



本次实验要求是在两个模糊测试工具(AFL和Syzkaller)中选择一款工具进行使用,进行模糊测试。本次我选择的是AFL++(AFL plus plus)。
一、AFL++介绍
1.AFL++安装
我是在ubuntu20.04版本(wsl2)进行配置的:
准备好需要的基础配件:
如果有配件不存在就install即可
在Github上下载AFL++:
进行make,编译核心组件
之后sudo make install

可能出现的错误:可能会出现涉及LLVM和Clang的插件无法编译,只需要先配置好LLVM和Clang然后再尝试编译即可。
2.工作流程
AFL++Fuzz可以分成4个阶段:插桩阶段、准备阶段、执行阶段、验证阶段
a)插桩阶段
这部分是在目标程序中进行插桩,记录程序的执行路径(为后续的变异和筛选做准备)
插桩可以分成两种方式:
源码插桩:使用AFL++提供的编译器如afl-gcc-fast/afl-g++-fast/afl-clang-fast代替我们常规的gcc/clang等编译器。(可以选用高级插桩选项如使用ASAN能搭配检测内存漏洞)
二进制插桩:无源码时可以使用,借助如afl-qemu-trace对目标二进制程序进行插桩(借助qemu获取程序执行路径)
b)准备阶段
准备测试环境和初始测试的种子(seed)。
种子可以保存在input目录,在选取时需要覆盖目标程序的核心功能(如测试SQL语句则种子需要包含SELECT/INSERT等基础语法);
输出保存在output目录,在配置环境时我们可以选取运行参数:-t(设置超时时间,避免卡死)、-m(设置内存限制,防止溢出)、-d(调试)
c)执行阶段(该部分是AFL++的核心部分)
变异器加载和初始化:

该部分是自定义变异器加载,从环境变量中读取变异器(使用“::,”作为分隔符加载多个变异器)
如果无分隔符(单个变异器)就直接加载;有分隔符就循环切割加载每个变异器(这里调用了load_custom_mutator函数,进行了动态库加载、符号解析、初始化变异器操作)
变异阶段:
该部分主要可以查看fuzz_one_original函数,整体执行流程:
确定性变异:
·位翻转(Bitflip)

