







 本文探讨了自注意力在SequenceLabeling任务中的关键作用,介绍了多头自注意以及如何结合PositionalEncoding处理序列位置信息。Transformer的encoder部分通过残差网络和层归一化增强模型性能,同时讲解了Transformer的解码器结构。重点展示了Transformer在处理自然语言理解和序列标注任务中的实际操作。
本文探讨了自注意力在SequenceLabeling任务中的关键作用,介绍了多头自注意以及如何结合PositionalEncoding处理序列位置信息。Transformer的encoder部分通过残差网络和层归一化增强模型性能,同时讲解了Transformer的解码器结构。重点展示了Transformer在处理自然语言理解和序列标注任务中的实际操作。
输入输出
1.输入
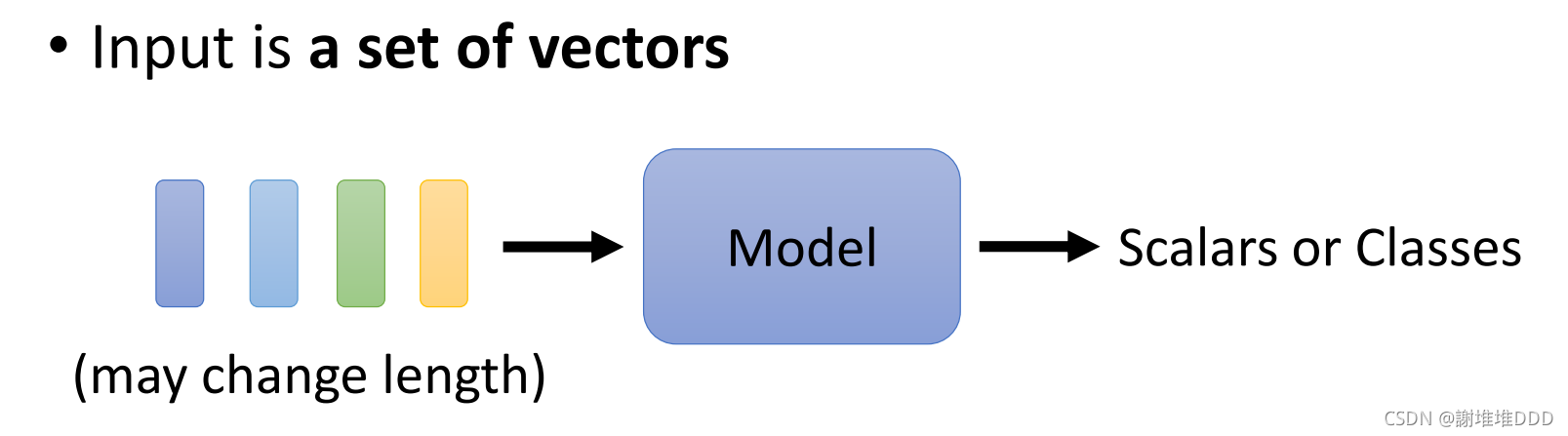
