






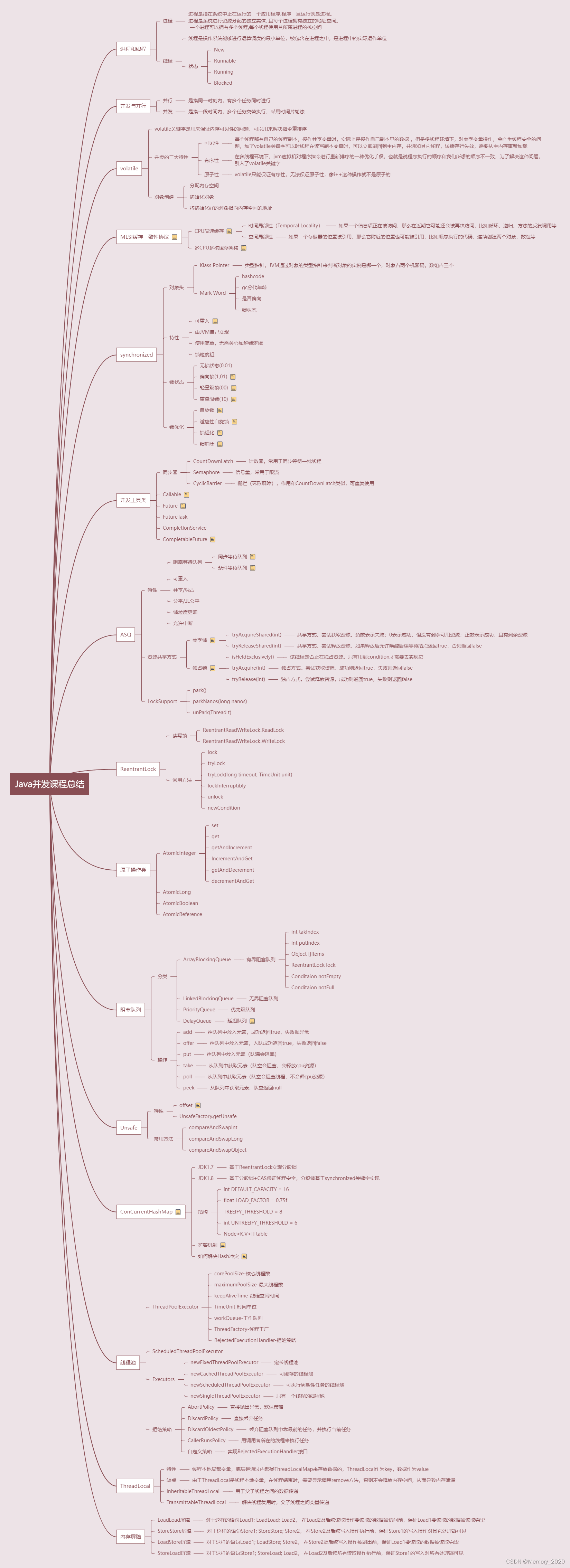
多线程的三大特性
可见性、原子性、有序性
线程同步的几种方式
Synchronized
可重入,底层采用对象的ObjectMonitor机制,来记录锁,底层通过monitorenter和monitorexit指令来保证同步。
每个对象都会有一个ObjectMonitor
java对象头和monitor是实现synchronized的基础。
对象头
synchronized用的锁是存在java对象头里的,hotspot虚拟机的对象头主要包括两部分,Mark Word(标记字段)和Klass Pointer(类型指针)。其中Klass point是对象指向它的类元数据的指针,虚拟机通过这个指针确定对象是哪个类的实例,Mark Word用于存储对象自身的运行时数据,它是实现轻量级锁和偏向锁的关键。
Mark Word
Mark Word用于存储对象自身的运行时数据,如哈希码、GC分带年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等。java对象头一般占用两个机器码(在32位虚拟机中,1个机器码等于4字节,也就是32bit),但如果对象是数组类型,则需要三个机器码,因为在数组中,jvm 可以通过java对象的元数据知道对象的大小,但是无法从数组的原数据来确认数组的大小,所以用一块来记录数组长度。
锁主要存在的四种状态
无锁状态->偏向锁状态->轻量级锁状态->重量级锁状态,锁升级是指从无锁状态到重量级锁状态,过程是不可逆的,也就是无法降级
锁优化
自旋锁
线程的阻塞和唤醒需要cpu从用户态转换为内核态,频繁的阻塞和唤醒对CPU来说也是一种很大的开销,但是对象锁的锁状态一般只会持续很短一段时间,为了这一段很短的时间,频繁的阻塞和唤醒线程是非常不值得的,所以引入了自旋锁。所谓自旋锁,就是让线程等待一段时间,不会立即挂起,看持有锁的线程能否很快释放锁,如何自旋呢,执行一段无意义的循环即可(自旋)。自旋等待不能代替阻塞,当大量线程都对同一共享资源进行访问时,自旋操作可能会引发饥饿锁的问题,它一直占用cpu资源,空循环,不会释放资源导致cpu空转,该得到的资源一直无法得到,所以时间长了会造成锁饥饿的问题。
所以,自旋锁适用于很少有并发竞争的场景下。
适应性自旋锁
为了避免自旋锁带来的额外开销,对自旋锁进行的一种优化,就是在多线程情况下,产生锁竞争的时候,减少自旋的时间和次数,比如第一次获取锁时,先自旋10次,如果10次还没有获取到锁,则进行阻塞,等待下一次的自旋,自旋的次数会根据上次获取锁的情况进行自适应,如果上次立即获取到锁了,程序认为这一次也会立即获取到锁,所以自旋次数会增多,如果很少有自旋获取成功的锁,下一次自旋次数会减少,甚至忽略掉自旋的过程。
锁消除
为了保证数据的完整性,我们在进行操作时会对这部分数据进行同步控制,但有些情况下,JVM检测到不可能存在共享数据竞争,这时JVM会对这些同步加锁操作进行锁消除。当我们在写程序的时候,知道不会存在共享数据竞争的问题,但有些时候,我们使用java提供的api的时候,底层有时会使用加锁操作,这个时候,JVM会对其进行优化,去掉锁操作,减少请求锁的时间。
锁粗化
所谓锁粗化,就是连续的进行加锁解锁操作,可能会导致不必要的性能损耗,JVM检测到对同一对象的连续加锁、解锁操作,会合并一个更大范围的加锁、解锁操作,即加解锁的操作放到for循环之外。