该部分是1位翻转,翻转目标缓冲区_ar中第_b个比特的位置,首先将缓冲区指针转为字节数组,然后计算_b所在的字节索引(1字节是8比特所以进行了_bf>>3),偏移量是(_bf & 7)相当于对8取模,然后通过异或操作进行翻转。后续使用:
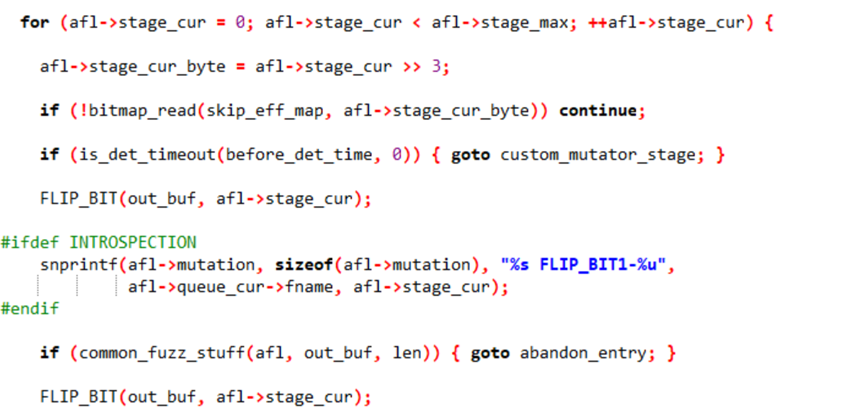
翻转第stage_cur位,然后执行变异用例并记录结果,恢复原始值进行下一次翻转(多位的翻转逻辑类似,不赘述)
·算数运算(Arithmetic)
单字节(8位)的运算逻辑(加法变异和减法变异):
先通过异或结果判断是否可以通过位翻转实现(翻转不能实现非连续的比特翻转和超过4但是不是8/16/32等比特数的翻转或是8/16/32比特翻转但是字节未对齐,这些情况都要使用算数运算进行变异),如果不能通过翻转实现就进行加法、减法变异。
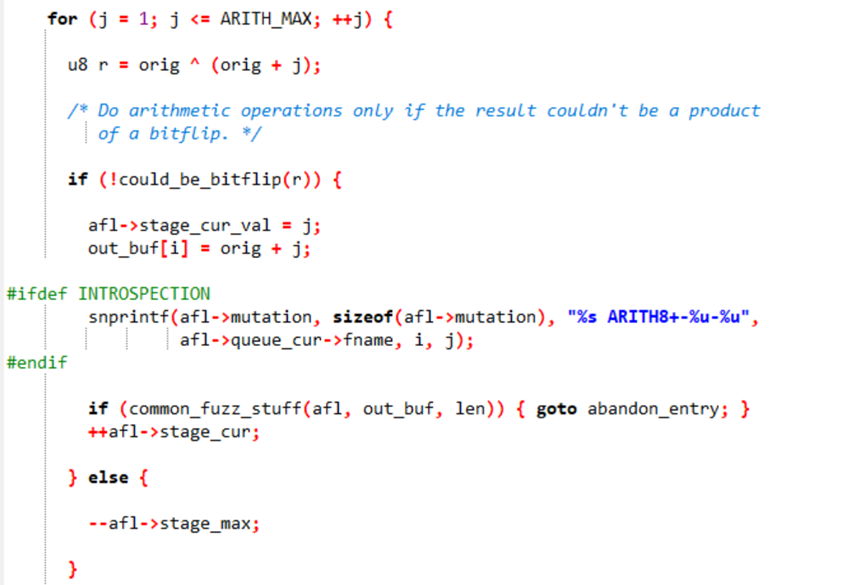
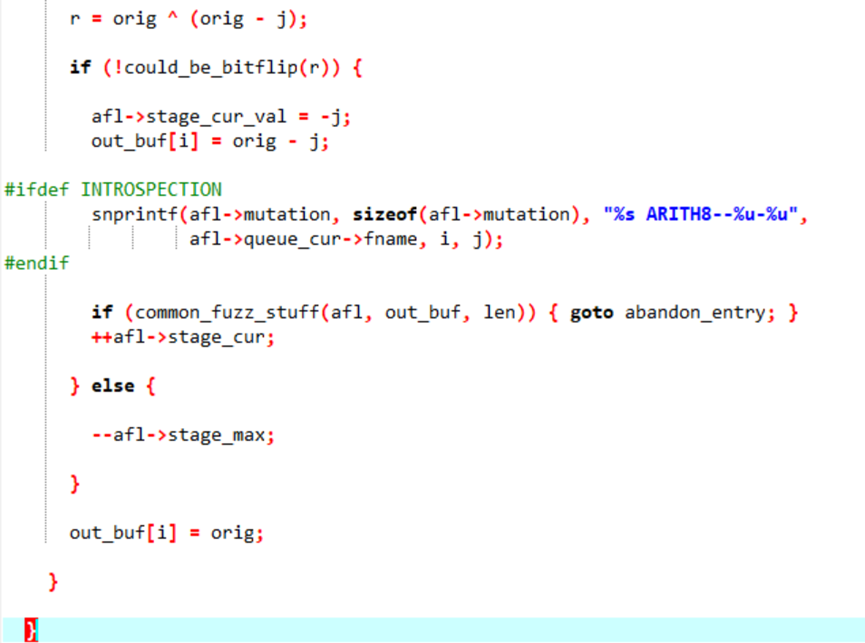
后续还有16位和32位的变异逻辑,类似,但添加了大端法和小端法的不同计算,不过也不赘述。