2.输出
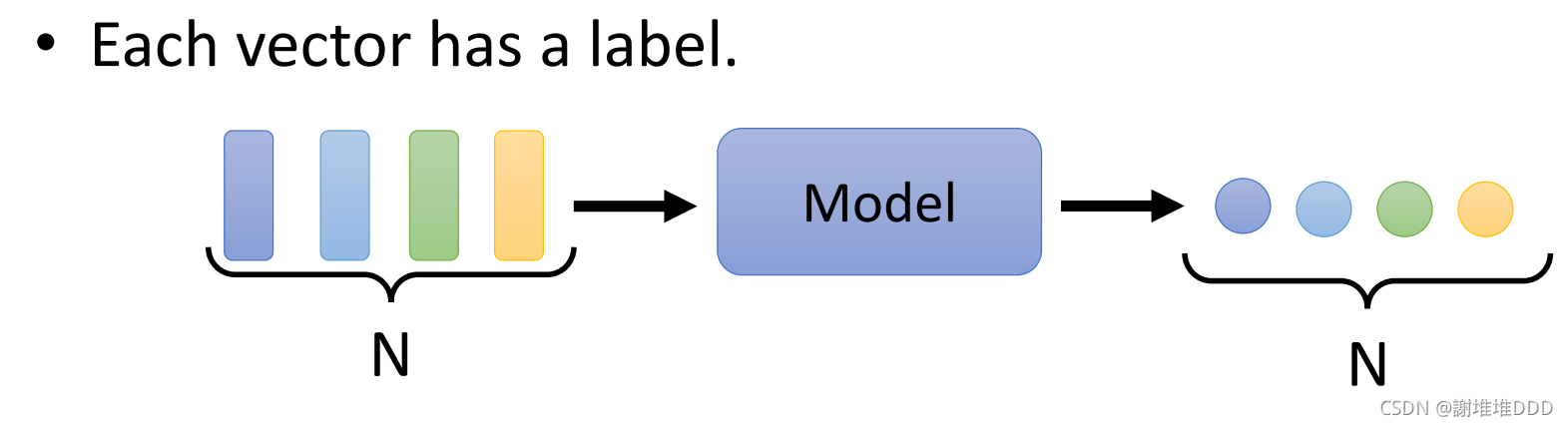
2.1每个向量是个标签,输入多少个,输出多少个
2.2整个序列是一个标签,比如说情感分析

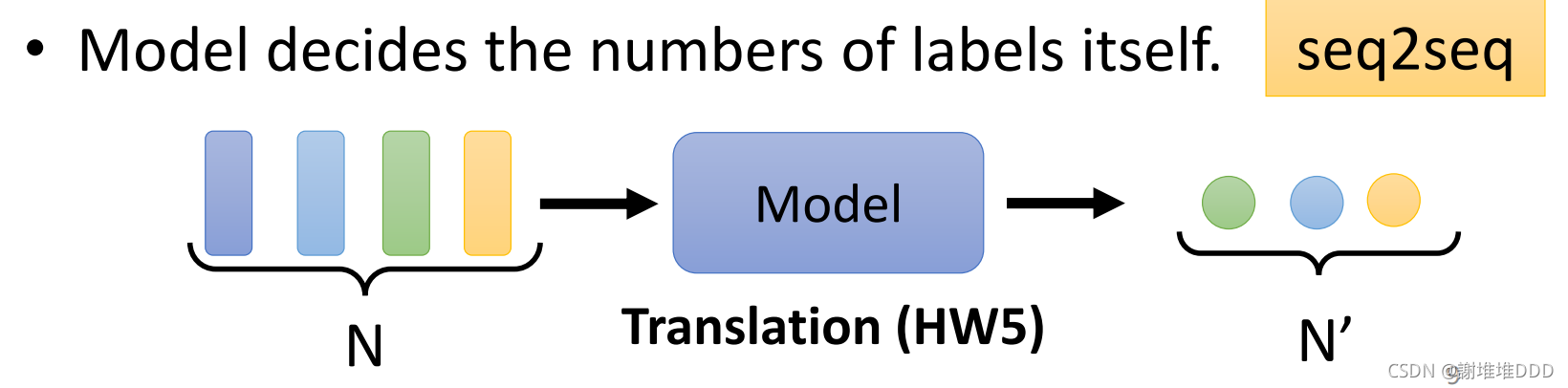
2.3输出标签数量有model决定,比如说翻译
Sequence Labeling
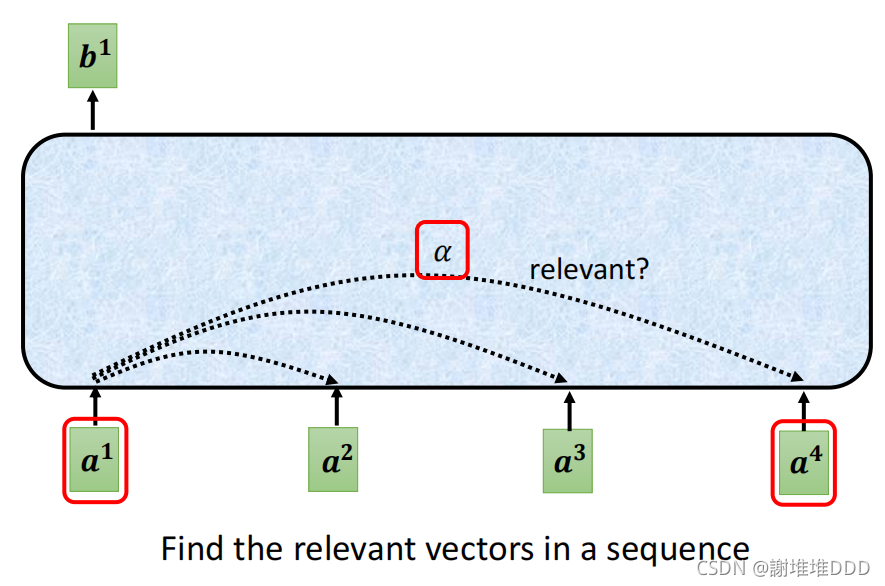
