






 Year: 2024
Year: 2024
Conference: ACM MM
Address: https://doi.org/10.48550/arXiv.2310.06671
Introduction
知识图谱(Knowledge Graph, KG)以三元组(head entity, relation, tail entity)的形式表示和存储现实世界的知识信息。这种结构化的信息在许多AI领域都具有非常重要的作用,例如推荐系统、问题回答及异常检测等。然而对于知识图谱而言,无论是手动构建还是自动提取,都有一个缺点,那就是它们的范围仅限于观测到的知识,导致知识图谱的表示并不完整,缺少了大量的未知三元组。这种现象激发了知识图谱补全(Knowledge Graph Completion,KGC),其目的是预测缺失的三元组并进一步增强给定的知识图谱。
现有的KGC方法可以分为两类:基于嵌入表示的方法和基于预训练语言模型(Pre-trained Language Models, PLMs)的方法。一些基于LLM的KGC方法通过零样本推理(Zero-Shot Reasoning,ZSR)和指令微调(Instruction Tuning,IT)来完成KGC任务。然而这些方法是将KGC任务转换成独立三元组的文本预测任务,这样做会引起一些基础性问题。LLM缺乏对实际知识的深度和精确性,这往往导致LLM的幻觉问题。而且KG其结构复杂性,例如子图结构、关系模式、相关实体/关系通常被忽视。这种丰富的非文本结构化信息,如果能够通过合适的方式融入LLM,能够显著地增强LLM对KG的理解和表示。 结构信息对LLM的推理是至关重要的。然而,传统的ZSR和IT方法常常忽视这一点,因为每个输入通常只是一个输入三元组,可能会浪费KG中固有的结构信息,因此这种方法并不能让LLM理解KG的结构。
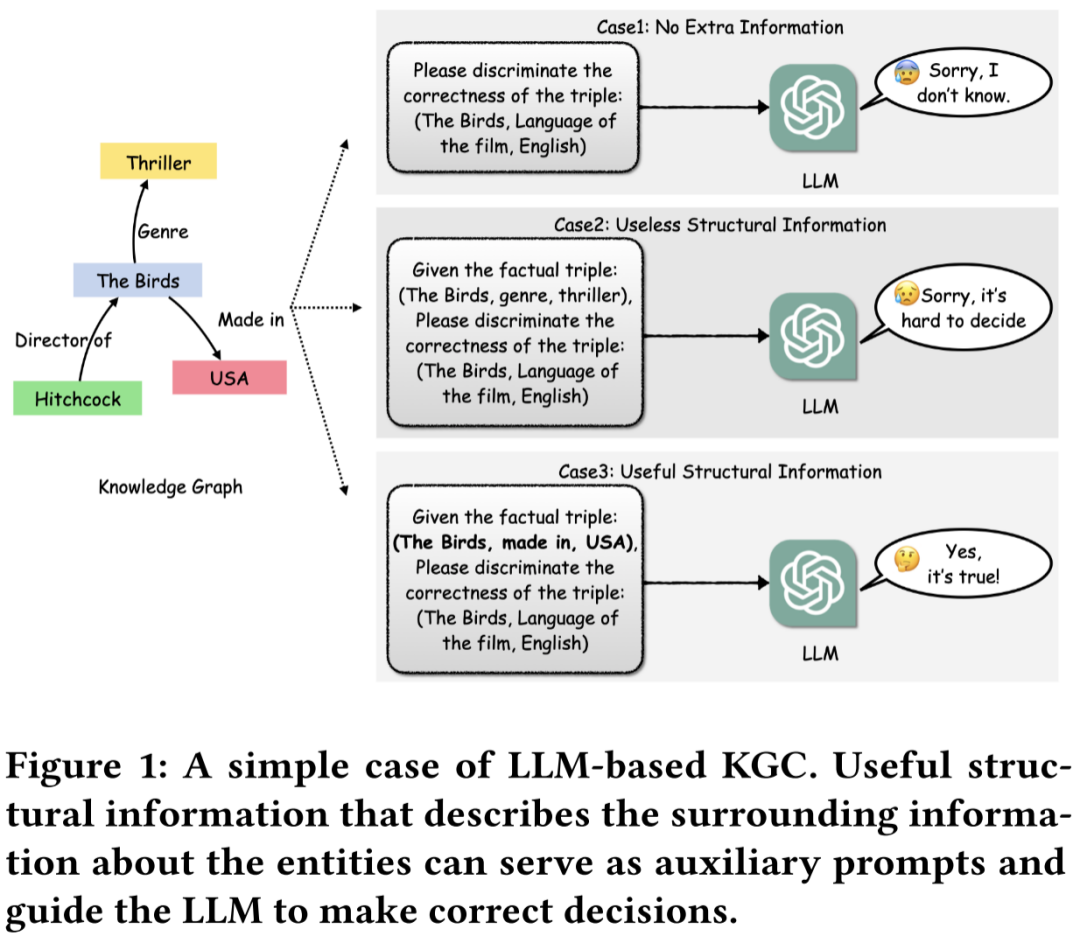
为了解决上述问题,本文在基于LLM的KGC方法上进一步探索,尝试将KG的结构信息融入大模型,实现结构感知推理。本文最初重点在于将现有的LLM范式,如上下文学习和指令微调转移到结构感知的上下文。本文提出了结构感知的上下文学习方法和指令调优方法作为基础模型,重点将KG的结构信息通过文本的形式集成到LLM中,这种方法得益于KG中存在关于实体和关系的特定文本信息,因此可以使用文本来表示这些知识,作为补充的背景信息,期望大型语言模型可以通过文本提示学习KG中的局部结构信息。但它们也有明显的缺点,即结构信息和文本信息之间存在明显的语义差异。扩展提示中的文本描述仍然不能充分利用复杂KG中的结构信息。