·有趣值替换(Interesting Values)
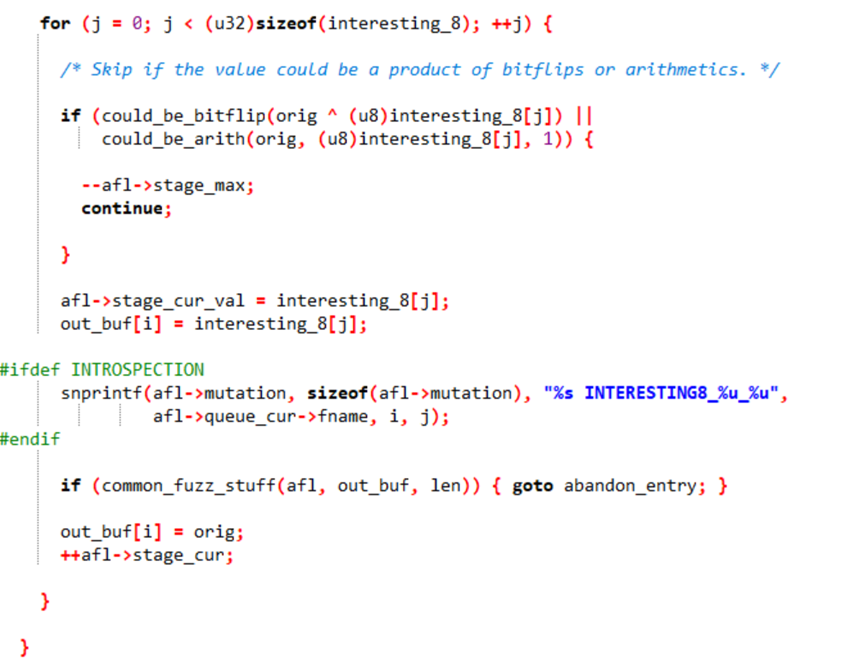
单字节(8位)逻辑:如果替换结果可以通过位翻转或算数运算实现,则跳过;不能的话就将out_buf[i]的值替换为新值进行测试,之后恢复原始值。
16位和32位基本同理,也是增加了大端法和小端法
·字典替换(Dictionary)
使用预设的字典(user extras)或自动生成字典(auto extras)替换输入的对应位置(其中user extras是存储在afl->extras中的令牌;auto extras是AFL++在模糊测试过程中自动检测的有效令牌)。
两种字典都包括data和len两个属性。
两种操作方式:覆盖(Overwrite)和插入(Insert)
◦覆盖:以用户字典为例
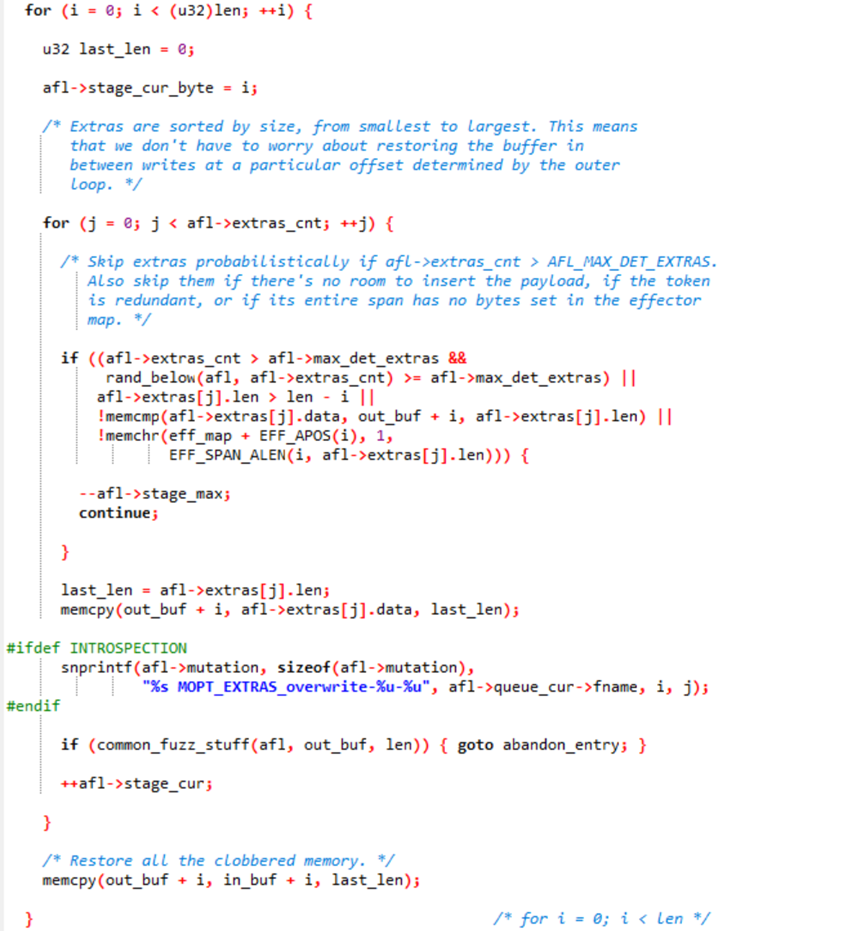
对每个位置进行遍历,遍历每个用户字典条目(需要满足长度适配,非重复替换,覆盖有效即对路径有影响的部分)之后使用afl->extras中的数据进行覆盖,测试是否存在新路径,然后恢复原始数据。
◦插入:以自动字典为例