自注意可以叠加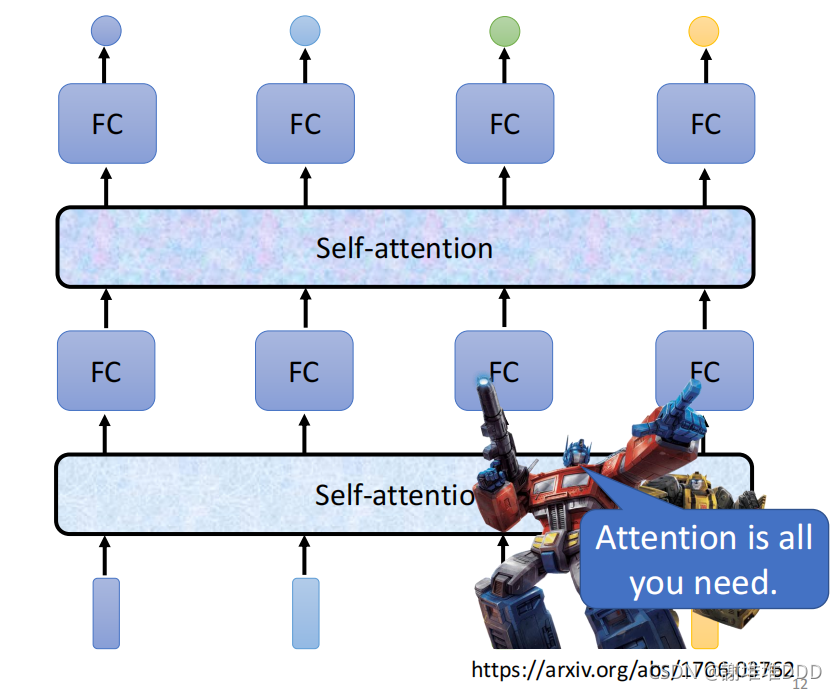
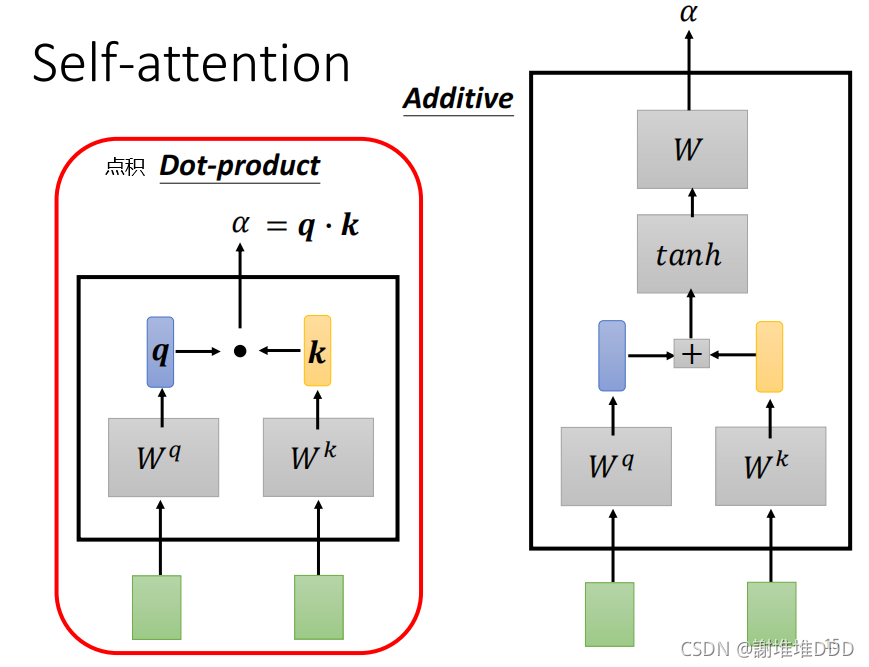
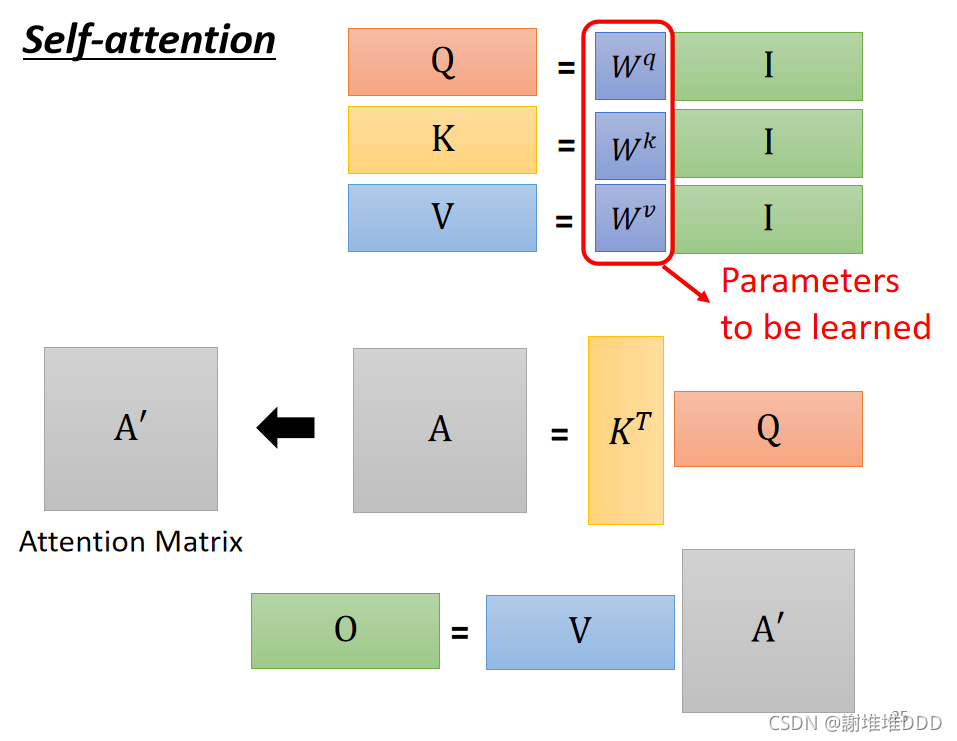
计算关联的程度 α。常用的方法是点积,也是Transformer里用的方法。
