







1、IO是什么
操作系统的IO:操作系统负责计算机的资源管理和进程的调度。我们电脑上跑着的应用程序,其实是需要经过操作系统,才能做一些特殊操作,如磁盘文件读写、内存的读写等等。因为这些都是比较危险的操作,不可以由应用程序乱来,只能交给底层操作系统来。也就是说,你的应用程序要把数据写入磁盘,只能通过调用操作系统开放出来的API来操作。
我们应用程序是跑在用户空间的,它不存在实质的IO过程,真正的IO是在操作系统执行的。即应用程序的IO操作分为两种动作:IO调用和IO执行。
- IO调用是由进程(应用程序的运行态)发起;
- IO执行是操作系统内核的工作。
此时所说的IO是应用程序对操作系统IO功能的一次触发,即IO调用。
什么是用户空间?什么是内核空间?
- 为了避免用户进程直接操作内核,保证内核安全,操作系统将内存(虚拟内存)划分为两部分,一部分是内核空间(Kernel- Space),另一部分是用户空间(User-Space)。
在Linux系统中,内核模块运行在内核空间,对应的进程处于内核态,是受保护的内存空间;用户程序运行在用户空间,对应的进程处于用户态,是用户应用程序访问的内存区域。每个应用程序进程都有一个单独的用户空间,对应的进程处于用户态,用户态进程不能访问内核空间中的数据,也不能直接调用内核函数,因此需要将进程切换到内核态才能进行系统调用。
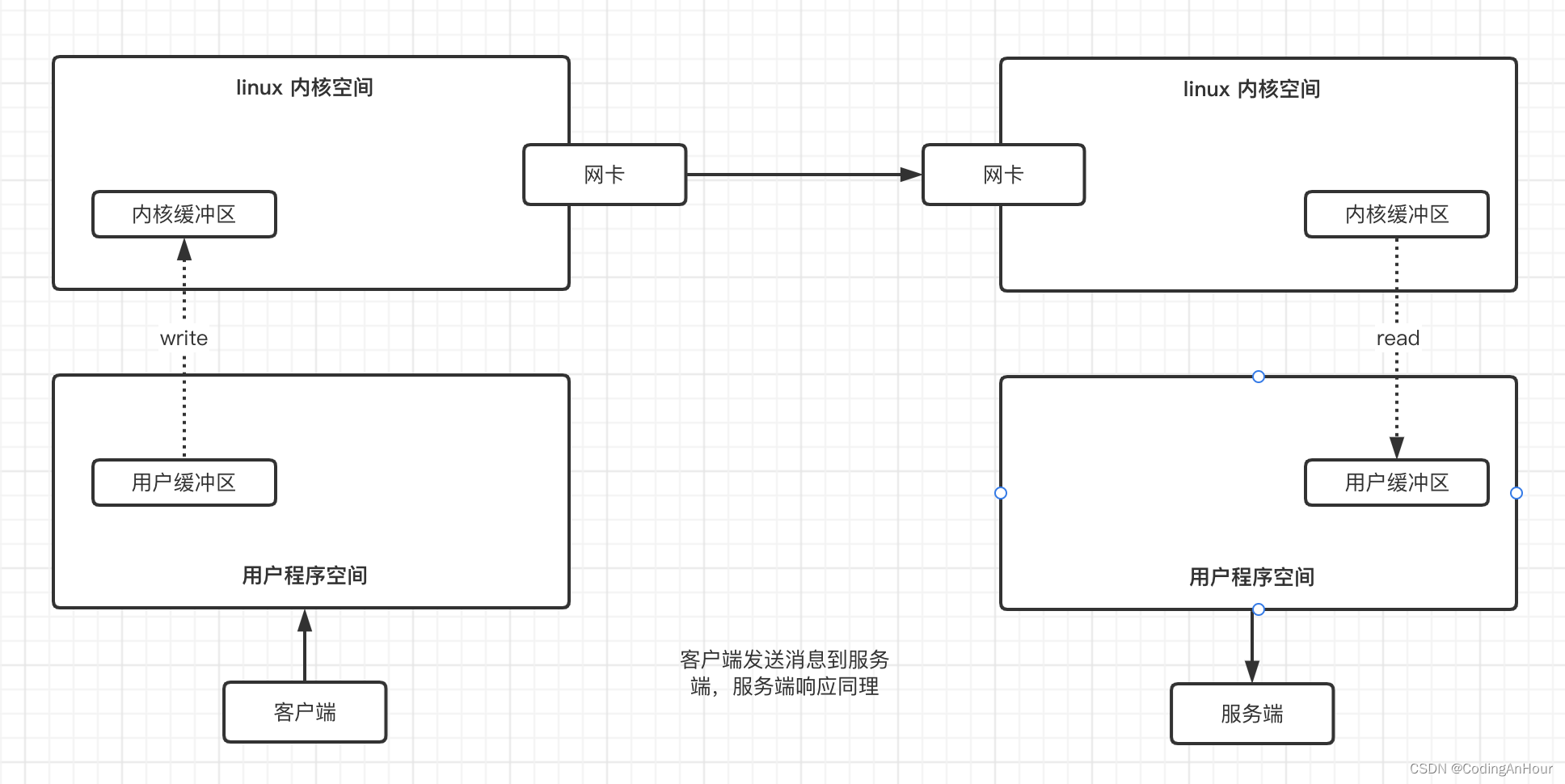
用户程序进行IO的读写依赖于底层的IO读写(read和write两大系统调用)操作系统层面的read系统调用并不是直接从物理设备把数据读取到应用的内存中,write系统调用也不是直接把数据写入物理设备。上层应用无论是调用操作系统的read还是调用操作系统的write,都会涉及缓冲区。上层应用通过操作系统的read系统调用把数据从内核缓冲区复制到应用程序的进程缓冲区,通过操作系统的write系统调用把数据从应用程序的进程缓冲区复制到操作系统的内核缓冲区。
简单来说,应用程序的IO操作实际上不是物理设备级别的读写, 而是缓存的复制。read和write两大系统调用都不负责数据在内核缓冲区和物理设备(如磁盘、网卡等)之间的交换。这个底层的读写交换操作是由操作系统内核(Kernel)来完成的。所以,在应用程序中, 无论是对socket的IO操作还是对文件的IO操作,都属于上层应用的开发,都是在内核缓冲区和进程缓冲区之间进行数据交换。
