









13.1 为什么要并发
1、并发是一种解耦策略,把做什么和何时做分解开,进而改进应用程序的吞吐量和结构。我理解的吞吐量是同时执行的任务数量。
2、关于并发:(1)并发会在性能和编写额外代码上增加一些开销;(2)正确的并发是复杂的,即便对于简单的问题也是如此;(3)并发缺陷并非总能重现,所以常被看做偶发事件而忽略,未被当作真的缺陷看待;(4)并发常常需要对设计策略的根本性修改。
13.2 并发编程所面临的挑战
多个线程之间的相互影响。
13.3 并发防御原则
1、单一权责原则(SRP):类/方法/组件应当只有一个修改的理由。而并发设计足够复杂,足以成为修改的理由,因此需要将并发相关代码与其它代码分开。
2、限制数据作用域:当多个线程修改共享对象时可能出现干扰,此时需要使用关键字synchronized在代码中保护一块使用共享对象的临界区,然而需要谨记封装,严格限制对可能被共享的数据的访问。
3、使用数据复本:复制对象并以只读的方式对待,然后从多个线程收集所有复本的结果,并在单个线程中合并这些结果。
4、线程应尽可能的独立:让每个线程在自己的世界中存在,不与其它线程共享数据。
13.4 了解Java库
(1)使用类库提供的线程安全群集;(2)使用executor framework执行无关任务;(3)尽可能使用非锁定解决方案;(4)有几个类并不是线程安全的。
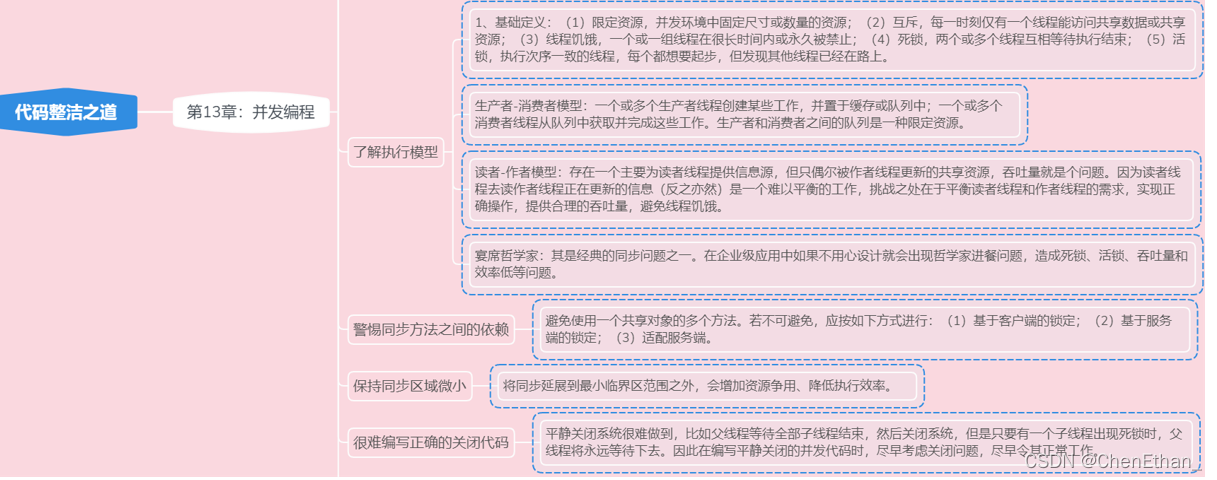
13.5 了解执行模型
1、基础定义:(1)限定资源,并发环境中固定尺寸或数量的资源;(2)互斥,每一时刻仅有一个线程能访问共享数据或共享资源;(3)线程饥饿,一个或一组线程在很长时间内或永久被禁止;(4)死锁,两个或多个线程互相等待执行结束;(5)活锁,执行次序一致的线程,每个都想要起步,但发现其他线程已经在路上。
生产者-消费者模型:一个或多个生产者线程创建某些工作,并置于缓存或队列中;一个或多个消费者线程从队列中获取并完成这些工作。生产者和消费者之间的队列是一种限定资源。
读者-作者模型:存在一个主要为读者线程提供信息源,但只偶尔被作者线程更新的共享资源,吞吐量就是个问题。因为读者线程去读作者线程正在更新的信息(反之亦然)是一个难以平衡的工作,挑战之处在于平衡读者线程和作者线程的需求,实现正确操作,提供合理的吞吐量,避免线程饥饿。
宴席哲学家:其是经典的同步问题之一。在企业级应用中如果不用心设计就会出现哲学家进餐问题,造成死锁、活锁、吞吐量和效率低等问题。
13.6 警惕同步方法之间的依赖
避免使用一个共享对象的多个方法。若不可避免,应按如下方式进行:(1)基于客户端的锁定;(2)基于服务端的锁定;(3)适配服务端。
13.7 保持同步区域微小
将同步延展到最小临界区范围之外,会增加资源争用、降低执行效率。
13.8 很难编写正确的关闭代码
平静关闭系统很难做到,比如父线程等待全部子线程结束,然后关闭系统,但是只要有一个子线程出现死锁时,父线程将永远等待下去。因此在编写平静关闭的并发代码时,尽早考虑关闭问题,尽早令其正常工作。
13.9 测试线程代码
1、将伪失败看作可能的线程问题,不要将系统错误归咎于偶发事件。
2、先使非线程代码可工作,注意不要同时追踪非线程缺陷和线程缺陷。
3、编写可插拔的线程代码,编写可在数个配置环境下运行的线程代码。
4、编写可调整的线程代码,允许线程数量可调整,允许线程依据吞吐量和系统使用率自我调整。
5、运行多于处理器数量的线程,任务交换越频繁,越有可能找到错过临界区或导致死锁的代码。
6、在不同平台上运行。尽早并经常在所有目标平台上运行线程代码。
7、装置试错代码。(1)硬编码;(2)自动化。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