计算关联性:α1,2=q1∙k2,向量a1和向量a2的关联性。向量a1也会计算和自己的关联性。
q1=Wq*a1,向量a1乘
然后进行Soft-max或者relu操作得到α′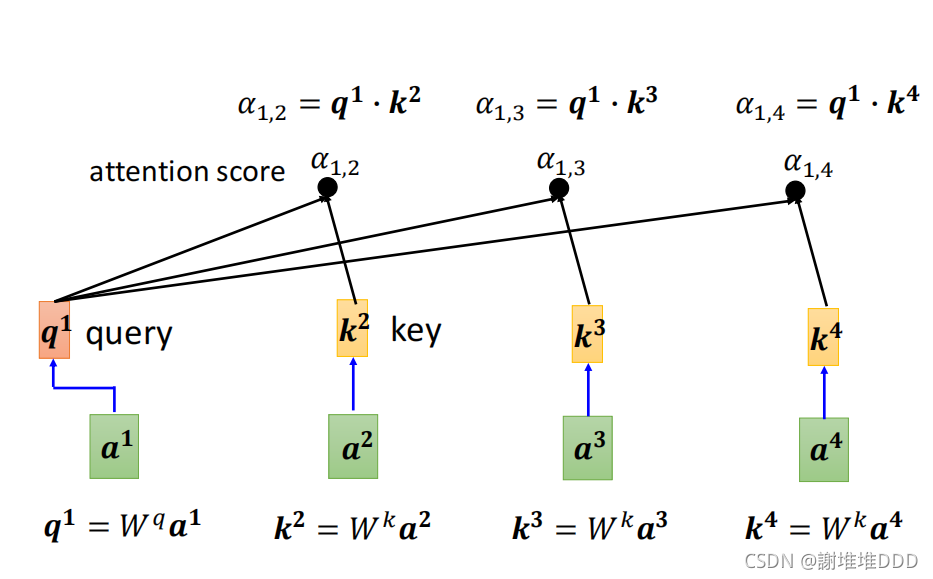
α是知道哪些向量跟a1最有关系。
抽取重要的资讯:计算b1
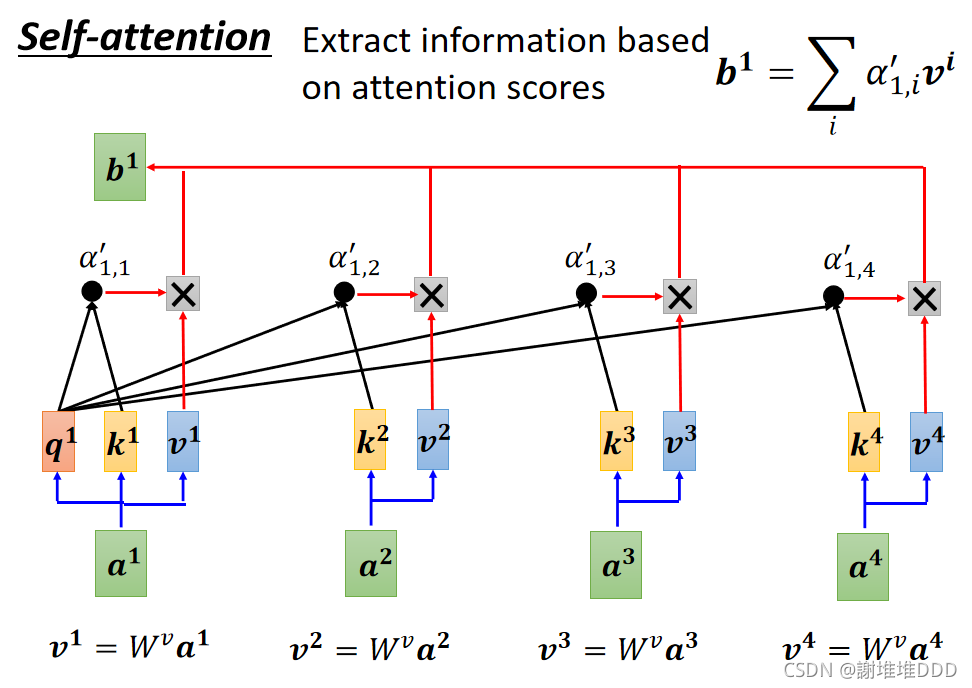
b就是输出