用户程序所使用的系统调用read和write是应用的用户缓冲区和内核缓冲区的数据交换;
- read调用把数据从内核缓冲区复制到应用的用户缓冲区
- write调用把数据从应用的用户缓冲区复制到内核缓冲区
缓冲区的目的是减少与设备之间的频繁物理交换(减少系统中断带来的时间及性能损耗)
1.1 Java客户端和服务端之间调用过程
Java客户端和服务端之间完成一次socket 请求和响应(包括read和write)的数据交换,其完整的流程如下:
-
客户端发送请求:Java客户端程序通过
write系统调用将数据复制到内核缓冲区,Linux将内核缓冲区的请求数据通过客户端机器的网卡发送出去。在服务端,这份请求数据会从接收网卡中读取到服务端机器的内核缓冲区。 -
服务端获取请求:Java服务端程序通过read系统调用从
Linux内核缓冲区读取数据,再送入Java进程缓冲区。 -
服务端业务处理:Java服务器在自己的
用户空间中完成客户端的请求所对应的业务处理。 -
服务端返回数据:Java服务器完成处理后,构建好的响应数据将
从用户缓冲区写入内核缓冲区,这里用到的是write系统调用,操作系统会负责将内核缓冲区的数据发送出去。 -
发送给客户端:服务端Linux系统将
内核缓冲区中的数据写入网卡,网卡通过底层的通信协议将数据发送给目标客户端。
2、同步阻塞IO(Blocking IO)
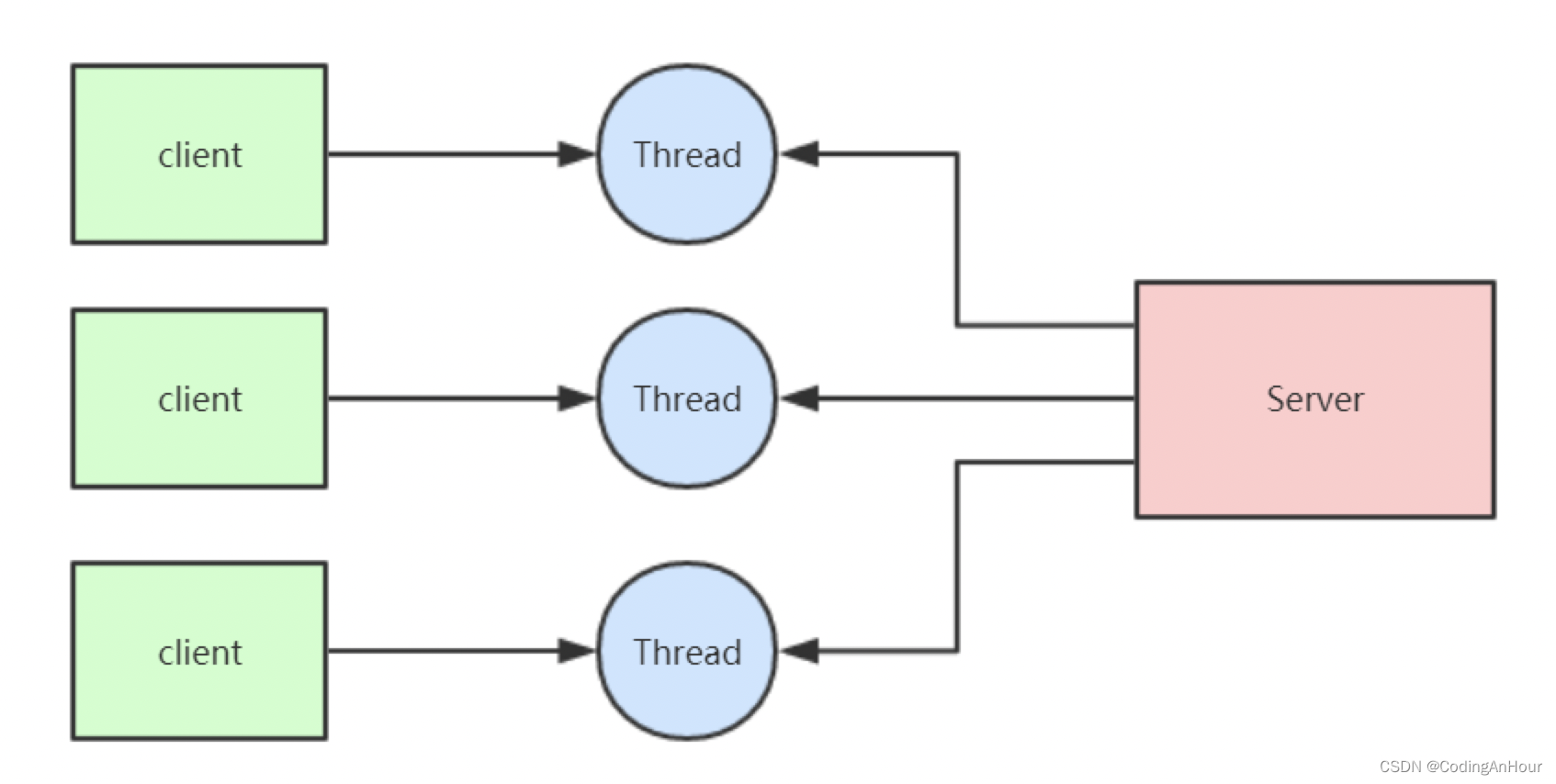
阻塞IO指的是需要内核IO操作彻底完成后才返回到用户空间执行用户程序的操作指令。“阻塞”指的是用户程序(发起IO请求的进程或者线程)的执行状态。可以说传统的IO模型都是阻塞IO模型,并且在Java中默认创建的socket都属于阻塞IO模型。
同步阻塞IO(Blocking IO)指的是用户空间(或者线程)主动发起,需要等待内核IO操作彻底完成后才返回到用户空间的IO操作。在IO操作过程中,发起IO请求的用户进程(或者线程)处于阻塞状态。
一个客户端连接对应一个处理线程
public class BIODemo {
public static void main(String[] args) throws IOException {
ServerSocket serverSocket = new ServerSocket(9000);