在执行上述操作前还进行了ex_tmp = afl_realloc(AFL_BUF_PARAM(ex), len + MAX_DICT_FILE);操作,分配足够大的空间存储插入后的输入;
遍历每个插入位置(包括首位),和每个自动字典的数据,过滤掉插入后会溢出的情况,构造新输入(i处插入令牌j),执行测试后检查,恢复。
随机变异:
·随机混沌变异(Random Havoc)
在所有确定性变异阶段(位翻转、算术运算、字典变异)完成后,且未触发退出的情况下可以进入Havoc
该阶段会进行多种随机选择的变异操作。
·变异策略选择:
afl->fuzz_mode:模糊模式(0是探索模式,优先发现新路径,扩大测试范围,在前期使用;非0是利用模式,重点关注能否触发崩溃和发现漏洞)
afl->input_mode:输入类型
◦文本输入:
探索模式使用binary_array(二进制变异数组);利用模式使用text_array(文本变异数组)
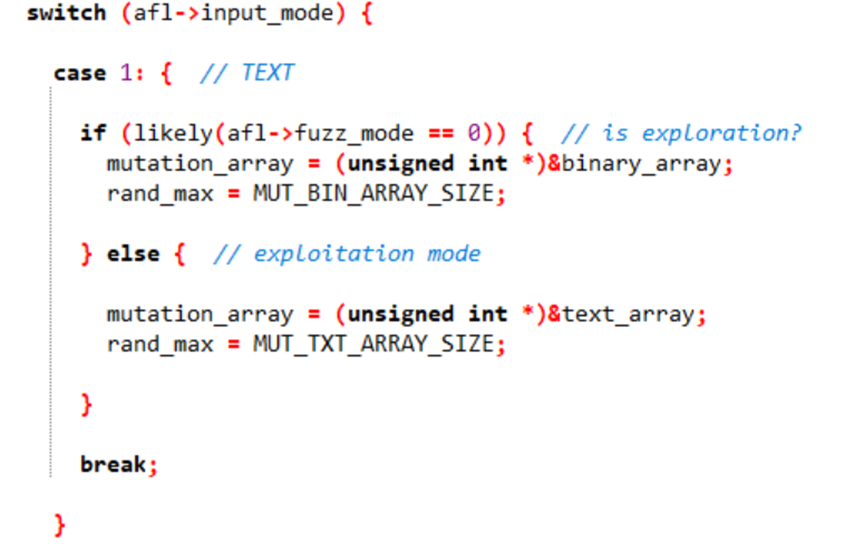
◦二进制输入:
探索模式使用mutation_strategy_exploration_binary(二进制探索策略数组);利用模式使用mutation_strategy_exploitation_binary(二进制利用策略数组)