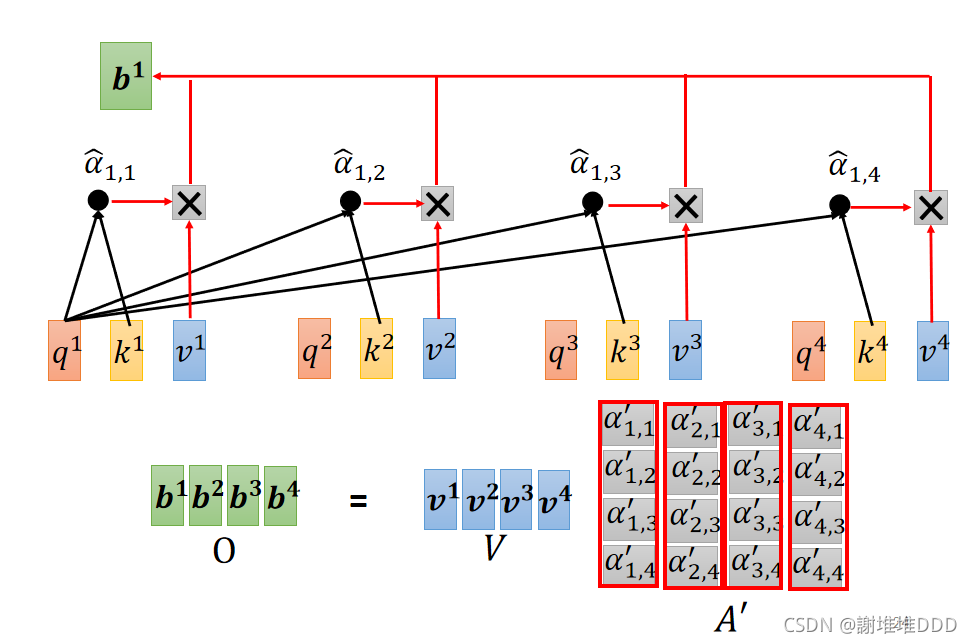
总:
self-attention的输入是I,输出是O
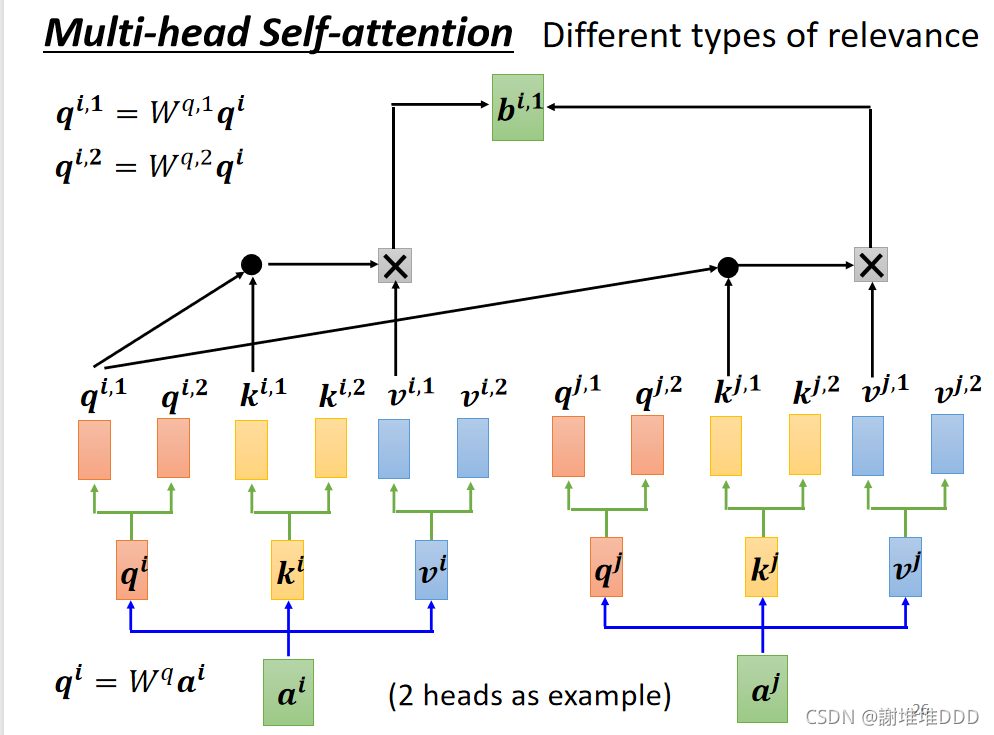
self-attention的一个变形,多头自注意:两个q代表两种不同的相关性,几个q就是几个head
如果输入序列的位置资讯很重要,需要用到Positional Encoding,为每一个位置设置一个vector。