while (true) {
System.out.println("等待连接。。");
//阻塞方法
Socket clientSocket = serverSocket.accept();
System.out.println("有客户端连接了。。");
handler(clientSocket);
/*new Thread(new Runnable() {
@Override
public void run() {
try {
handler(clientSocket);
} catch (IOException e) {
e.printStackTrace();
}
}
}).start();*/
}
}
private static void handler(Socket clientSocket) throws IOException {
byte[] bytes = new byte[1024];
System.out.println("准备read。。");
//接收客户端的数据,阻塞方法,没有数据可读时就阻塞
int read = clientSocket.getInputStream().read(bytes);
System.out.println("read完毕。。");
if (read != -1) {
System.out.println("接收到客户端的数据:" + new String(bytes, 0, read));
}
clientSocket.getOutputStream().write("HelloClient".getBytes());
clientSocket.getOutputStream().flush();
}
}
代码控制台输出
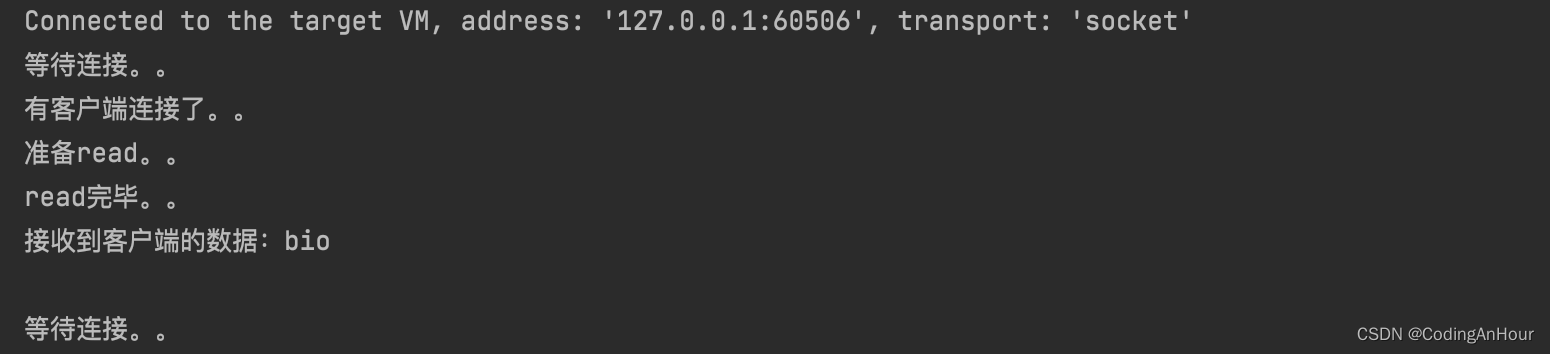
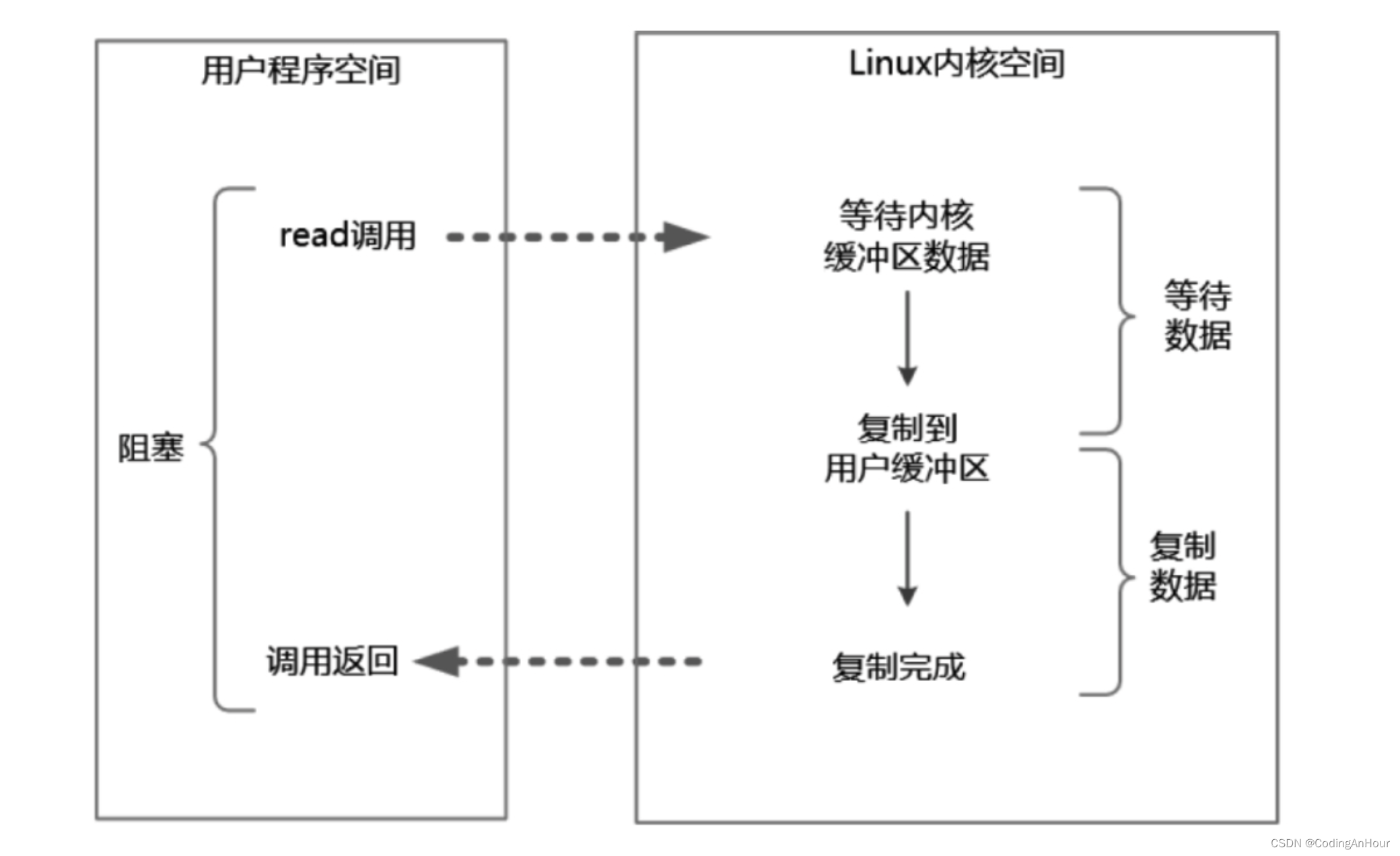
- 从Java进行IO读后发起read系统调用开始,用户线程(或者线程)就进入阻塞状态。
- 当系统内核收到read系统调用后就开始准备数据。一开始,数据可能还没有到达内核缓冲区(例如,还没有收到一个完整的socket数据包),这时内核就要等待。
- 内核一直等到完整的数据到达,就会将数据从内核缓冲区复 制到用户缓冲区(用户空间的内存),然后内核返回结果(例如返回复制到用户缓冲区中的字节数)。