因此本文额外提出了一个全新的知识前缀适配器(Knowledge Prefix Adapter,KoPA),使LLM能够更好地进行知识推理,利用结构嵌入预训练来获取KG的结构信息。随后KoPA通过知识前缀适配器将结构嵌入转换为文本嵌入空间,得到若干虚拟知识词元。这些词元充当输入提示序列中的前缀,指导指令调优过程,提供有价值的补充输入三元组信息。这种结构嵌入到文本形式的映射为输入三元组提供了辅助信息。此外,本文进行了全面的分析和实验,突出了KoPA的卓越性能和可转移性。本文的贡献如下:
-
**Extending the existing LLM paradigms 扩展现有的大型语言模型范式。**本文是首次对基于LLM的KGC方法进行了广泛的研究,特别是通过结合KG结构信息来提高大型语言模型的推理能力,讨论如何使用额外的文本提示,使现有的大型语言模型范式(如ICL和IT)适应KGC的结构感知设置。
-
Designing new cross-modal LLM paradigm 设计新的跨模态大型语言模型范式。本文进一步提出了一种知识前缀适配器(KoPA),它有效地将预训练的KG结构嵌入与LLM集成在一起。KoPA促进了LLM的文本嵌入和KG的结构嵌入之间的全面跨模态交互,以提高大型语言模型的推理能力。
-
Comprehensive evaluation 综合评价。本文在三个公共基准上进行了广泛的实验,评估了提出的所有结构感知方法的KGC性能,并进行了充分的基准比较,进一步探索了迁移能力和知识保留程度。
Related Work
Knowledge Graph Completion
知识图谱补全任务是是KG领域的一个重要任务,即在给定KG中挖掘未观测过的三元组。KGC包含了三元组分类、实体预测等子任务。KGC任务的共同点是建立一个有效的机制来衡量三元组的合理性。主流的KGC方法可分为基于嵌入和基于预训练语言模型两大类。基于嵌入的方法旨在将KG的实体和关系嵌入到连续表示空间中。这些方法充分利用了KGs的结构信息,通过精心设计的评分函数对三元组合理性进行建模,并以自监督的方式学习实体/关系嵌入。此外,基于预训练语言模型的方法通过微调预训练的语言模型,将KGC视为基于文本的任务。这些简短的文本描述被组织成一个输入序列,并由语言模型编码。这类方法利用了语言模型的功能,但使训练过程变成了基于文本的学习,难以在KG中捕获复杂的结构信息。