偏向锁
引入偏向锁的主要目的是为了在无多线程竞争的情况下尽量减少轻量级锁的执行逻辑。
获取锁:
1.检测Mark Word是否为可偏向状态,即是否是偏向锁1,锁标识位为01。
2.若为可偏向状态,检测线程id是否为当前线程id,如果是执行步骤5,否则执行步骤3。
3.如果线程id不是当前线程id,则通过CAS操作竞争锁,获取成功,将Mark Word的线程id替换为当前线程,否则执行步骤4.
4.通过CAS获取锁失败,则证明当前存在多线程竞争情况,当到达安全点,获取偏向锁的线程被挂起,偏向锁升级为轻量级锁,然后被阻塞在安全点的线程继续向下执行同步代码块
5.执行代码块
释放锁
释放锁采用了一种只有竞争才会释放锁的机制,线程是不会主动去释放偏向锁,需要其他线程来竞争。偏向锁的撤销需要等待全局安全点。
1.暂停拥有偏向锁的线程,判断锁对象是否还处于锁定状态
2.撤销偏向锁,恢复到无锁状态(01) 或轻量级锁状态(00)
轻量级锁
引入轻量级锁的主要目的是在没有多线程竞争的前提下,减少传统的重量级锁使用操作系统互斥量产生的性能损耗。当关闭偏向锁,或者多个线程对偏向锁进行竞争,导致偏向锁升级为轻量级锁,则会尝试获取轻量级锁,获取锁的步骤如下;
获取锁:
1.判断当前对象是否处于无锁状态(hashcode 、0、 01),若是,则JVM会在当前线程栈帧中建立一个名为锁记录(Lock Record)的空间,用于存储当前锁对象的Mark Word的的拷贝;否则执行步骤3
2.JVM利用CAS操作尝试将对象的Mark Word更新为指向Lock record的指针,如果成功,表示竞争到锁,将锁标志位变成00(表示轻量级锁),执行同步块,如果失败,执行步骤3
3.判断当前对象的Mark word是否指向当前线程的栈帧,如果是则表示当前线程已经持有当前对象的锁,则直接执行同步块;如果否表示当前的对象锁已被其他线程抢占了,则轻量级锁会膨胀为重量级锁,锁标志变为10,后面等待的线程进入阻塞状态
释放锁,轻量级锁的释放也是通过CAS操作,其步骤如下:
1.取出获取轻量级锁保存在Displaced Mark Word中的数据。
2.用CAS操作将取出的数据替换当前对象的Mark Word中,如果成功, 表示释放锁成功,否则执行步骤3
3.如果CAS操作失败,说明有其他线程尝试获取该锁,则在释放锁的同时唤醒被挂起的线程。
重量级锁
重量级锁通过对象内部moniter对象来实现,其本质是调用操作系统 Mutex Lock来实现,操作系统实现线程之间的切换需要从用户态到内核态,切换成本非常高,所以称其为重量级锁
ReentrantLock
可重入,锁粒度更细,需要显示的声明获取锁和释放锁。
CountDownLatch
计数器,常用于同步等待一批资源的准备。
Semaphore
信号量,常用于限流的场景
CyclicBarrier
栅栏,功能和CountDownLatch类似,只不过是CyclicBarrier可以复用。
volatile底层原理
volatile只能保证内存可见性,无法保证i++这种操作的原子性,底层是通过lock前缀指令来保证缓存中的数据可以立即刷新到主内存。