在Transformer中,输入数据是一起处理的,就会忽略掉数据间的位置关系,所以需要一个位置编码。
位置编码可以学习
Transformer
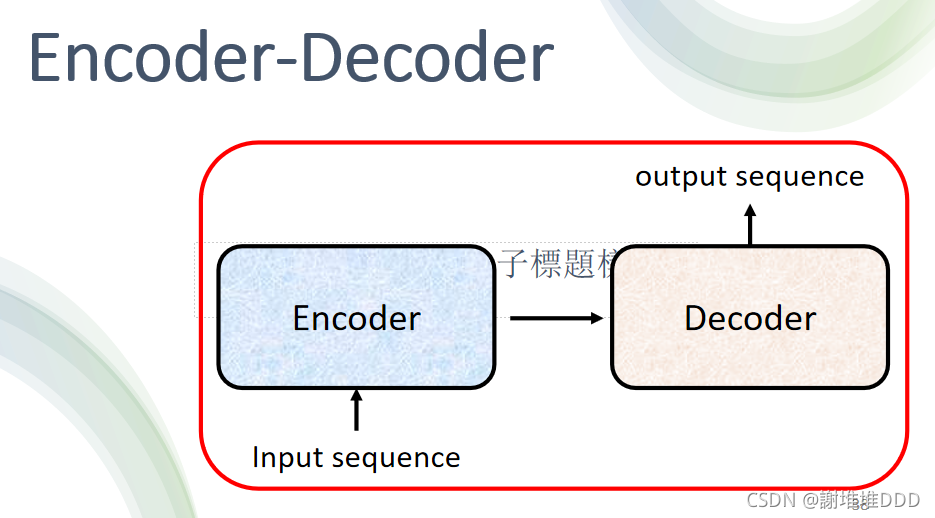
encoder
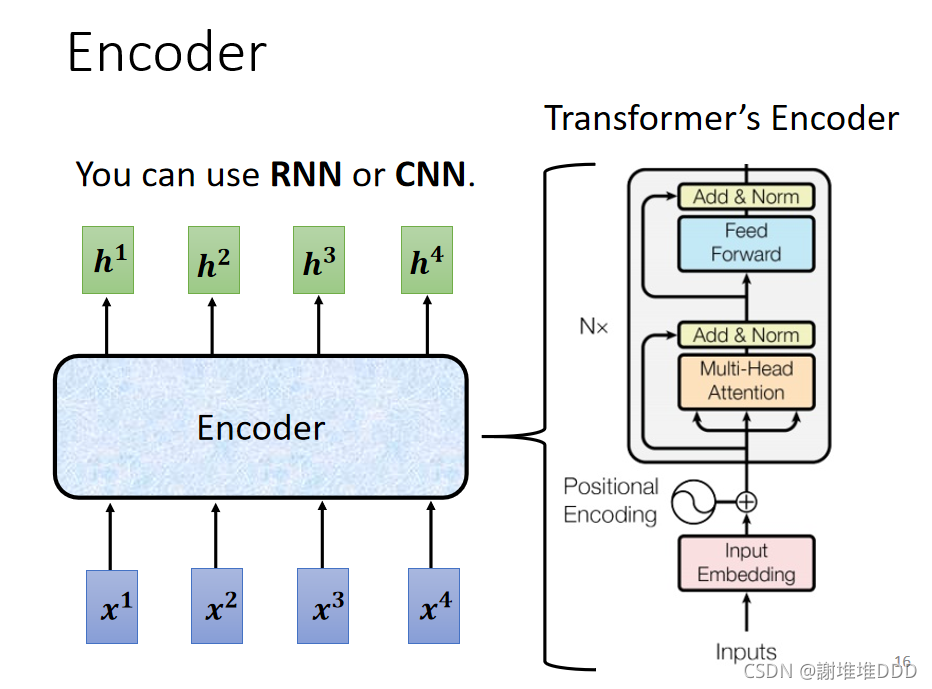
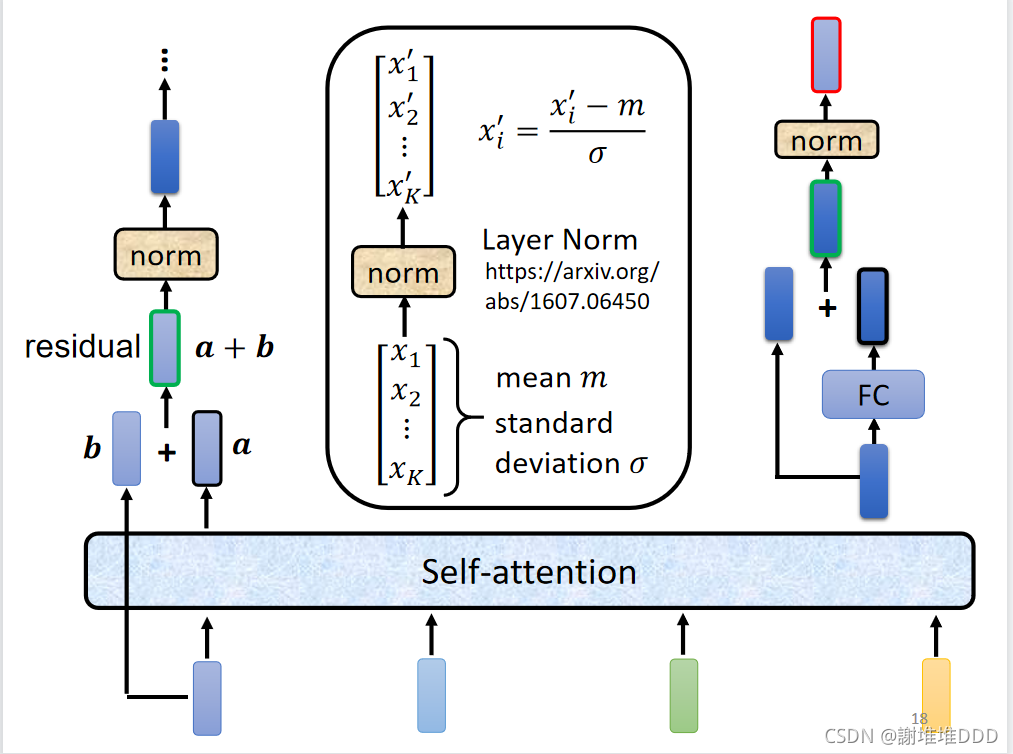