LLMs for KG Research
近年来,LLM取得了快速进展,并在相当数量的文本相关任务中显示出强大的能力。LLM通常以自回归的方式预测下一个单词,并显示出强大的文本理解和生成能力。在LLM的研究课题中,LLM与KG的融合是一个热门而重要的课题。一方面,幻觉现象在大型语言模型中普遍存在,这意味着大型语言模型缺乏事实知识,不可解释。存储结构化知识的KG可以通过将事实性知识引入大型语言模型来缓解这种现象。另一方面,大型语言模型通过其强大的生成能力,可以使KGC、实体对齐和KGQA等与KG相关的任务受益。本文通过知识图谱补全任务从更系统的角度深入研究这个问题。
Incorporate Non-textual Modality Information into LLMs
由于LLM在文本生成方面展示了可扩展性,许多其他工作试图将非文本模式纳入其中,例如图像、视频等,被称为多模态LLMs,这些方法倾向于通过模态编码器对非文本信息进行编码,然后将其作为虚拟文本词元进行处理。通过对多模态数据集进行指令调优,将非文本标记与单词标记对齐。
上述多模态大型语言模型通常不包括图,这是另一种重要的数据模态。还有一些工作讨论了如何将图形数据合并到LLM中。其他工作探讨了如何通过将图结构信息转换为大型语言模型来解决节点分类和图分类等图学习任务。
本文探讨如何将KGs中的复杂结构信息整合到大型语言模型中,以获得更好的知识图谱补全推理能力。
Methodology
本文提出了KoPA将KG结构信息融入LLM来实现KGC任务,首先通过结构嵌入预训练提取KG中实体、关系的结构信息,随后采用一个结构前缀适配器,将这些结构信息送入LLM的输入序列中,最后LLM根据结构增强后的文本信息进行微调。
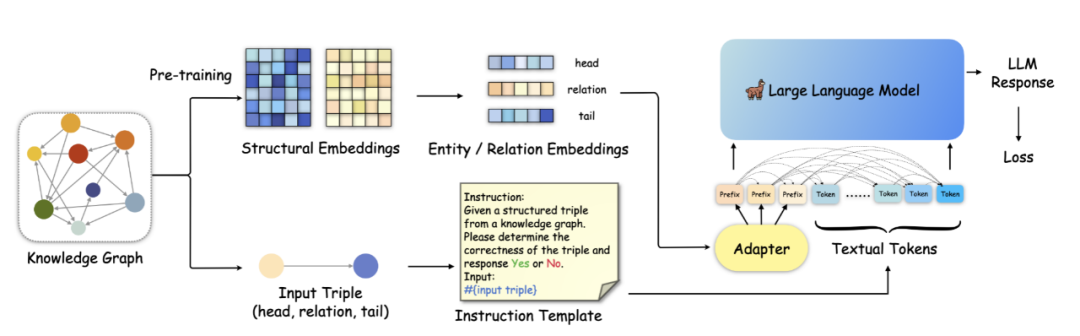
Structural Embedding Pre-training
KoPA通过自监督结构嵌入预训练提取实体和关系的结构信息,而不是在输入序列中添加关于邻域信息的文本。对于每个实体和每个关系,分别学习一个结构嵌入,,其中,为嵌入维数。在嵌入中对KG结构信息进行编码,并进一步将其调整到LLM的文本表示空间中。参考现有的基于嵌入的KGC范式,本文定义了一个评分函数来衡量三组的合理性。使用负采样的自监督预训练目标函数:
其中是边界,是sigmoid激活函数,为个对应的负样本。是自对抗的权重。
通过最小化这种预训练损失,优化每个实体和关系的结构嵌入以适应其所有相关三元组,从而在嵌入中捕获子图结构和关系模式等KG结构信息。这种方法已经在许多基于嵌入的KGC方法中被证明是有效的,可以捕获经典的结构信息,如关系模式和分布式实体表示。
Knowledge Prefix Adapter
经过结构嵌入预训练,可以得到三元组的结构嵌入。然而,结构嵌入表示与LLM 的文本表示不同,这意味着LLM 不能直接理解这些嵌入。因此,使用知识前缀适配器将它们投射到LLM 的文本表示空间中。具体来说,使用前缀适配器将结构嵌入转换为虚拟文本知识元:
在实践中,适配器将是一个简单的投影层。然后,将放在原始输入序列的前面,作为指令的前缀和三元组提示。这样,由于在LLM中只有解码器的单向注意力机制,因此在前缀后的所有文本标记都可以看到。这样做,文本标记可以单向地关注输入三元组的结构嵌入。这种结构感知提示将在微调和推理期间使用。在训练期间,我们冻结了预训练的结构嵌入。该适配器经过优化,可以学习从结构知识到文本表示的映射,并在推理阶段对新的三元组进行泛化,有利于文本描述,从另一个角度提供三元组信息,增强预测。
Complexity Analysis

在提出KoPA之后,本文对基于LLM的KGC方法进行了比较,以证明KoPA的优势,与基本范式(ZSR/ICL/IT)相比,KoPA将KG结构嵌入纳入LLM中,实现了文本信息和结构信息的结合。同时,KoPA使提示的长度更加精炼,因为由结构前缀适配器生成的虚拟token的长度固定为3,分别为头/关系/尾。相反,结构感知的指令调优IT的提示长度与邻域三元组𝑘的数量呈线性关系。不同于基于文本描述的融合结构信息的方法,KoPA通过适配器生成的固定长度的虚拟知识词元来实现这一目标。
Experiments
Experimental Settings
Datasets 数据集。本文采用三个公共基准数据集UMLS, CoDeX-S, FB15K-237N评估模型性能。
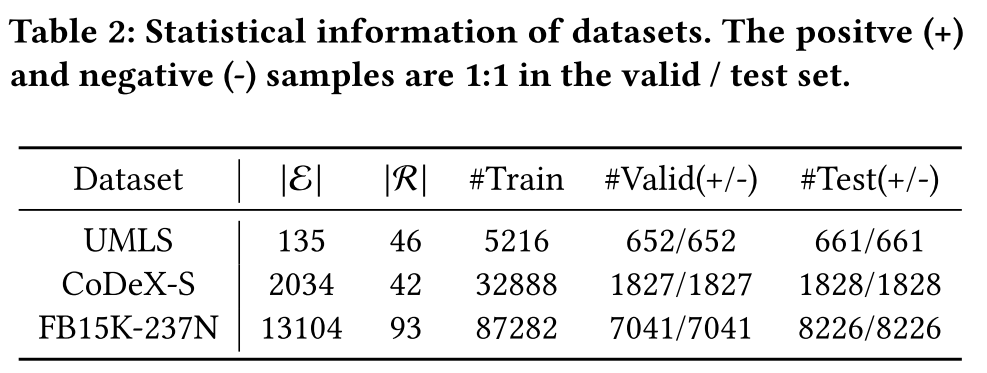
Baseline Methods 基准方法。本文在三类基准方法上进行了三元组分类的任务。三类基准方法分别是:基于嵌入的方法、基于预训练语言模型的方法以及基于大模型的方法。此外,还进一步将基于LLM的方法细分为无训练方法和微调方法。无训练方法包含零样本推理(ZSR)和上下文学习(ICL),微调方法包含原始指令调优(vinilla IT)和结构感知指令调优(enhanced IT)。