◦默认:
默认与文本输入一致
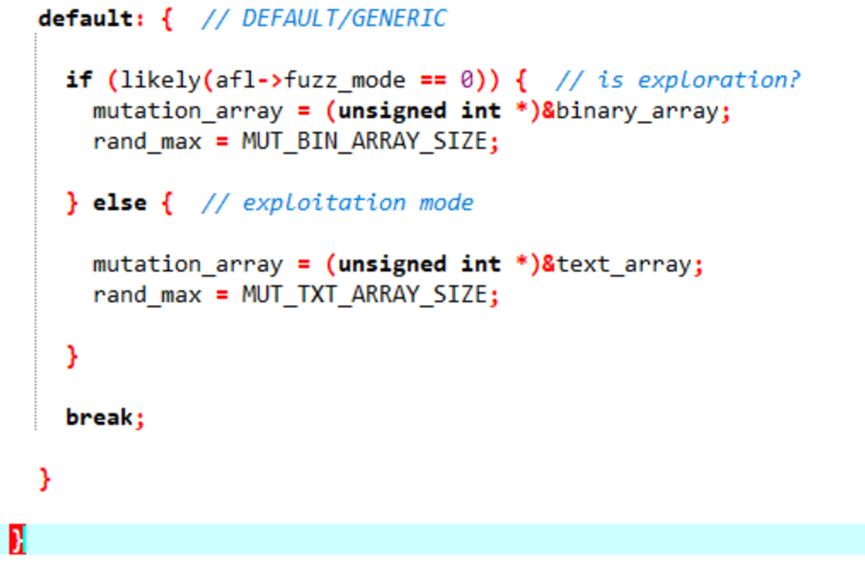
·Havoc还有子操作交叉变异(Splicing):
Splicing可以将两个不同的输入样本进行随机位置拼接,得到新样本(但对于一些格式较强的输入拼接后格式可能非法)。
d)验证阶段
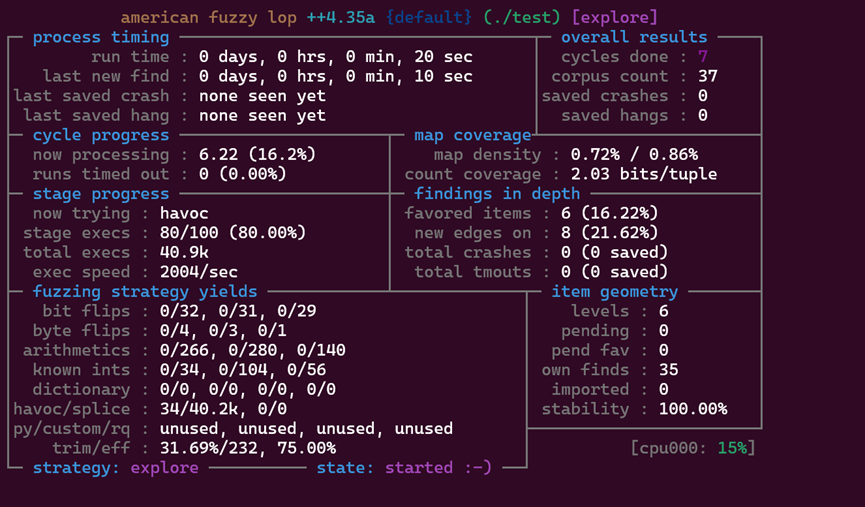
AFL++会基于执行结果反馈动态调整变异策略,会监控执行状态、检查覆盖率(corpus)、触发的crash数量(还有hangs是指挂起或阻塞的用例)。(仔细观察还能发现now trying会出现trim操作,即对用例进行优化,比如删除冗余内容;和quick eff,对实时数据的利用率进行测试,出现hang也会触发)如图:
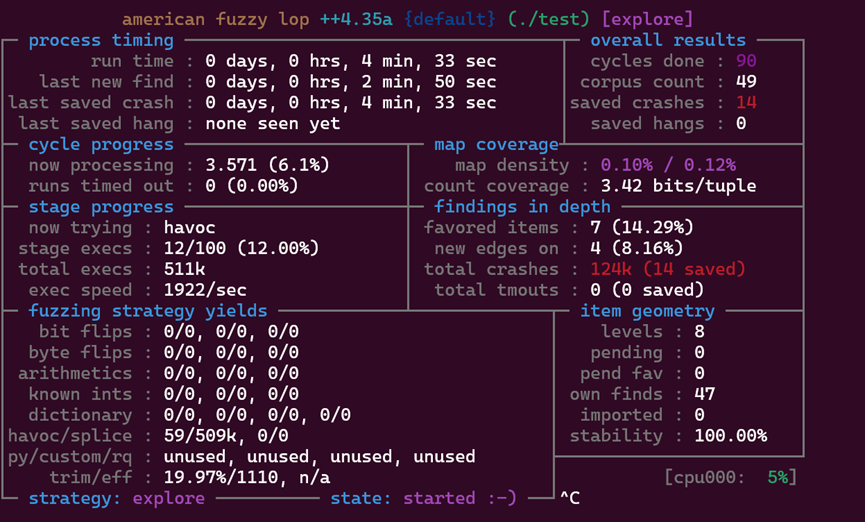
在运行一段时间达到瓶颈期(如长时间没有新路径覆盖或长时间没有漏洞发现)我们可以对output中的用例进行分析,验证是否为可复现的漏洞。
二、初步使用
我对fuzzing book的cgi程序进行了测试
1.源码文件:
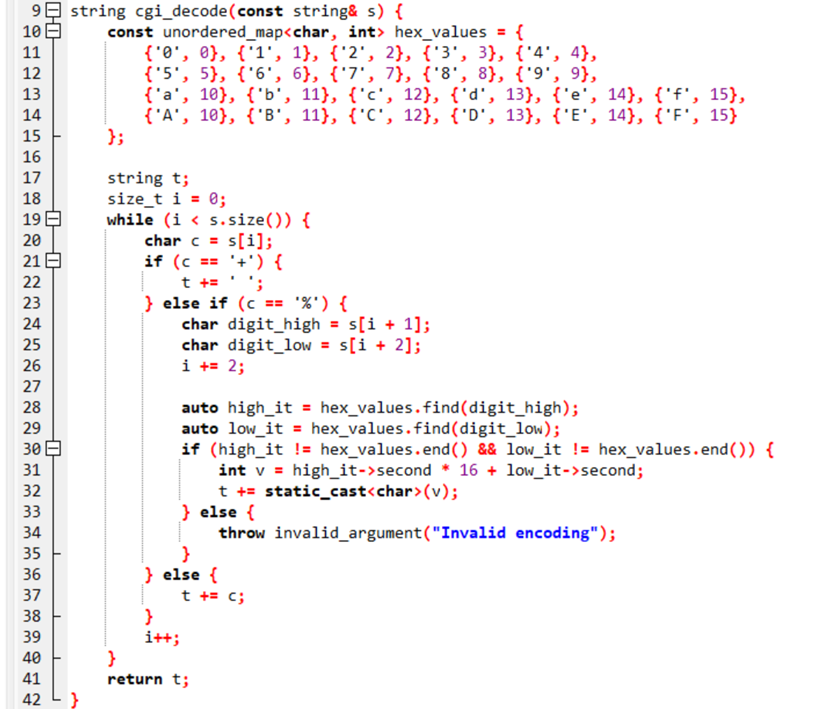
运行结果:
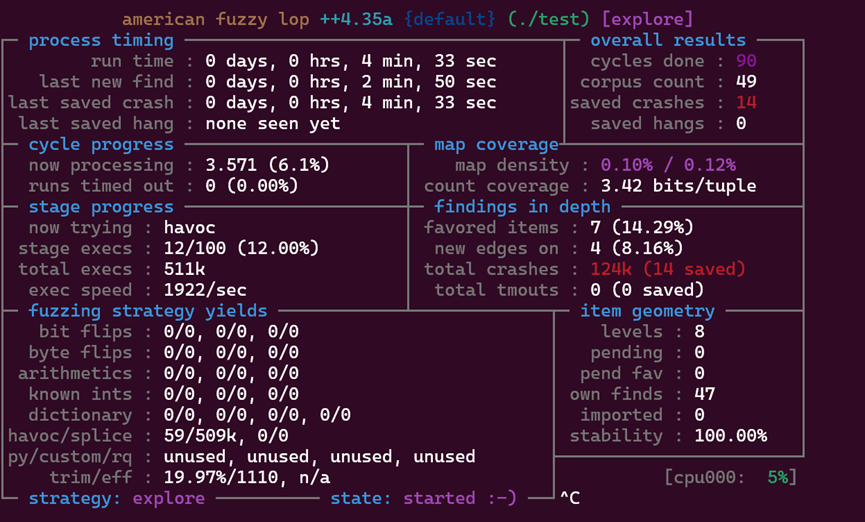
结果发现了14种漏洞:
查看其中的一条输入:
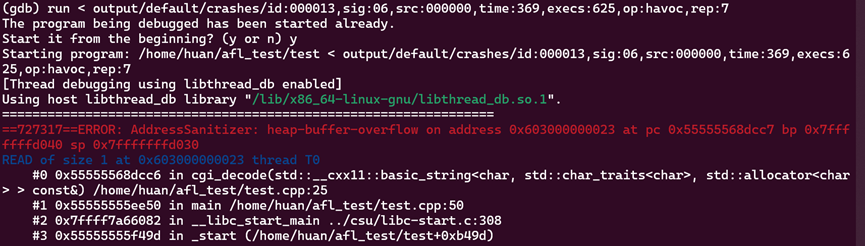
使用gdb发现错误是访问越界了,并且出现在源码的25行,即s[i+2](注意这里使用的是od -c,建议使用hexdump - C查看)