- 直到内核返回后用户线程才会解除阻塞的状态,重新运行起来。
缺点:
5. IO代码里read操作是阻塞操作,如果连接不做数据读写操作会导致线程阻塞,浪费资源
6. 如果线程很多,会导致服务器线程太多,压力太大,比如C10K问题
应用场景:
BIO 方式适用于连接数目比较小且固定的架构, 这种方式对服务器资源要求比较高, 但程序简单易理解。
3、NIO
Java编程中的NIO类库组件所归属的不是基础IO模型中的NIO模型,而是IO多路复用模型。
为了提高性能,操作系统引入了一种新的系统调用,专门用于查询IO文件描述符(含socket连接)的就绪状态。在Linux系统中,新的系统调用为select/epoll系统调用。通过该系统调用,一个用户进程 (或者线程)可以监视多个文件描述符,一旦某个描述符就绪(一般是内核缓冲区可读/可写),内核就能够将文件描述符的就绪状态返回给用户进程(或者线程),用户空间可以根据文件描述符的就绪状态 进行相应的IO系统调用。异步阻塞IO。Java中的Selector属于这种模型。
public class NIODemo {
public static void main(String[] args) throws IOException, InterruptedException {
// 创建NIO ServerSocketChannel
ServerSocketChannel serverSocket = ServerSocketChannel.open();
serverSocket.socket().bind(new InetSocketAddress(9000));
// 设置ServerSocketChannel为非阻塞
serverSocket.configureBlocking(false);
// 打开Selector处理Channel,即创建epoll
Selector selector = Selector.open();
// 把ServerSocketChannel注册到selector上,并且selector对客户端accept连接操作感兴趣
serverSocket.register(selector, SelectionKey.OP_ACCEPT);
System.out.println("服务启动成功");
while (true) {
// 阻塞等待需要处理的事件发生