(1) Embedding-based KGC methods 基于嵌入的KGC方法。本文选取了TransE, DistMult , ComplEx, 和RotatE等基准方法。这些方法通过学习到的结构嵌入和模型中定义的评分函数来预测三元组可信性。
(2) PLM-based KGC methods 基于预训练语言模型的KGC方法。本文选取了KG-BERT和PKGC两种基准方法。这一类方法将三元组分类问题视作文本的二分类问题。
(3) LLM-based KGC methods 基于大语言模型的KGC方法。本文选取KGLLaMA作为测试模型。
Main Results
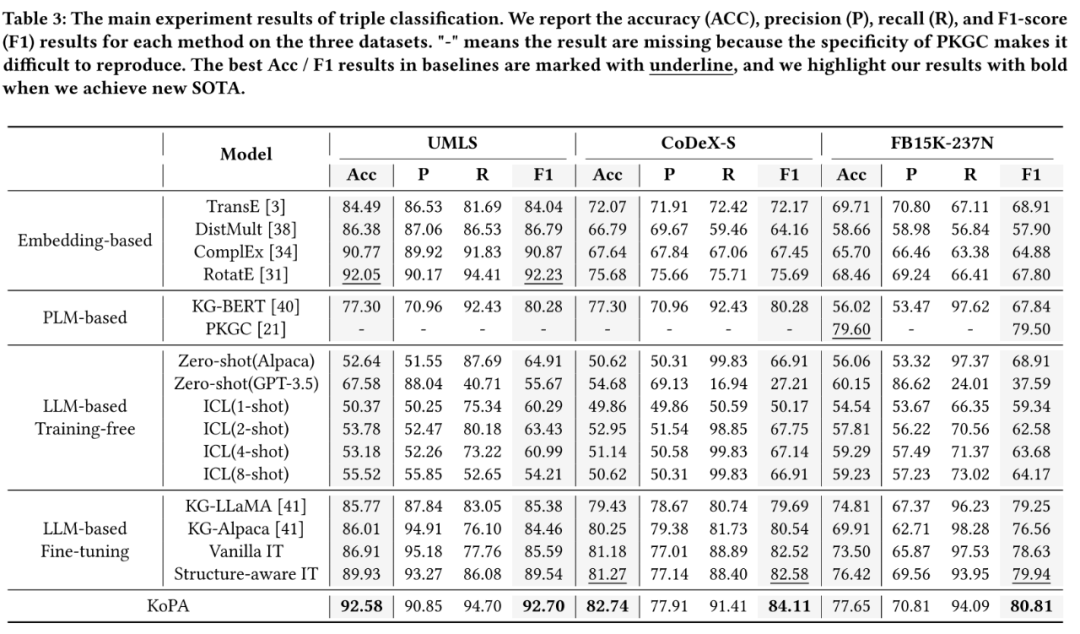
KoPA 在所有三个数据集(UMLS、CoDeX - S 和 FB15K - 237N)上的 Acc 和 F1 结果均优于 16 种基准模型。例如,在 CoDeX - S 数据集上,Acc 达到 82.74%,F1 达到 84.11%,相比其他模型有显著提升。
与传统嵌入型方法(如 TransE、DistMult、ComplEx 和 RotatE)相比,KoPA 优势明显。以 CoDeX - S 数据集为例,RotatE 的 Acc 为 75.68%,F1 为 75.69%,而 KoPA 的 Acc 提升了约 7.06%,F1 提升了约 8.42%,尤其在较大和更具挑战性的数据集上表现更为突出,说明 KoPA 能更好地利用 KG 结构信息进行准确预测12。
与基于 PLM 的方法(如 KG - BERT)相比,KoPA 在 Acc 和 F1 上也有明显优势。在 UMLS 数据集上,KG - BERT 的 Acc 为 77.30%,F1 为 80.28%,而 KoPA 的 Acc 达到 92.58%,F1 达到 92.70%,表明 KoPA 在三元分类任务中的有效性更高。
零样本推理(ZSR)方法中,无论是使用 Alpaca 还是 GPT - 3.5 - turbo 作为 LLM,在三元分类任务中的表现都较差。例如,在 UMLS 数据集上,Zero - shot(Alpaca)的 Acc 为 52.64%,F1 为 64.91%;Zero - shot(GPT - 3.5)的 Acc 为 67.58%,F1 为 55.67%,远低于 KoPA 的性能,说明零样本 LLM 难以有效处理 KGC 任务,即使像 GPT - 3.5 - turbo 这样参数众多的模型也不例外。
