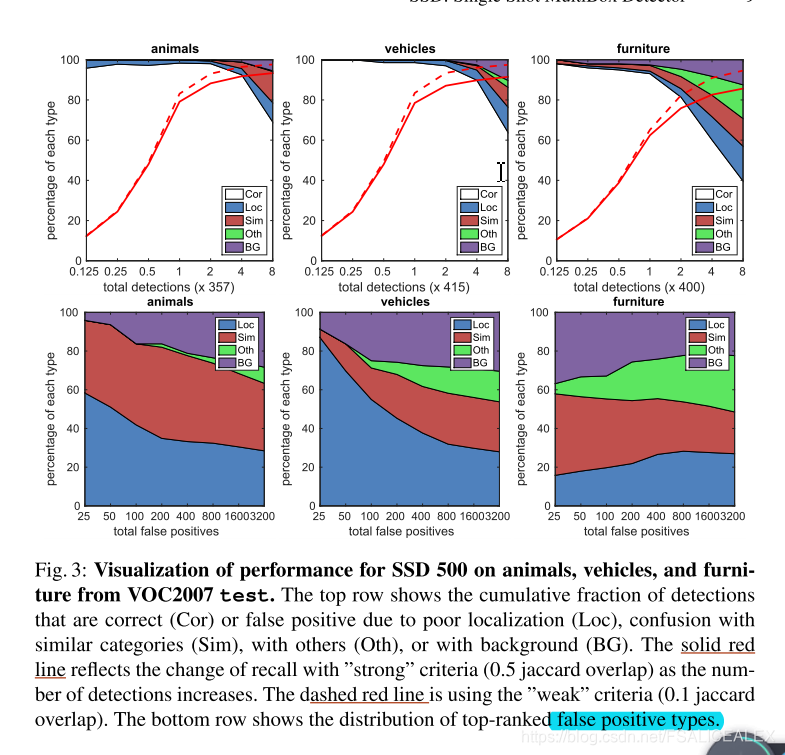
可以看出来,四类错误差不多,对于家具的判断蜜汁不准。
具体效果如下图:

对于重叠物体判断的不错,对于某些小物体也判断的不错,但是有些物体就蜜汁不准,比如说远处的人。

















 11万+
11万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