selector.select();
// 获取selector中注册的全部事件的 SelectionKey 实例
Set<SelectionKey> selectionKeys = selector.selectedKeys();
Iterator<SelectionKey> iterator = selectionKeys.iterator();
// 遍历SelectionKey对事件进行处理
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
// 如果是OP_ACCEPT事件,则进行连接获取和事件注册
if (key.isAcceptable()) {
ServerSocketChannel server = (ServerSocketChannel) key.channel();
SocketChannel socketChannel = server.accept();
socketChannel.configureBlocking(false);
// 这里只注册了读事件,如果需要给客户端发送数据可以注册写事件
socketChannel.register(selector, SelectionKey.OP_READ);
System.out.println("客户端连接成功");
} else if (key.isReadable()) {
// 如果是OP_READ事件,则进行读取和打印
SocketChannel socketChannel = (SocketChannel) key.channel();
ByteBuffer byteBuffer = ByteBuffer.allocate(128);
int len = socketChannel.read(byteBuffer);
// 如果有数据,把数据打印出来
if (len > 0) {
System.out.println("接收到消息:" + new String(byteBuffer.array()));
} else if (len == -1) {
// 如果客户端断开连接,关闭Socket
System.out.println("客户端断开连接");
socketChannel.close();
}
}
//从事件集合里删除本次处理的key,防止下次select重复处理
iterator.remove();
