







 本文详细介绍了马来西亚电商市场的潜力,包括其国民收入、年轻人比例、电商市场规模和年复合增长率。政府支持电商发展,设有优惠政策。主要税收为进口税,个人包裹免税额为500MYR。物流效率高,Shopee的SLS提供成本效益高的配送。文章还列出不可通过SLS运输的产品类别。马来西亚消费者在母婴、时尚、美妆保健和家居用品上有特定喜好,3C品类中偏好中国品牌和无线电子设备。电子支付普及,移动购物活跃。
本文详细介绍了马来西亚电商市场的潜力,包括其国民收入、年轻人比例、电商市场规模和年复合增长率。政府支持电商发展,设有优惠政策。主要税收为进口税,个人包裹免税额为500MYR。物流效率高,Shopee的SLS提供成本效益高的配送。文章还列出不可通过SLS运输的产品类别。马来西亚消费者在母婴、时尚、美妆保健和家居用品上有特定喜好,3C品类中偏好中国品牌和无线电子设备。电子支付普及,移动购物活跃。
马来西亚基础信息:
马来西亚是东南亚第三大经济体,国民富足;并且年轻人众多,对中国的产品非常喜爱。
国民经济:2019你那GDP 3543亿美元,增长4.7%
人均收入:10460美元,仅次于新加坡
年龄结构:30岁以下年轻人占人口53%
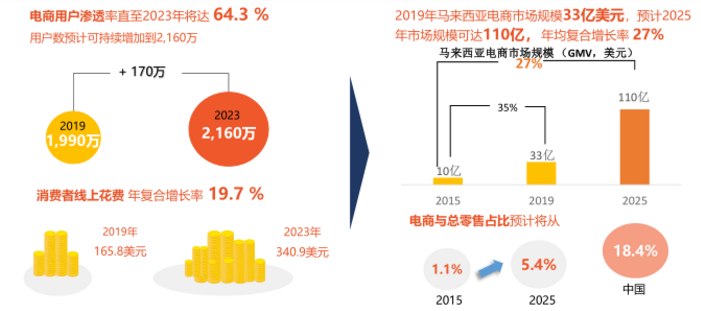
电商市场规模与潜力:
马来西亚电商用户数量及线上花费持续增加,推动电商市场规模持续扩大,年复合增长达21%
电商相关设施和政策:
马来西亚政府为推动电子商务增长制定一系列支持措施,以推动电商基础设施建设

跨境关税方面,对跨境电商商品仅征收进口税,政策优惠
主要征收两种税收:
(1)进口税
(2)SST(服务与消费税)
**对跨境电商商品仅征收进口税,不收取SST。政府设立的保税区也吸引了各大电商平台入驻。
注:马来西亚个人包裹海关免税额为500MYR,包裹货值如果超过此额度将会按品类被海关额外征税。
物流方面,马来西亚在东南亚国家中,物流效率与清关效率高于平均水平
总体情况:根据世界银行发布《2018年全球物流绩效指数》,从基础设施,服务,跨境程序与时间,供应链能力等方面进行评估,马来西亚效率高于东南亚平均水平;
跨境物流可使用shopee自有渠道SLS:
使用SLS时效:从转运仓发货到送达顾客,吉隆坡、马六甲区域平均6.5天到达,最快5天可到达;配送费用:低于市场价格30%;
SLS时效以及禁运产品
1、以下产品目前暂时不可以通过SLS渠道运输:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1879
1879

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