上下文学习(ICL)方法通过提供示例引入 KG 信息,但性能提升有限。在 CoDeX - S 数据集上,ICL(1 - shot)的 Acc 为 49.86%,F1 为 50.17%;ICL(8 - shot)的 Acc 为 50.62%,F1 为 64.17%,与 KoPA 相比差距明显,表明仅靠示例增强无法使 LLM 充分理解 KG 结构信息。对于微调 LLM 的方法,如 KG - LLaMA、KG - Alpaca 和 Vanilla IT 等,虽然整体性能比无训练方法有所提升,但仍不及 KoPA。以 FB15K - 237N 数据集为例,KG - LLaMA 的 Acc 为 79.69%,F1 为 79.25%;Vanilla IT 的 Acc 为 73.50%,F1 为 78.63%,而 KoPA 的 Acc 达到 84.11%,F1 达到 80.81%,说明 KoPA 在微调过程中能更有效地利用结构信息。
结构感知指令调整(IT)方法在一定程度上增强了输入提示,但与 KoPA 相比仍存在差距。在 UMLS 数据集上,Structure - aware IT 的 Acc 为 89.93%,F1 为 89.54%,低于 KoPA 的性能,进一步证明了 KoPA 通过结构嵌入和适配器设计能更好地捕捉 KG 结构信息,从而提升模型性能。
Transferability Exploration
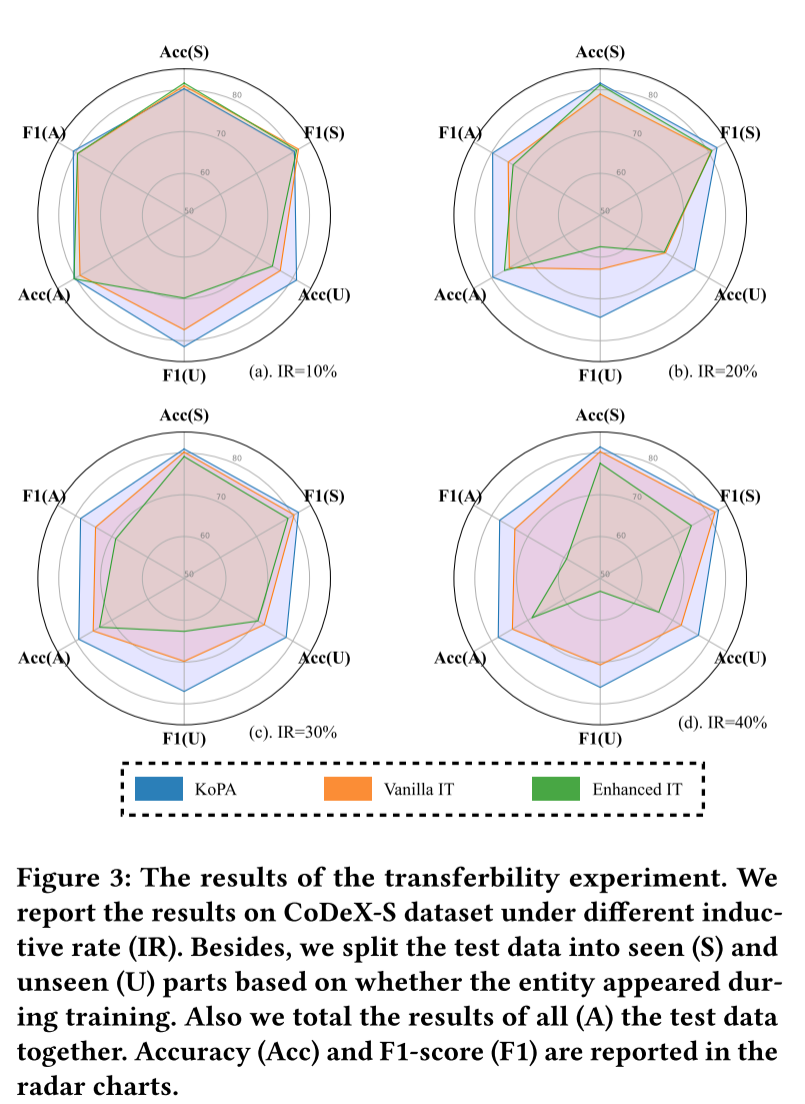
在处理未见三元组时,KoPA 表现出色,其性能下降幅度明显小于其他方法。在 CoDeX - S 数据集上,随着 IR 增加,KoPA 的 Acc 和 F1 分数相对稳定,而其他方法(如 Vanilla IT 和 Structure - aware IT)的性能波动较大,表明 KoPA 在面对新实体时具有更好的适应性和迁移能力。结果证明了知识前缀适配器能够有效地学习从结构嵌入到文本表示的映射,从而在未见实体的情况下,仍能为 LLM 提供有价值的结构信息,辅助模型进行准确推理,体现了 KoPA 设计的有效性和优越性,使其在实际应用中更具潜力,能够处理不同分布的数据。
Ablation Study
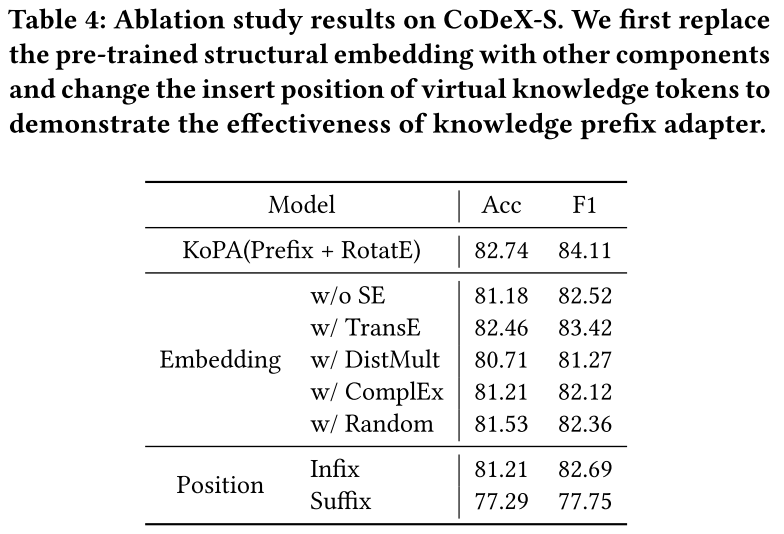