}
}
}
}
可以查看openjdk liux代码
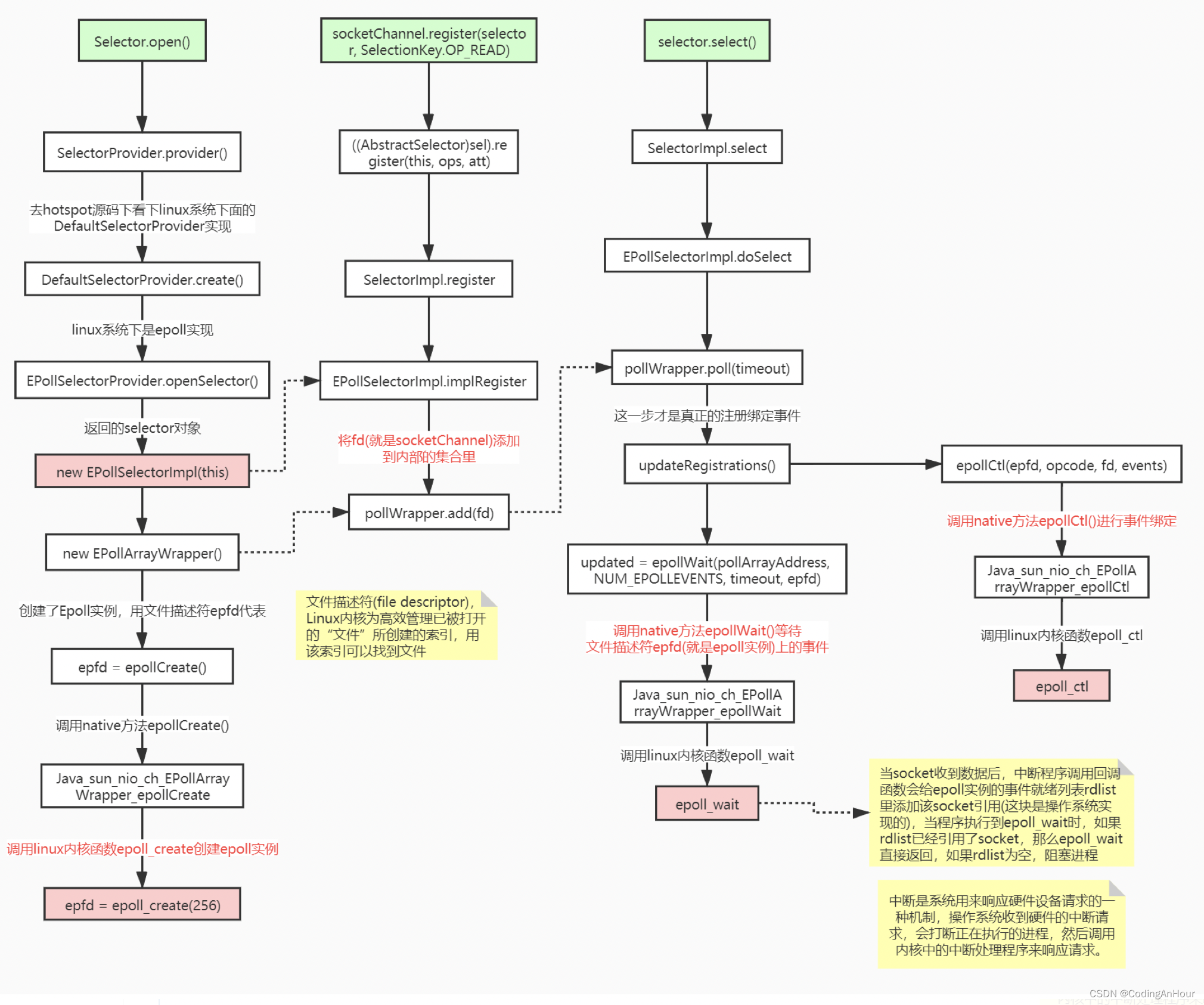
NIO整个调用流程就是Java调用了操作系统的内核函数来创建Socket,获取到Socket的文件描述符,再创建一个Selector对象,对应操作系统的Epoll描述符,将获取到的Socket连接的文件描述符的事件绑定到Selector对应的Epoll文件描述符上,进行事件的异步通知,这样就实现了使用一条线程,并且不需要太多的无效的遍历,将事件处理交给了操作系统内核(操作系统中断程序实现),大大提高了效率。
IO多路复用模型的流程。发起一个多路复用IO的 read操作的系统调用,流程如下:
- 选择器注册。首先,将需要read操作的目标文件描述符 (socket连接)提前注册到Linux的select/epoll选择器中,在Java中所对应的选择器类是Selector类。然后,开启整个IO多路复用模型的轮询流程。
- 就绪状态的轮询。通过选择器的查询方法,查询所有提前注册过的目标文件描述符(socket连接)的IO就绪状态。通过查询的系统调用,内核会返回一个就绪的socket列表。当任何一个注册过的 socket中的数据准备好或者就绪了就说明内核缓冲区有数据了,内核将该socket加入就绪的列表中,并且返回就绪事件。
- 用户线程获得了就绪状态的列表后,根据其中的socket连接 发起read系统调用,用户线程阻塞。内核开始复制数据,将数据从内 核缓冲区复制到用户缓冲区。
- 复制完成后,内核返回结果,用户线程才会解除阻塞的状态,用户线程读取到了数据,继续执行。
Netty框架使用的就是IO多路复用模型
4、异步IO(AIO)
异步IO模型的基本流程是:用户线程通过系统调用向内核注册某个IO操作。内核在整个IO操作(包括数据准备、数据复制)完成后通知用户程序,用户执行后续的业务操作。
在异步IO模型中,在整个内核的数据处理过程(包括内核将数据从网络物理设备(网卡)读取到内核缓冲区、将内核缓冲区的数据复制到用户缓冲区)中,用户程序都不需要阻塞。
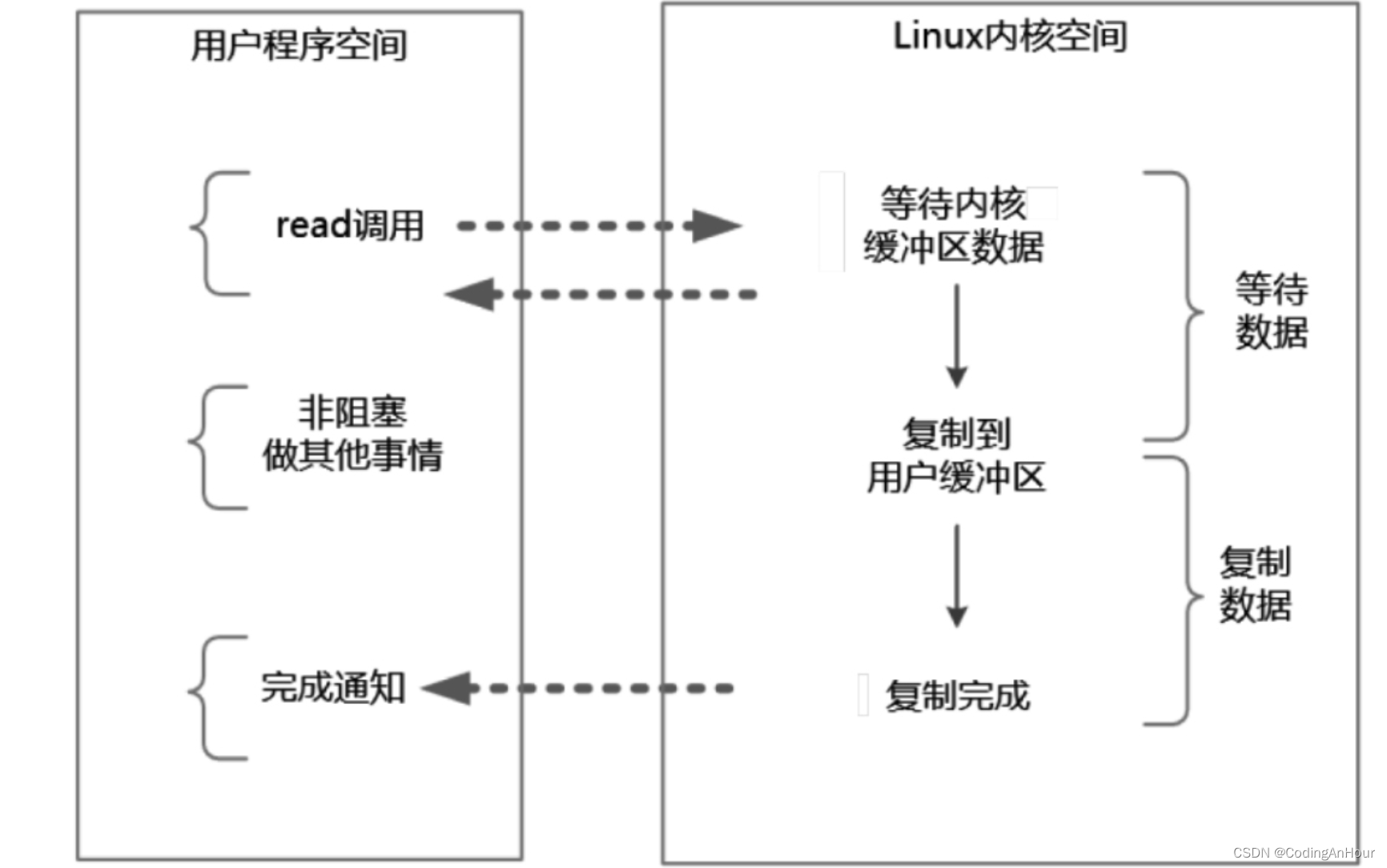
在Linux系统下,异步IO模型在2.6版本才引入,JDK对它的支持目前并不完善,因此异步IO在性能上没有明显的优势。
public class AIODemo {
