







 本文介绍了一个Python爬虫项目,详细讲解如何获取并保存网站图片。首先从百度图片获取图片url链接,通过观察和分析参数,确定翻页和图片数量限制。接着,利用正则表达式抓取objURL,再用Python代码将图片下载到本地。提供了核心代码段和使用说明。
本文介绍了一个Python爬虫项目,详细讲解如何获取并保存网站图片。首先从百度图片获取图片url链接,通过观察和分析参数,确定翻页和图片数量限制。接着,利用正则表达式抓取objURL,再用Python代码将图片下载到本地。提供了核心代码段和使用说明。
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
PS:如有需要Python学习资料的小伙伴可以加入自行获取
1.获取图片的url链接
首先,打开百度图片首页,注意下图url中的index
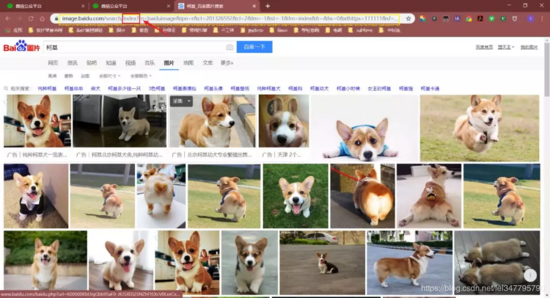
接着,把页面切换成传统翻页版(flip),因为这样有利于我们爬取图片!

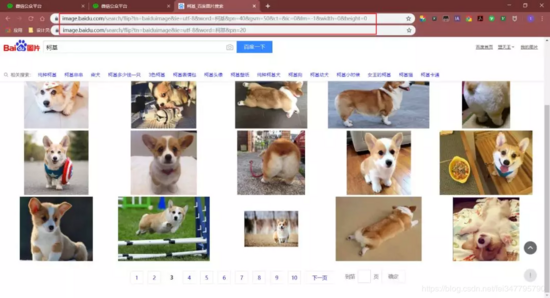
对比了几个url发现,pn参数是请求到的数量。通过修改pn参数,观察返回的数据,发现每页最多只能是60个图片。
注:gsm参数是pn参数的16进制表达,去掉无妨
然后,右键检查网页源代码,直接(ctrl+F)搜索 objURL
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