消融实验表明,去除结构嵌入(w/o SE)会导致模型性能下降。在 CoDeX - S 数据集上,Acc 从 82.74% 降至 81.18%,F1 从 84.11% 降至 82.52%,表明结构嵌入对模型性能提升至关重要,它编码了丰富的 KG 结构信息,有助于模型做出更准确的预测。
Case Study

通过统计多个模型在测试数据上的预测重叠情况,并绘制维恩图,可以直观地看到 KoPA 与其他模型的预测差异。结果显示,KoPA 有相当一部分正确预测与其他模型不相交,这意味着在许多其他模型预测错误的数据上,KoPA 能够做出正确预测。例如,在某些特定数据集中,其他模型可能因无法有效利用结构信息而出现错误判断,但 KoPA 能够凭借其融入的结构信息做出准确的预测,从而体现出 KoPA 在处理知识图谱三元组时的独特优势,进一步证明了其结构信息在提升预测准确性方面的重要作用。
以一个具体的测试三元组 “John Landis, film director film, Coming to America” 为例,详细对比了 KoPA 与其他模型的预测结果。即使引入了检索到的邻域三元组(如 “Coming to America, locations, New York City”,“John Landis, nationality, USA” 等),结构感知微调 LLM 仍然做出了错误预测,原因是这些邻域信息在当前预测判断中作用有限,尽管它们本身是正确的事实信息。而 KoPA 能够做出正确预测,原因在于其应用的结构嵌入包含了比文本形式结构信息更多的内容,并且通过结构预训练过程更容易提取关键信息。这表明在实际的三元组分类任务中,KoPA 能够更好地捕捉和利用结构信息,从而在复杂的知识图谱推理中表现出色,为解决 KGC 任务提供了更有效的方法。
Common Ability Retention
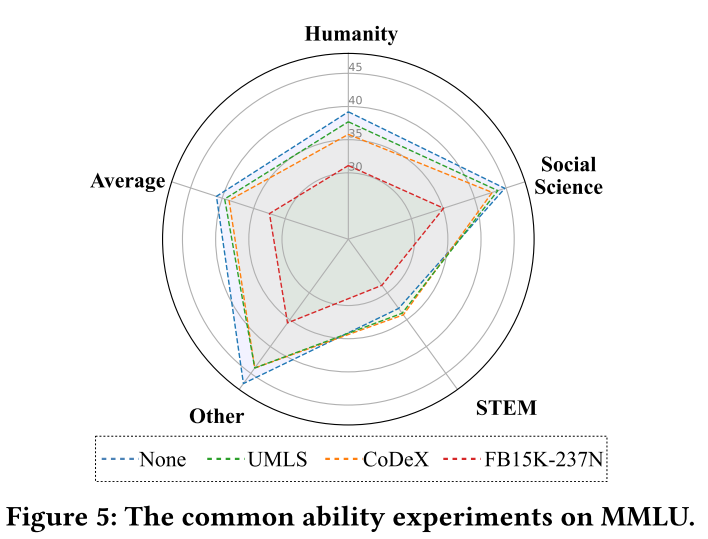
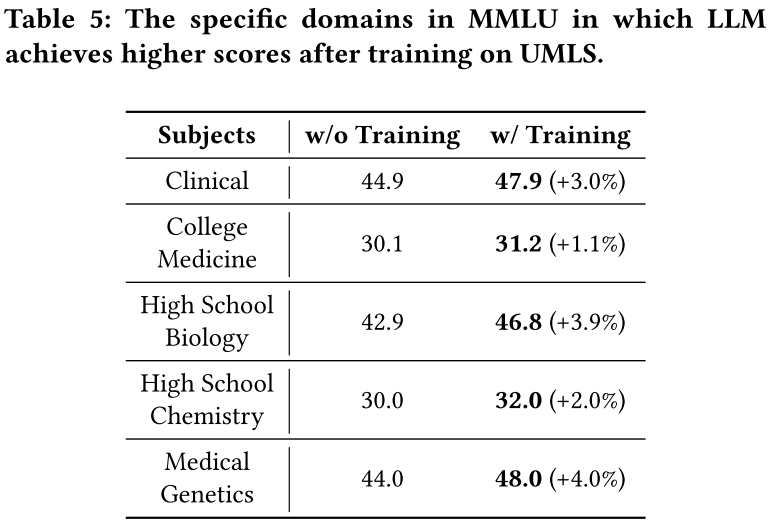
MMLU(Measuring Massive Multitask Language Understanding)是一个用于评估大语言模型(LLM)通用能力的基准测试,在论文中被用于评估 LLM 在经过知识图谱补全(KGC)任务训练后通用能力的变化。本文使用该基准测试来评估 LLM 在不同领域(如人文、社会科学、STEM 等)的通用能力。