我们知道每个线程都有自己的一块内存空间,这个空间是线程独有的,还有一块公共的内存空间,我们把它叫做主内存,当程序在读取一个共享变量的时候, 会先加载到自己的工作内存,对共享变量的操作实际上是对线程副本的操作,对其进行写数据时,计算机并不会立即将值写回主内存,而是先写会工作内存,而后由cpu自己写回主内存,这个写回时机是不确定的,所以在多线程情况下,对共享变量的操作会存在线程安全的问题,为了解决这种问题,我们可以在共享变量前加volatile关键字来保证内存的可见性,但是不能保证原子性。我们知道i++或++i实际上是有三步操作,1读取值,2做运算3.赋值 所以这种不是原子性操作
如何防止指令重排
什么是指令重排?
编译器或运行时环境为了优化程序性能而采取的对指令进行重新排序的一种手段,也就是说程序运行的顺序与我们所想的顺序是不一致的,虽然它遵循as-if-serial语义,但还是无法保证多线程环境下的数据安全
对象创建有三个步骤:
1.分配内存空间
2.初始化对象
3.将内存空间的地址复制给对应的引用
当上面的2、3进行重排序的时候,先执行3,再执行2,那么程序在读取对象时会出错(对象未初始化)
加volatile关键字
使用内存屏障 Unsafe.unfence();
加同步锁也可以保证内存的可见性
ReentrantLock原理
使用cas+自旋
可重入
锁粒度小
AQS(Abstract Queue Synchronized 抽象队列同步器)
实现原理
底层是通过一个内部类Sync,来实现公平锁和非公平锁,
自己实现一把锁,只需要实现AbstractQueuedSynchronized接口,内部已经实现了入队,出队,阻塞等逻辑,只需要重写,tryAquire()和release方法。
公平锁
failSync()
非公平锁
nofailSync()
什么是锁膨胀,锁粗化、锁消除
什么是死锁
两个线程分别持有对方的锁,并且对对方的资源进行互相争抢
死锁的四个条件
1.互斥条件:一个资源每次只能被一个线程使用
2.不剥夺条件
3.请求与保持条件
4.循环等待条件
如何避免死锁
比如调用wait()方法让其中一个线程短暂的释放资源。
HashMap的实现原理
初始化容量:默认是4
负载因子(扩容因子):0.75
jdk1.7
数组+链表
数组扩容
采用头插法
在多线程情况下,会存在死锁,链表中的头节点的next元素和next节点的next元素为同 一个元素
jdk1.8
数组+链表+红黑树
数组扩容
采用尾插法
链表转红黑树
当链表的长度为8时,由链表转为红黑树
红黑树转链表
当红黑树的长度为6时,转回链表
如何减少hash碰撞
对key进行hash计算,获取到的值再进行位运算,均匀分布到链表的不同位置。
ConcurrentHashMap的实现原理
jdk1.7 桶锁
segement,
jdk1.8 分段锁
双链表,一个链表用来存
实现原理
底层采用数组、链表、红黑树,内部采用大量cas操作,并发控制使用synchronized和cas操作来来实现的
BlockingQueue的底层实现
有界阻塞队列,当队满时,插入元素会进行阻塞
线程池的分类,常用的参数
TheadFiexdExcutorPool
ThreadScheduledExcutortPool
ThreadSingleExcutrotPool
拒绝策略:
丢弃老的任务,新任务入队
如果队满,由提交任务的线程来执行这个提交的任务。
抛异常




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











