




 本文介绍了FocalSelf-Attention(FSA)机制,旨在解决Transformer在高分辨率视觉任务中的计算复杂度问题。FSA通过细粒度关注临近信息和粗粒度关注远处信息,有效捕获局部和全局关系。实验表明,FocalTransformer在分类、检测和分割任务上表现出优越性能,同时通过消融实验验证了不同窗口大小、信息交互方式等对模型性能的影响。
本文介绍了FocalSelf-Attention(FSA)机制,旨在解决Transformer在高分辨率视觉任务中的计算复杂度问题。FSA通过细粒度关注临近信息和粗粒度关注远处信息,有效捕获局部和全局关系。实验表明,FocalTransformer在分类、检测和分割任务上表现出优越性能,同时通过消融实验验证了不同窗口大小、信息交互方式等对模型性能的影响。
作者丨小马
编辑丨极市平台
写在前面
VIsion Transformer(ViT)和它的一系列变种结构在CV任务中取得了不错的成绩,在其中,Self-Attention(SA)强大的建模能力起到了很大的作用。但是SA的计算复杂度是和输入数据的大小呈平方关系的,所以针对一些需要高分辨率的CV任务(e.g., 检测、分割),计算开销就会很大。 目前的一些工作用了局部注意力去捕获细粒度的信息,用全局注意力去捕获粗粒度的信息,但这种操作对原始SA建模能力的影响,会导致sub-optimal的问题。因此,本文提出了Focal Self-Attention(FSA),以细粒度的方式关注离自己近的token,以粗粒度的方式关注离自己远的token,以此来更有效的捕获short-range和long-range的关系。基于FSA,作者提出了Focal Transformer,并在分类、检测、分割任务上都验证了结构的有效性。
1. 论文和代码地址
Focal Self-attention for Local-Global Interactions in Vision Transformers
论文地址:https://arxiv.org/abs/2107.00641
代码地址:未开源
核心代码:后期会复现在https://github.com/xmu-xiaoma666/External-Attention-pytorch
2. Motivation
目前,Transformer结构在CV和NLP领域都展现出了潜力。相比于CNN,Transformer结构最大的不同就是它的Self-Attention(SA)能够进行依赖内容的全局交互(global content-dependent interaction),使得Transformer能够捕获long-range和local-range的关系。