在 LLM 进行 KoPA 训练前后,分别在 MMLU 上进行测试,以观察其能力的变化。经过 KoPA 训练后,LLM 的通用能力在大多数情况下有所下降,但在与 UMLS 数据集相关的 STEM 领域表现出提升。在 UMLS 数据集上,训练后 LLM 在临床、大学医学、高中生物、高中化学和医学遗传学等学科上的得分均有提高,如临床学科从 44.9 分提升至 47.9 分(提升 3.0%),高中生物从 42.9 分提升至 46.8 分(提升 3.9%)。UMLS 是一个医学知识图谱,包含大量医学、生物学和化学等领域的知识。在该数据集上进行训练使模型获取了更多相关领域的知识,从而在面对与这些知识相关的自然语言输入时,能够更好地利用所学知识,进而提升了在 STEM 领域的表现。这表明在特定领域的知识图谱训练可以对模型在相关领域的通用能力产生积极影响,同时也为进一步探索如何在提升模型特定任务性能的同时保持或提升其通用能力提供了参考依据。
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
优快云粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传优快云,朋友们如果需要可以扫描下方二维码&点击下方优快云官方认证链接免费领取 【保证100%免费】

读者福利: 👉👉优快云大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)

👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程文末领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)


👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
优快云粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传优快云,朋友们如果需要可以扫描下方二维码&点击下方优快云官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉优快云大礼包:《最新AI大模型学习资源包》免费分享 👈👈


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