可以发现这种错误是%后虽然有足够的输入,但是后面紧跟着的\0使得数组提前终止了,所以在访问s[i+2]时会出现错误。(这里为什么是sig:06,是因为我在测试这个的时候使用了-fsanitize=address参数,触发越界后ASAN会调用abort()触发信号6)
如果我们希望避免这些无效字符产生的crash,可以尝试从三个角度进行修改:修改目标程序(在程序中过滤无效字符输入)、修改AFL++的有趣值表和Havoc阶段的随机生成逻辑、自定义变异数组(添加一个针对cgi程序的编译数组,将上面提到的选择策略中的逻辑替换为选择我们的自定义数组)
由于后两种都需要对AFL++源码进行操作,在测试其他程序时又需要重复修改,故可以选择最简单的第一种修改方法:
添加一个检查是否有效字符的逻辑:

在while循环内部开头添加:

发现是不合法字符就提前return,避免触发crash;并且根据我们上述分析,触发无效字符时路径固定在27行退出,这会使得AFL++在变异时为了触发更多的路径而减少无效字符的输入。
注意源码依旧还存在Invalid encoding这个错误,所以依旧会出现crash(%后两位的编码不符合要求),我们也进行修改:

重新进行测试:

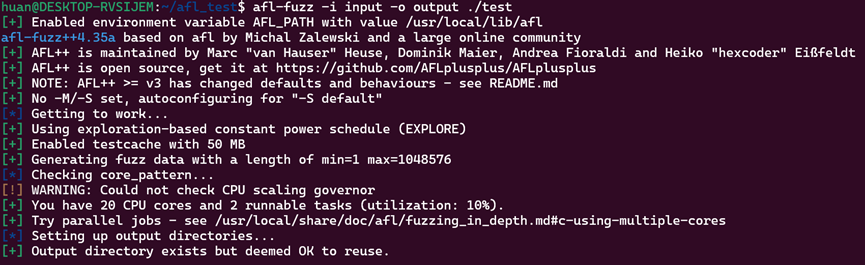
(注意如果编译时不添加-fsanitize=address会很难触发,程序可能尽管出现了越界行为但是由于是进行读操作,目标地址越界可能也不会崩溃)
运行后很轻松得到发现%后可能不存在两个字符的漏洞:

2.二进制文件:
同样是针对这个程序,我们尝试借助qemu进行二进制插桩:
需要重新编译(执行使用-Q通过qemu进行插桩)
![]()
如果爆出这样的错误

可以查看我们下载的源码中qemu_mode中的README.md,使用其自带的编译脚本./build_qemu_support.sh进行下载、配置和编译QEMU
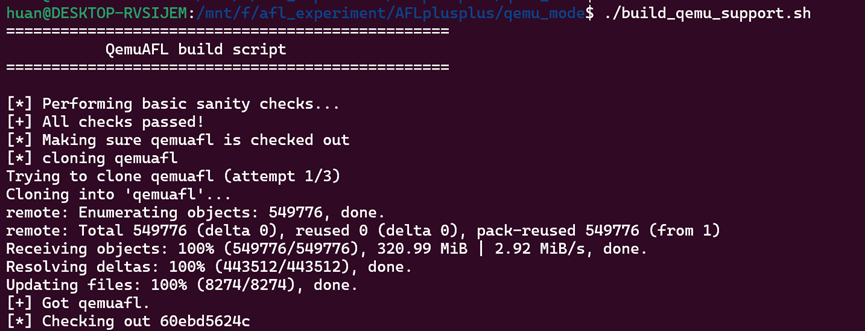
我第一次运行还出现了:

缺少Meson(这里要求>=0.55.0版本),我们也下载就好了:
之后重新执行./build_qemu_support.sh

弹出All done for qemu_mode,enjoy!后再使用sudo make install将工具安装到全局即可:
重新执行:
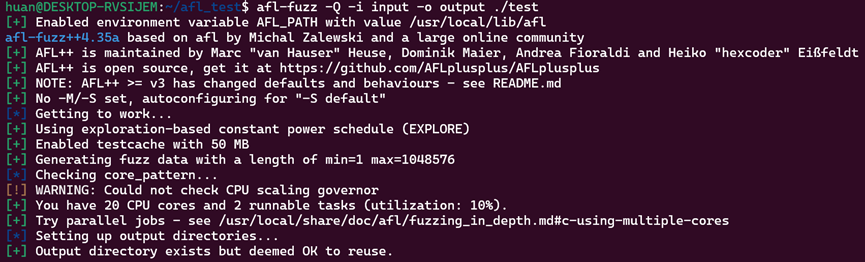
同理运行如图:
如果需要使用QEMU执行二进制程序测试崩溃样例,可以使用afl_qemu_trace工具cat output/default/crashes/<崩溃用例文件名> | afl-qemu-trace ./test
当然,用gdb调试也是可以的。
三、实战
libxml2是一个开源的XML解析和操作类库,可以对XML数据进行处理,尝试挖掘libxml2的漏洞:
1.准备libxml2