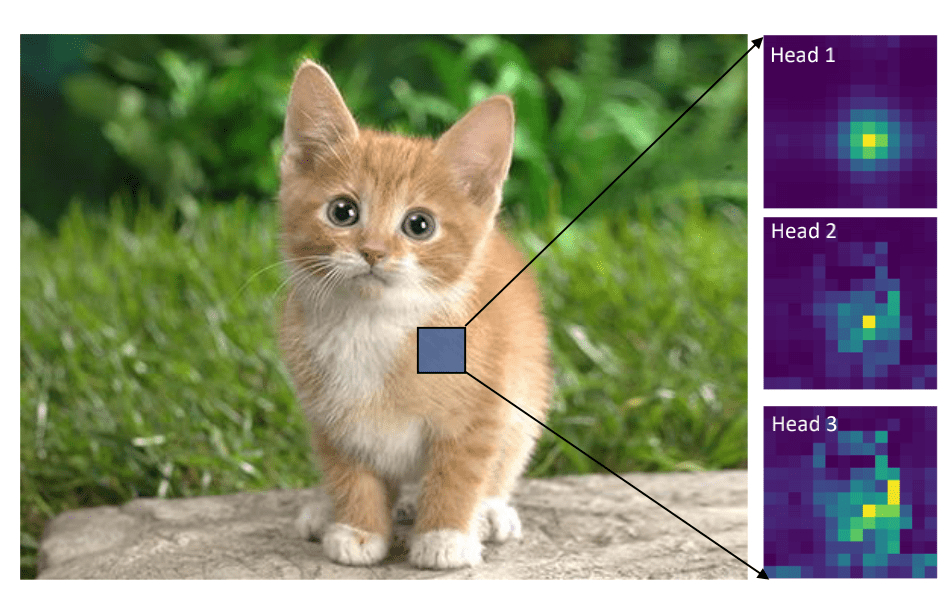
上图是DeiT-Tiny的attention可视化,可以看出,SA不仅能够像CNN那样关注局部区域,还能进行全局信息的感知。然而Transformer的计算量与输入数据的大小呈平方关系,因此对于检测、分割任务来说是非常不友好的。
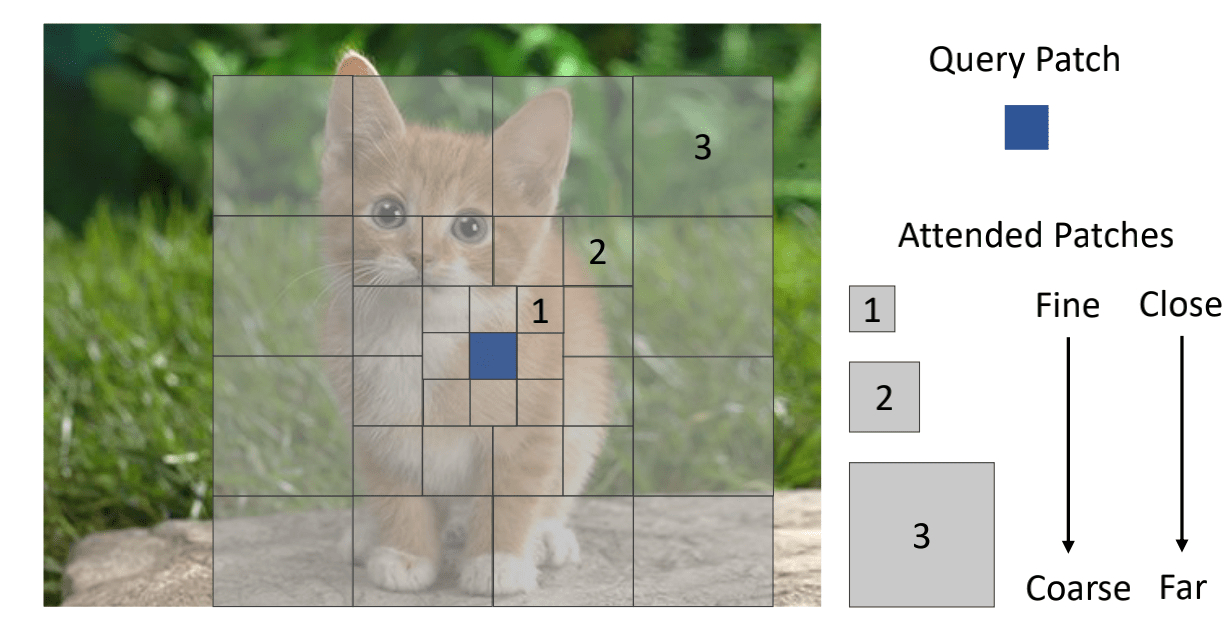
因此,本文提出了一个Focal Self-Attention(FSA),如上图所示,对当前token周围的区域进行细粒度的关注,对离当前token较远的区域进行粗粒度的关注,用这样的方式来更加有效的捕获局部和全局的注意力。基于FSA,本文提出了Focal Transformer,并在多个任务上进行了实验,取得了SOTA的性能。
3. 方法
3.1. 模型结构
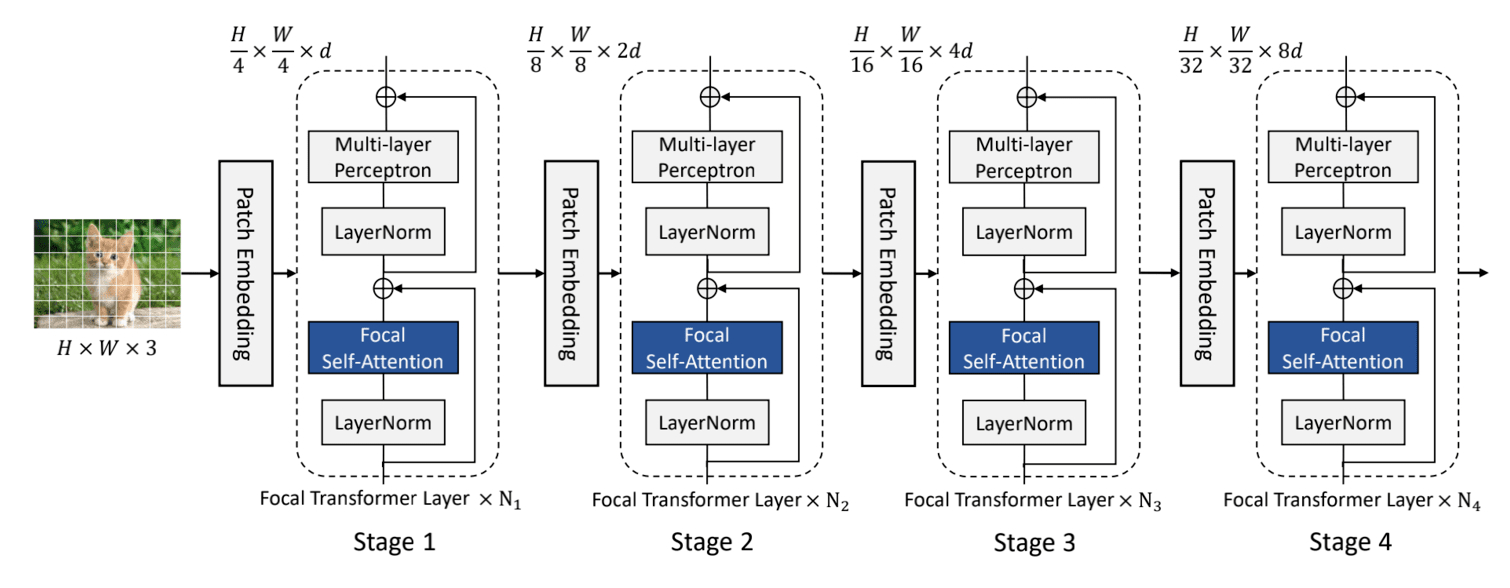
本文的模型结构如上图所示,首先将图片分成4x4的patch。然后进入Patch Embedding层,Patch Embedding层为卷积核和步长都为4的卷积。在进入N个Focal Transformer层,在每个stage中,特征的大小减半,通道维度变为原来的两倍。如果采用SA,由于这里指将图片缩小了四倍,因此第一层Transformer layer的SA计算复杂度为O((H/4×W/4)2d)O((H/4 \times W/4)^2 d)O((H/4×W/4)2d),这一步是非常耗时、耗显存的。
那么,应该采用什么样的办法来减少计算量呢?原始的SA将query token和其他所有token都进行了相似度的计算,因为无差别的计算了所有token的相似度,导致这一步是非常耗时、耗显存的。但其实,对于图片的某一个点,与这个点的信息最相关的事这个点周围的信息,距离越远,这个关系应该就越小。所以作者就提出了,对于这个点周围的信息进行细粒度的关注,距离这个点越远,关注也就越粗粒度。(个人觉得这一点其实跟人眼观察的效应很像,当我们看一件物体的,我
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 818
818

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