residual残差网络:将经过self-attention得到的向量与之前经过位置编码的向量相加
残差网络可以缓解梯度消失,网络可以叠加。
层归一化
前馈神经网络(两层全连接)
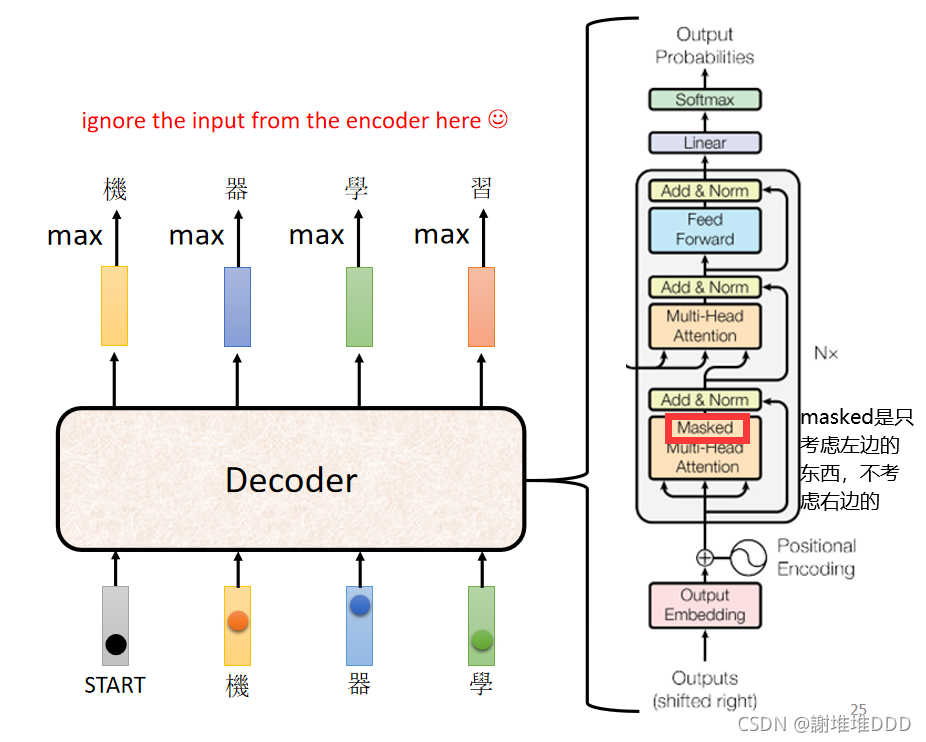
decoder


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