在直接运行脚本的时候出现automake的版本过低:
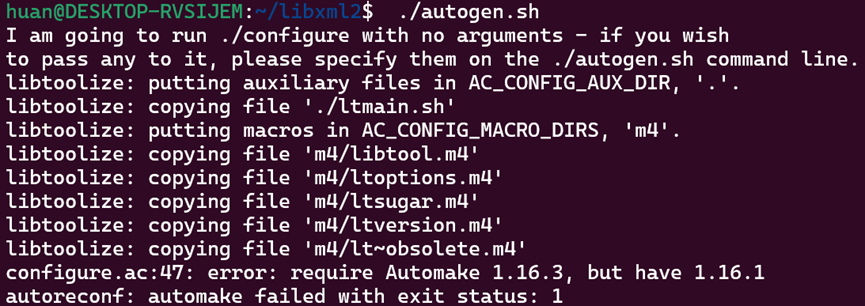
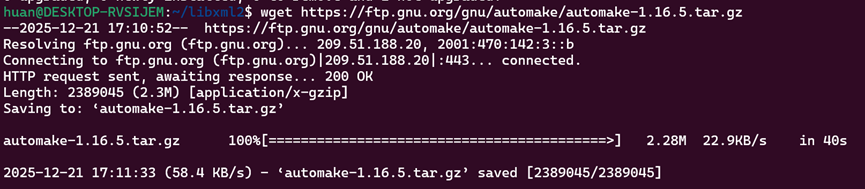
可以手动下载automake新版本的源码:
wget https://ftp.gnu.org/gnu/automake/automake-1.16.5.tar.gz
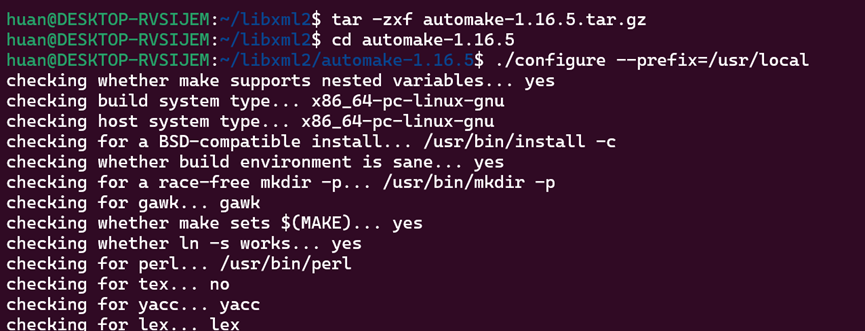
解压缩并编译安装
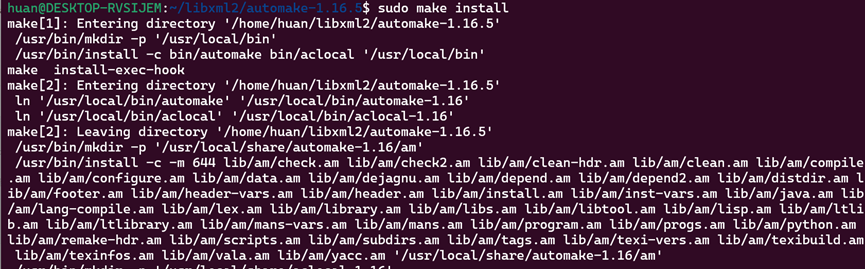
现在版本符合要求了:
重新运行脚本:
禁用共享库:
启用ASAN:export AFL_USE_ASAN=1
make:
2.xmllint工具初始化

在当前目录我们可以找到这个工具,我们进行初始化:

此时fuzz目录:
fuzz/in目录:
3.启动
接着可以直接启动:

/mnt/f/afl_experiment/AFLplusplus/afl-fuzz -i in/ -o out -m none -d -- ./xmllint_cov @@
-m none可以避免程序因内存占用高被误杀,-d可以加速变异,我们开启了ASAN为了精准捕获内存漏洞。
前面的AFL++路径需要替换,这个命令是对./xmllint进行测试(xmllint是libxml2的XML解析命令行工具)
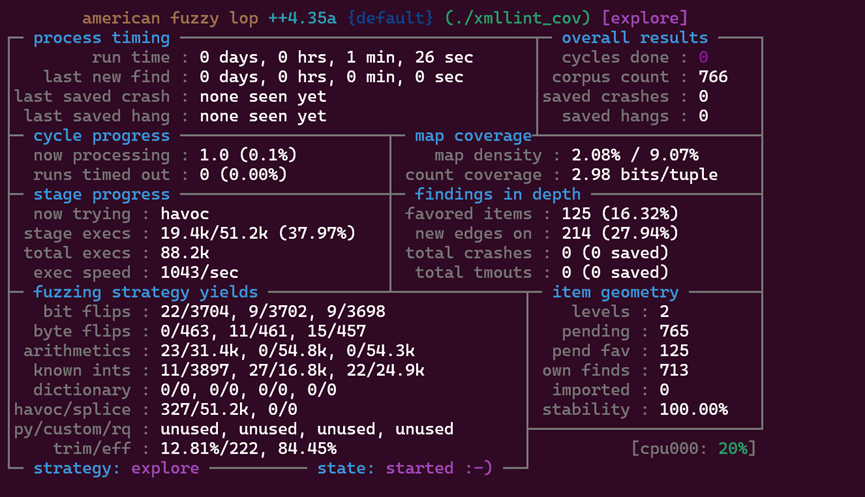
如果想看见明确漏洞结果可以尝试克隆旧版本的libxml2:
git clone https://gitlab.gnome.org/GNOME/libxml2.git libxml2-2.9.0
操作跟上面基本一致
4.结果分析
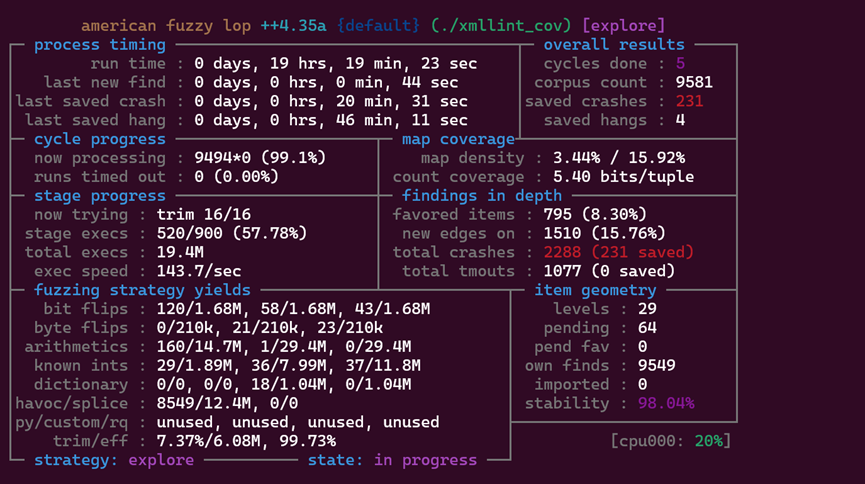
在运行接近20小时后保存了231条crashes,由于可能存在重复的情况,我们可以使用afl_cmin进行去重。
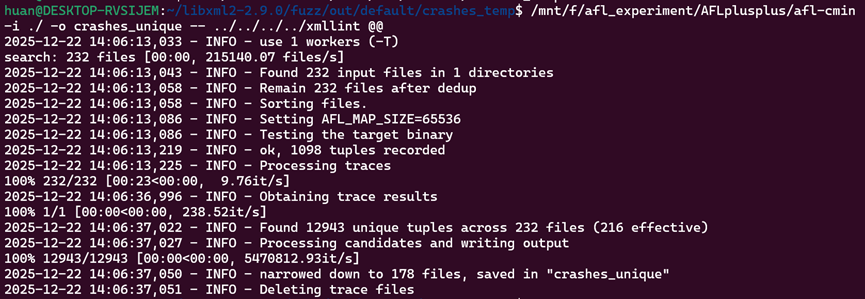
可以初步缩减成178条
之后我们可以对数据进一步处理,了解漏洞触发的类型:

写一个脚本文件:



我运行的结果:

可以发现都是高危的堆缓冲区越界
可以随机选择一个查看:
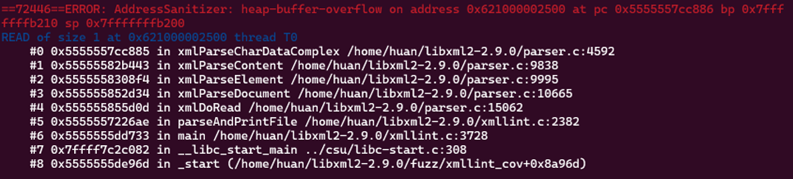
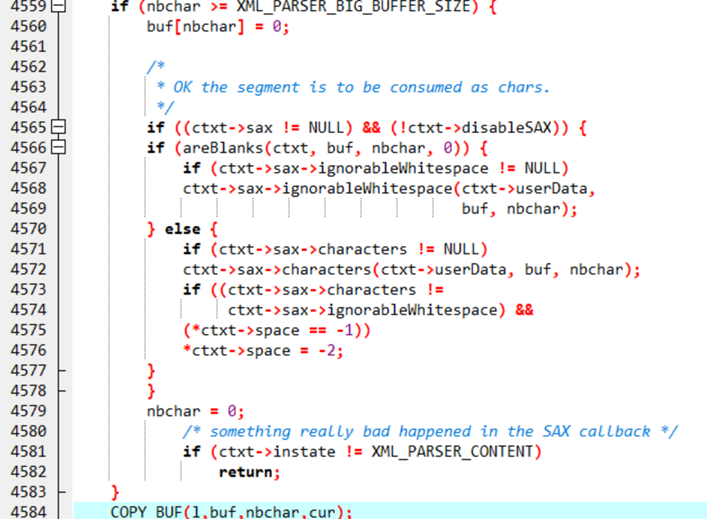
属于读溢出,程序试图读取超过堆缓冲区边界的1个字节数据。发生在parser.c文件的xmlParseCharDataComplex函数中(用于解析XML中的字符数据/文本内容)
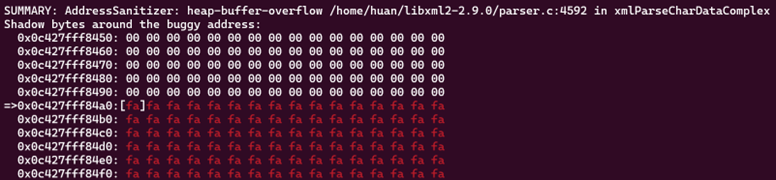
查看源码可以发现:

在处理时while循环并没有对buf进行判断

并且处理逻辑是先进行COPY_BUF再进行校验,故会出现溢出现象。
可以进行修复:
将COPY_BUF操作移动到校验行为以后即可
重新编译make clean && make CC=afl-gcc-fast CXX=afl-g++-fast LD=afl-gcc-fast -j$(nproc)
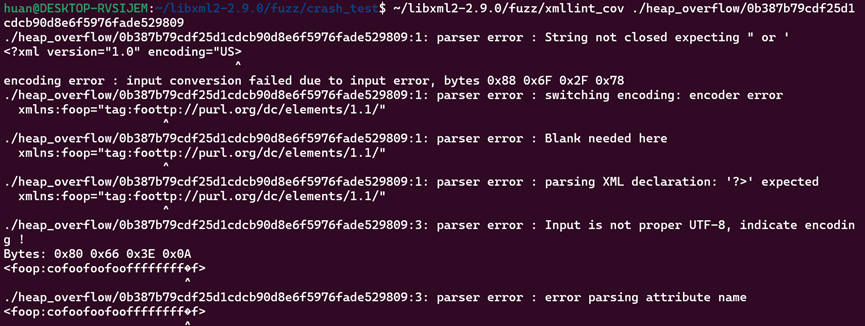
测试刚刚的用例,只出现了语法错误,ASAN的内存漏洞已经完全消失了:

















 551
551

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