public static void main(String[] args) throws Exception {
final AsynchronousServerSocketChannel serverChannel =
AsynchronousServerSocketChannel.open().bind(new InetSocketAddress(9000));
serverChannel.accept(null, new CompletionHandler<AsynchronousSocketChannel, Object>() {
@Override
public void completed(AsynchronousSocketChannel socketChannel, Object attachment) {
try {
System.out.println("2--"+Thread.currentThread().getName());
// 再此接收客户端连接,如果不写这行代码后面的客户端连接连不上服务端
serverChannel.accept(attachment, this);
System.out.println(socketChannel.getRemoteAddress());
ByteBuffer buffer = ByteBuffer.allocate(1024);
socketChannel.read(buffer, buffer, new CompletionHandler<Integer, ByteBuffer>() {
@Override
public void completed(Integer result, ByteBuffer buffer) {
System.out.println("3--"+Thread.currentThread().getName());
buffer.flip();
System.out.println(new String(buffer.array(), 0, result));
socketChannel.write(ByteBuffer.wrap("HelloClient".getBytes()));
}
@Override
public void failed(Throwable exc, ByteBuffer buffer) {
exc.printStackTrace();
}
});
} catch (IOException e) {
e.printStackTrace();
}
}
@Override
public void failed(Throwable exc, Object attachment) {
exc.printStackTrace();
}
});
System.out.println("1--"+Thread.currentThread().getName());
Thread.sleep(Integer.MAX_VALUE);
}
}
5、Linux操作系统中文件句柄数的限制
一般生产环境Linux系统中,高并发场景基本上都需要解除文件句柄数的限制。原因是 Linux系统的默认值为1024,也就是说,一个进程最多可以接受1024个socket连接。
当单个进程打开的文件句柄数量超过了系统配置的上限值时会发出“Socket/File:Can’t open so many files”的错误提示。
可以通过ulimit来设置这个参数
ulimit -n 1000000
使用ulimit命令有一个缺陷,即该命令只能修改当前用户环境的 一些基础限制,仅在当前用户环境有效。也就是说,在当前的终端工 具连接当前shell期间,修改是有效的,一旦断开用户会话,或者说用 户退出Linux,它的数值就又变回系统默认的1024了。并且,系统重启后,句柄数量会恢复为默认值。
ulimit命令只能用于临时修改,如果想永久地把最大文件描述符 数量值保存下来,可以编辑/etc/rc.local开机启动文件,在文件中添 加如下内容:
ulimit -SHn 1000000
Linux系统的最大文件打开数量的限制,可以通过编辑 Linux的极限配置文件/etc/security/limits.conf来做到。修改此文 件,加入如下内容:
soft nofile 1000000
hard nofile 1000000
在使用和安装目前非常流行的分布式搜索引擎ElasticSearch时,必须修改这个文件,以增加最大的文件描述符的极限值。当然,在生产环境运行Netty时,也需要修 改/etc/security/limits.conf文件来增加文件描述符数量的极限值。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









